RAC数据库Hang:异常会话终止与DFSlockhandle事件分析
192 浏览量
更新于2024-08-27
收藏 532KB PDF 举报
在本文中,讨论了一个生产环境中数据库系统遭遇性能瓶颈的问题,表现为数据库反应缓慢,操作无法完成且处于被挂起(hung)状态。问题出现在一个10GRAC环境的三节点数据库中,其中有一个节点的"ActiveSessionsWaiting:Other"等待事件非常高。"ActiveSessionsWaiting:Other"是除了I/O和空闲等待之外所有等待事件的总和,表明系统中有多个非典型等待状况。
通过对9月1日13:00至9月2日12:00期间的AWR报告分析,发现Top5等待事件中有两个属于"Other"类别,即DFSlockhandle和dbfilesequential read。DFSlockhandle事件反映了会话在RAC环境中争夺全局锁句柄时的等待,这是由于DLM(Distributed Lock Manager)的资源不足。在RAC系统中,全局锁资源的数量由隐含参数_lm_locks控制,默认值为12000,可能不足以应对高峰期的并发请求。
另一个主要问题是dbfilesequential read,这属于用户I/O等待,可能是数据文件读取操作的阻塞,也可能是存储或网络I/O瓶颈。这表明数据库查询可能不是最优的,或者数据分布不均可能导致磁盘访问密集。
为了解决这个问题,首先需要识别导致资源紧张的根本原因,可能涉及参数调整、查询优化、索引改进、表设计或者硬件升级。此外,还需要监控其他可能影响性能的参数,如PGA内存分配、进程数量等,并考虑使用AWR报告、诊断视图和SQL Trace来深入了解问题的具体情况。
总结来说,异常终止会话导致的系统hang问题是由过多的"Other"等待事件引发,特别是DFSlockhandle和dbfilesequential read。解决这类问题需要对系统资源管理、数据库调优和并发控制有深入理解,以便找出并针对性地解决瓶颈。
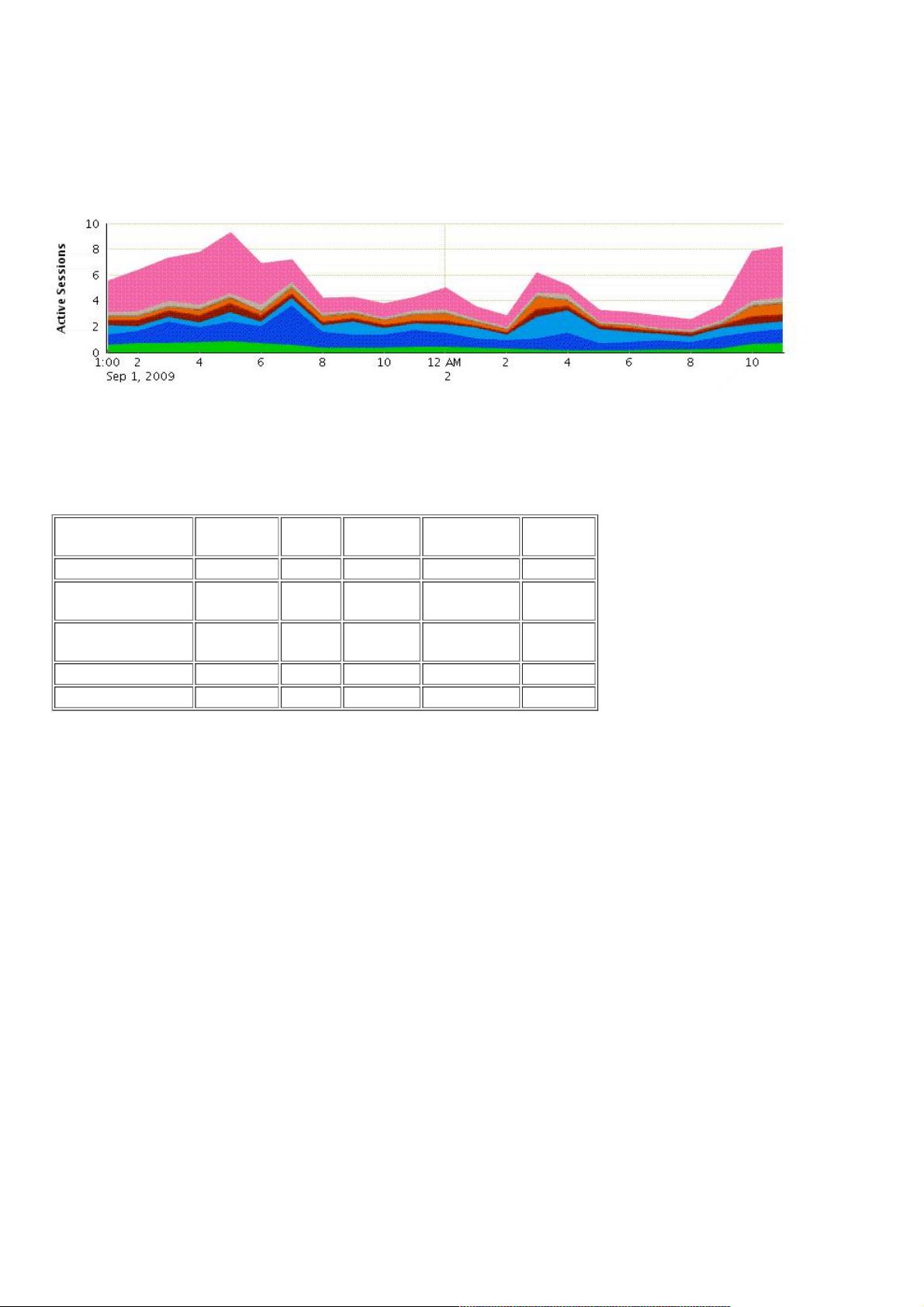
异常终止会话导致系统被异常终止会话导致系统被Hung
问题和现象问题和现象
接到生产支持的同事报告:数据库反应非常慢,很多数据库操作无法完成,DB出在被hung住的状态。同时,他们通过OEM发
现其中一个节点(我们的数据库是10G RAC环境,3个节点)上发现存在很高的“Active Sessions Waiting: Other”的waits,见
下图:
分析分析
"Active Sessions Waiting: Other"这一类的Waits是统计了RAC数据库中除IO和Idle waits之外的所有waits事件,要分析造成这
些waits的原因,我们需要知道具体是那些event导致的waits。由上图中问题出现的时间段,我取了9月1号13:00到9月2号
12:00之间awr report进行进一步分析。从awr report的top events中,得到了有价值的东西:
Event Waits Time(s)
Avg
Wait(ms)
% Total Call
Time
Wait
Class
DFS lock handle 28,784,232 60,662 2 24.9 Other
db file sequential
read
4,877,624 54,104 11 22.2 User I/O
enq: US -
contention
6,488,258 49,231 8 20.2 Other
CPU time 37,748 15.5
log file sync 1,982,632 16,373 8 6.7 Commit
我们可以看到,Top 5 events中,有2个events是属于Other的,也就是说,这2个event是导致系统"Active Sessions Waiting:
Other"异常的根本原因。我们再具体分析这2个events。
"DFS lock handle"这一event是在RAC环境中,会话等待获取一个全局锁的句柄时产生的。在RAC中,全局锁的句柄是由
DLM(Distributed Lock Manager 分布式锁管理器)所管理和分配的。大量发生这一event说明全局锁句柄资源不够分配了。
决定DLM锁数量的参数是_lm_locks,9i以后,它是一个隐含参数,默认值是12000。没有特殊情况,这一值对于一个OLTP系
统来说是足够的。我们不能盲目地直接增加资源,而是需要找到导致资源紧张的根本原因。锁资源紧张,说明存在大量事务获
取了锁,但是事务没有提交、回滚。那么,又是什么导致了这些事务不结束呢?应用程序代码不完善,没有提交事务?或者那
些事务还在等待别的资源?分析到此,我们暂时先放下这一event,看下top event中的另外一个异常event。
"enq: US - contention",这个event说明事务在队列中等待UNDO Segment,通常是由于UNDO空间不足导致的。结合对前一
event的分析,初步判断正是因为大量事务在等待队列中等待UNDO资源,导致全局锁没有释放。为了验证这一判断,我分别
查询发生这2个events的对象是那些。先看"DFS lock handle"的wait对象:
下载后可阅读完整内容,剩余3页未读,立即下载
2010-06-30 上传
2021-09-29 上传
2021-09-30 上传
2021-10-18 上传
2021-10-03 上传
2021-03-27 上传
2021-05-29 上传
2021-03-31 上传
2022-09-21 上传

weixin_38672840
- 粉丝: 9
- 资源: 893
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
