Android实现简易网络爬虫教程
37 浏览量
更新于2024-09-01
收藏 294KB PDF 举报
"本文介绍了在Android平台上编写简单网络爬虫的基础知识和实现步骤,包括网络爬虫的基本概念、遍历策略以及一个简单的Android网络爬虫demo的实现过程。"
网络爬虫,也称为Web爬虫,是搜索引擎抓取互联网内容的关键组件。它们自动地遍历网页,收集并存储网页信息,以便于搜索引擎对网页内容进行索引和搜索。在Android平台开发网络爬虫,主要涉及到网络请求、数据解析和UI显示等技术。
一、网络爬虫的基本知识
网络爬虫的工作原理可以抽象为图的遍历。互联网的各个网页被视为图中的节点,而网页之间的链接则为有向边。常见的遍历策略有宽度优先遍历(Breadth-First Search, BFS)和深度优先遍历(Depth-First Search, DFS)。在实际应用中,由于DFS可能导致过深的遍历或陷入无限循环,大多数爬虫倾向于使用BFS。此外,爬虫通常会设置一个visited表来跟踪已访问过的页面,避免重复抓取。
开始时,爬虫会从一组预定义的种子链接开始,这些链接是爬取的起点。种子页面的超链接指向的页面作为中间节点,继续被爬取。对于非HTML文档,由于无法提取超链接,通常被视为图的终端节点。
二、Android网络爬虫的简单实现
在Android中实现网络爬虫,主要涉及以下几个关键部分:
1. `MainActivity`: 这是应用程序的主入口,负责初始化UI和设置界面布局。
2. `MainAdapter`: 用于适配ListView,展示爬取到的数据,如新闻标题和URL。
3. `NetWorkClass`: 负责与服务器进行通信,通常使用`HttpClient`或者`OkHttp`等库发送HTTP请求,接收响应内容,即网页的HTML代码。
4. 解析HTML代码:通常需要使用如Jsoup这样的库来解析HTML,提取所需信息,如新闻标题和链接。
5. `News`类:存储新闻的标题和对应的URL。
6. `NewsActivity`: 显示新闻详情的Activity,当用户点击列表项时跳转至此。
7. `PullListView`: 重写的ListView,增加了下拉刷新和上拉加载更多功能,以实现动态加载更多的新闻。
在`onCreate()`方法中,通常会进行UI的初始化,设置监听器,并启动主线程(如`MainThread`)来执行网络请求任务。主线程会调用`NetWorkClass`来获取网页内容,然后解析HTML,将结果传递给适配器更新ListView显示。
在实际的Android网络爬虫开发中,还需要考虑以下几点:
- 异步处理:网络请求应在后台线程中进行,以避免阻塞UI线程。
- 数据持久化:爬取的数据可以存储在SQLite数据库或文件系统中,便于离线访问。
- 合法性和效率:遵守网站的robots.txt协议,避免对目标网站造成过大负担,同时控制爬取速度。
- 错误处理:包括网络错误、解析错误等,确保程序的健壮性。
总结,Android编写网络爬虫涉及到网络请求、HTML解析、UI设计等多个环节,需要结合Android平台特性,合理利用相关库和工具,以实现高效、稳定且用户体验良好的网络爬虫应用。
Android编写简单的网络爬虫编写简单的网络爬虫
网络爬虫是捜索引擎抓取系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份。本文的主要内容是讲在Android中如何编
写简单的网络爬虫。
一、网络爬虫的基本知识一、网络爬虫的基本知识
网络爬虫通过遍历互联网络,把网络中的相关网页全部抓取过来,这体现了爬的概念。爬虫如何遍历网络呢,互联网可以看做是一张大图,每个页面看做其中的一个节点,页面的连接看做是有
向边。图的遍历方式分为宽度遍历和深度遍历,但是深度遍历可能会在深度上过深的遍历或者陷入黑洞。所以,大多数爬虫不采用这种形式。另一方面,爬虫在按照宽度优先遍历的方式时候,
会给待遍历的网页赋予一定优先级,这种叫做带偏好的遍历。
实际的爬虫是从一系列的种子链接开始。种子链接是起始节点,种子页面的超链接指向的页面是子节点(中间节点),对于非html文档,如excel等,不能从中提取超链接,看做图的终端节点。
整个遍历过程中维护一张visited表,记录哪些节点(链接)已经处理过了,跳过不作处理。
二、二、Android网络爬虫网络爬虫demo的简单实现的简单实现
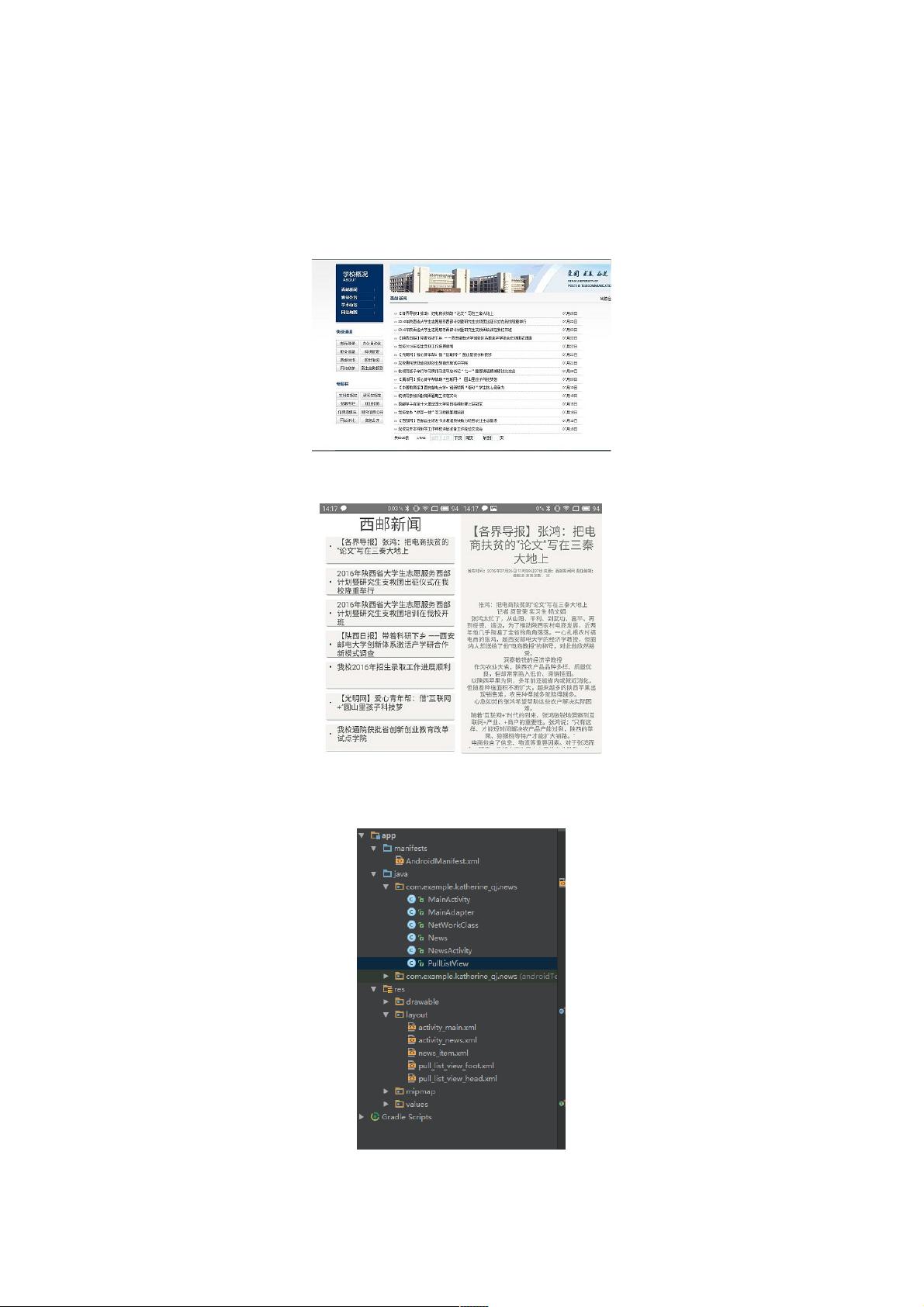
看一下效果
抓的是这个网页 然后写了一个APP
是这样的
把listview做成卡片式的了 然后配色弄的也很有纸质感啊啊啊
反正自己还挺喜欢的
然后就看看是怎么弄的
看一下每个类都是干啥的 :
MainActivity:主界面的Activity
MainAdapter::listview的适配器
NetWorkClass::链接网络 使用HttpClient发送请求、接收响应得到content 大概就是拿到了这个网页的什么鬼东西
还有好多就是一个html的代码 要解析这个
下载后可阅读完整内容,剩余3页未读,立即下载
615 浏览量
389 浏览量
2024-04-08 上传
300 浏览量
2016-08-12 上传
122 浏览量
101 浏览量
124 浏览量
231 浏览量

weixin_38597970
- 粉丝: 4
- 资源: 919
 我的内容管理
展开
我的内容管理
展开







最新资源
- 微信小程序-点餐
- ionicStudyWithTabs:带有 ngCordova 的离子模板项目
- note-taker
- XIANDUAN.rar
- 一种基于高通量测序的拷贝数变异检测自动化分析解读及报告系统.rar
- rasaxproject1
- GitHub Open All Notifications-crx插件
- gatsby-remark-component-images:一个Gatsby注释插件,将gatsby-plugin-sharp处理应用于html样式的markdown标签
- 易语言开关音频服务实现开关声音-易语言
- ComposeKmmMoviesApp
- HistogramComponentDemo.7z
- UA GPU-able Search-crx插件
- MYSQL数据库管理器(易语言2005年大赛三等奖)2010-10-27.rar
- native-api-notification-[removed]JavaScript中的本机通知API
- 将超像素作为输入MATLAB代码-laplacianseg:种子图像分割的拉普拉斯坐标
- MyDroid
