大数据面试精华:Linux+Hadoop技术与高频面试要点
需积分: 18 15 浏览量
更新于2024-07-15
收藏 10.28MB DOCX 举报
本文档是一份针对大数据技术的高频面试题总结,主要涵盖了2020年的热门问题,旨在帮助求职者准备面试。文档详细讲解了以下几个关键知识点:
1. **Linux & Shell相关**:
- Linux常用命令:包括但不限于ls, cd, cp, mv, rm等,这些基础命令在大数据环境中非常重要,因为Hadoop和Spark等大数据平台通常在Linux环境下运行。
- Shell常用工具:awk、sed、cut和sort,这些都是数据处理过程中的实用工具,例如awk用于文本数据分析,sed用于文本流编辑,cut用于分割字符串,sort用于数据排序。
2. **Hadoop技术**:
- 配置文件与端口号:列举了Hadoop组件的关键端口,如NameNode、DataNode、SecondaryNameNode、ResourceManager等,理解这些端口对于集群管理至关重要。
- 配置文件和简单集群搭建:提到了核心配置文件如core-site.xml, hdfs-site.xml, mapred-site.xml, yarn-site.xml等,以及slaves文件和环境变量文件。搭建过程涉及JDK安装、SSH免密登录,以及格式化NameNode等步骤。
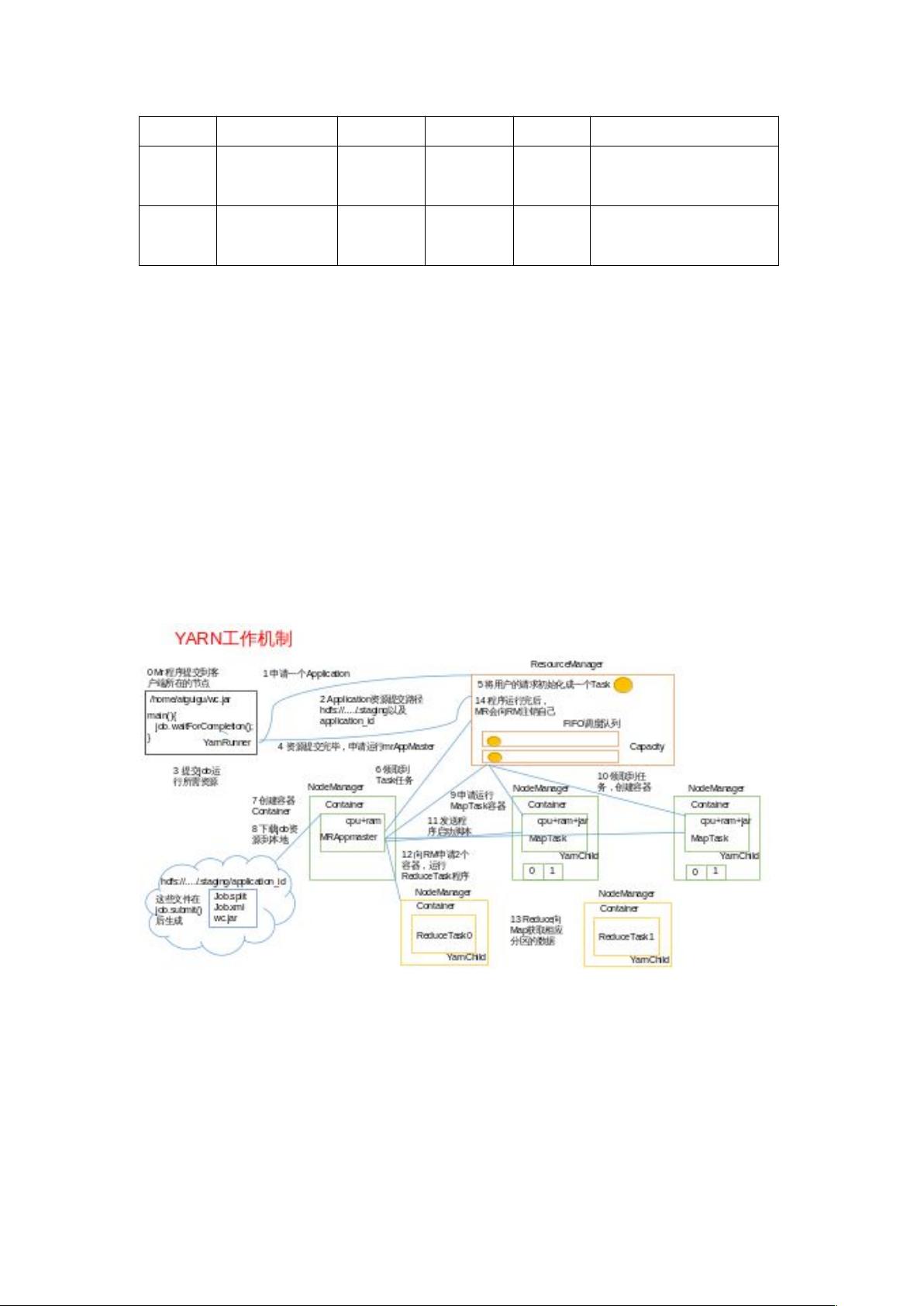
- HDFS读写流程:讲述了Hadoop分布式文件系统(HDFS)的数据读取和写入过程,包括数据分区、环形缓冲区、溢写和排序等细节。
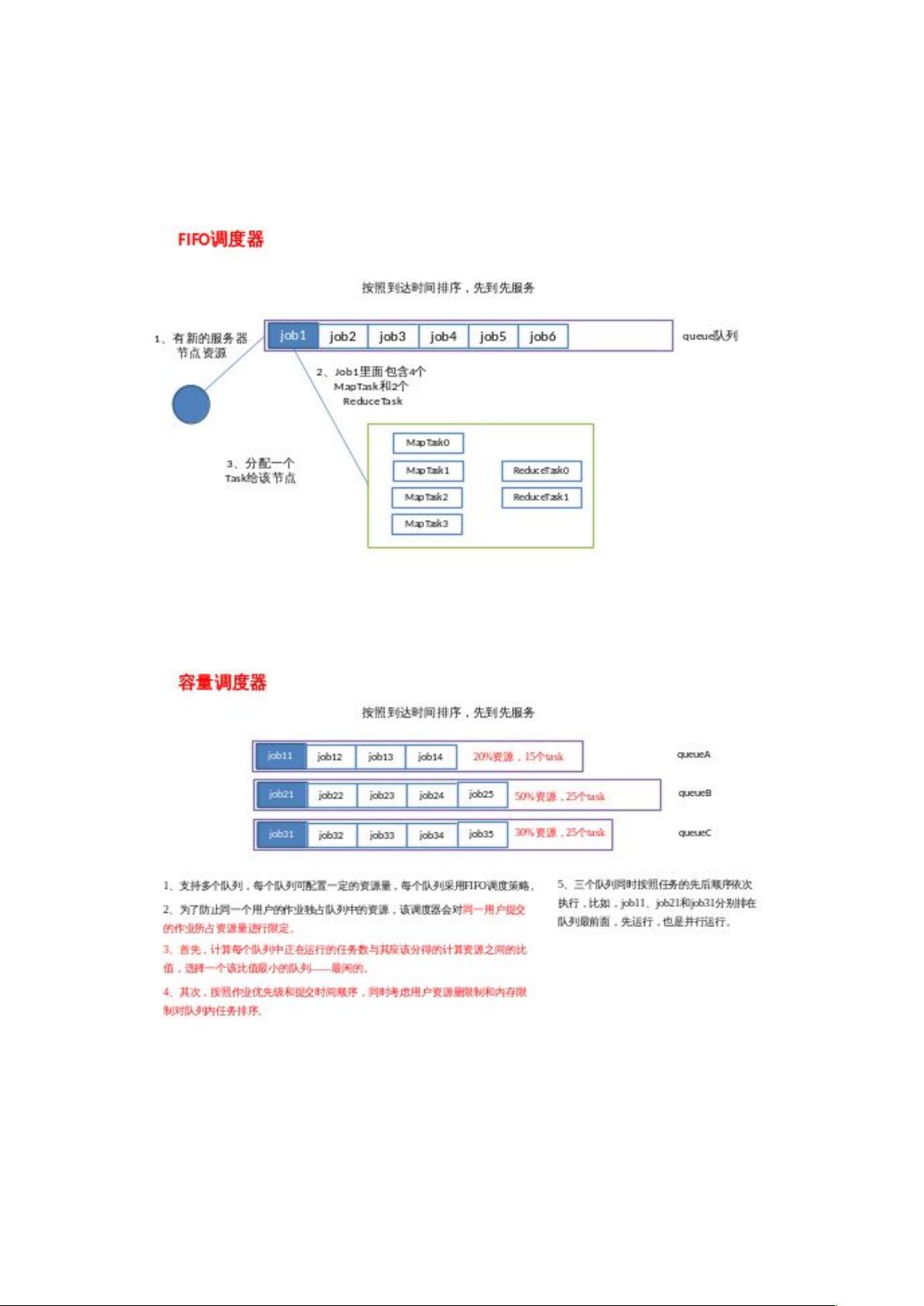
- MapReduce Shuffle过程与优化:解析了MapReduce中的Shuffle阶段,涉及数据分区、内存管理和磁盘操作,以及如何通过压缩、小文件合并、集群优化来提高性能。
3. **Hadoop性能优化**:
- 小文件影响:小文件过多会增加NameNode的压力,并可能导致性能下降。解决策略包括合并小文件、优化文件存储等。
这份文档不仅覆盖了大数据技术的基础概念,还深入到实际应用中的配置和性能调优,是准备大数据岗位面试的重要参考资料。对于求职者来说,理解和掌握这些内容能够提升面试通过率,对于在职人员来说,也可以作为自我提升和技能复习的宝贵资源。

—————————————————————————————
()增大环形缓冲区大小。由 '') 扩大到 '')
()增大环形缓冲区溢写的比例。由 'J扩大到 &'J
()减少对溢写文件的 )!? 次数。(' 个文件,一次 ' 个 )!?)
()不影响实际业务的前提下,采用 -)#! 提前合并,减少 0K%。
) 阶段
()合理设置 和 数:两个都不能设置太少,也不能设置太多。太少,会
导致 ,6( 等待,延长处理时间;太多,会导致 、 任务间竞争资源,造成处理
超时等错误。
()设置 、 共存:调整 676+!+)+)6 参数,使 运行到一定
程度后, 也开始运行,减少 的等待时间。
()规避使用 ,因为 在用于连接数据集的时候将会产生大量的网络消
耗。
()增加每个 去 中拿数据的并行数
()集群性能可以的前提下,增大 端存储数据内存的大小。
)0% 传输
()采用数据压缩的方式,减少网络 0% 的的时间。安装 3 和 $%* 压缩编码器。
()使用 8 二进制文件
)整体
(),6( 默认内存大小为 F,可以增加 ,6( 内存大小为 B?
(),6( 默认内存大小为 F,可以增加 ,6( 内存大小为 B?
()可以增加 ,6( 的 核数,增加 ,6( 的 -*4 核数
()增加每个 -+! 的 -*4 核数和内存大小
()调整每个 ,6( 和 ,6( 最大重试次数
三、压缩
压缩格式 自带? 算法 文件扩展名 支持切分 换成压缩格式后,原来的
程序是否需要修改
>A,>
是,直接使用
>A,> +
否 和文本处理一样,不需要
修改
F<
是,直接使用
>A,> ?<
否 和文本处理一样,不需要
修改
#<
是,直接使用
#< #<
是 和文本处理一样,不需要
'
剩余63页未读,继续阅读
2020-09-11 上传
2020-10-03 上传
2020-09-17 上传
2022-10-28 上传
2021-05-23 上传
2023-07-29 上传
2022-12-24 上传
2021-04-28 上传

史正想
- 粉丝: 1
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







