深入理解Lucene:源码解析与索引结构探秘
需积分: 50 155 浏览量
更新于2024-07-26
收藏 2.73MB PDF 举报
"Lucene源代码剖析"
Lucene是一款开源的全文搜索引擎库,它提供了一个高效、灵活的文本搜索框架,广泛应用于各种系统中。本文档深入解析了Lucene的源代码,适合对Lucene感兴趣的初学者进行学习。
**2.Lucene是什么**
Lucene的核心特性包括:
2.1.1 强大特性:支持分词、高亮显示搜索结果、布尔查询、短语查询、近似搜索、评分机制等。
2.1.2 API组成:包括分析(Analyzer)、索引(Index)、搜索(Search)、存储(Store)等模块,以及用于组合和定制这些功能的工具类。
2.1.3 HelloWorld!:简单的Lucene应用通常从创建索引、添加文档、搜索索引开始,展示其基本用法。
2.1.4 Lucene roadmap:Lucene的发展路线图,展示了未来版本的改进和新特性。
**3. 索引文件结构**
3.1 索引数据术语和约定:
3.1.1 术语定义:如文档(Document)、字段(Field)、术语(Term)等是理解Lucene索引的基础。
3.1.2 倒排索引:是Lucene实现快速搜索的关键,将文档中的词汇映射到包含这些词汇的文档列表。
3.1.3 Fields的种类:根据不同的需求,字段可以设置为可搜索、可存储、可索引等不同属性。
3.1.4 片段:索引数据的基本单元,由多个文档组成。
3.1.5 文档编号:每个文档在索引中的唯一标识。
3.1.6 索引结构概述:包括段(Segment)、术语字典、频率数据、位置信息等。
3.1.7 索引文件中定义的数据类型:如文档编号、频率、位置等,都有特定的二进制表示。
3.2 索引文件结构详解:
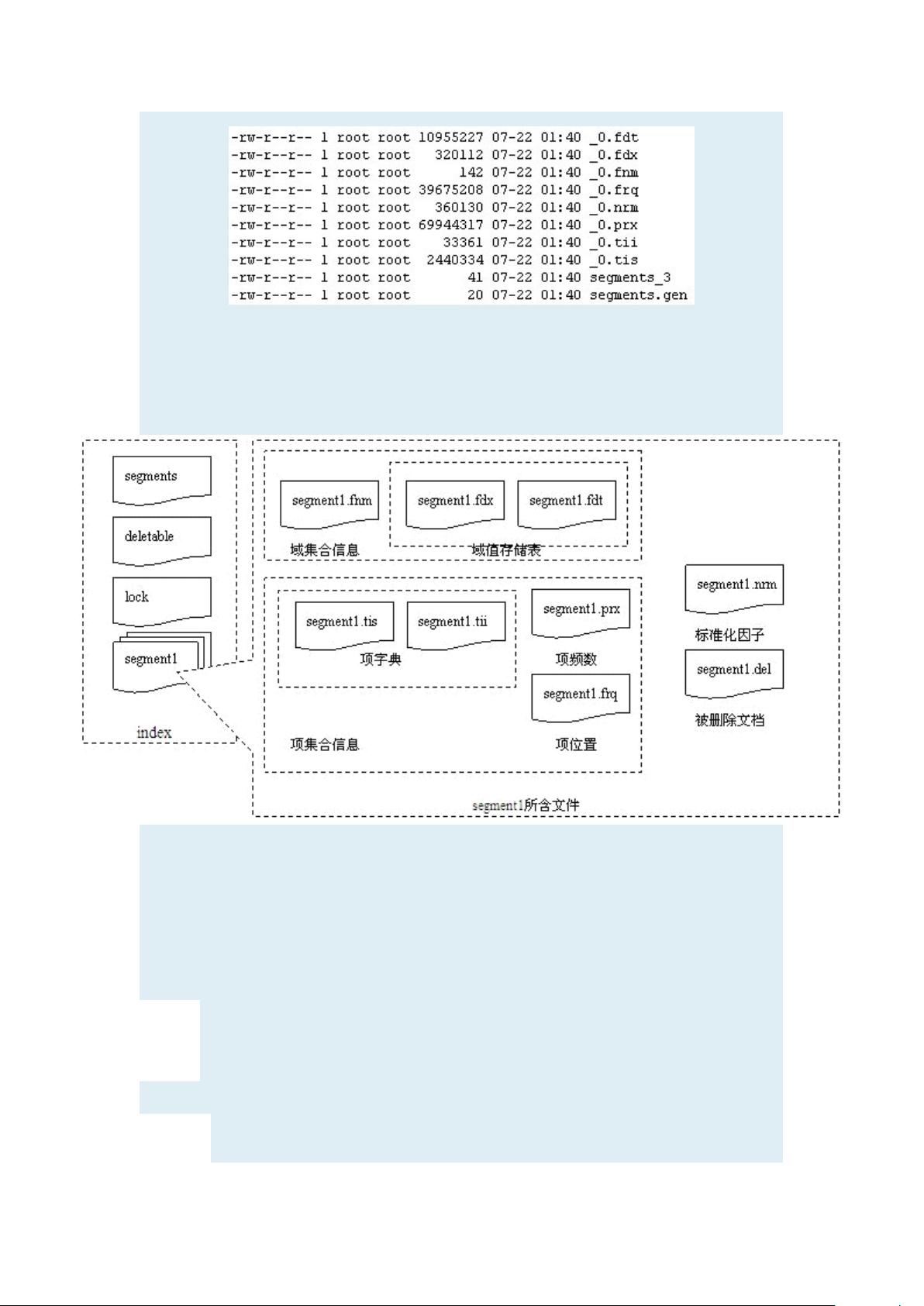
3.2.1 索引文件概述:索引由多个文件组成,包括段信息、锁文件、删除文件等。
3.2.2 每个Index包含的文件:如Segments文件记录段信息,Lock文件用于并发控制,Deletable文件标记已删除的文档等。
3.2.2.1 Segments文件:描述了索引中的所有段及其属性。
3.2.2.2 Lock文件:确保同一时间只有一个进程写入索引。
3.2.2.3 Deletable文件:记录已删除的文档信息。
3.2.2.4 Compound文件(.cfs):为了减少磁盘I/O,将多个小文件合并成一个大文件存储。
3.2.3 每个Segment包含的文件:如Field信息文件、Field数据文件、Term字典等。
3.2.3.1 Field信息(.fnm):存储字段名称和类型信息。
3.2.3.2 Field数据(.fdx和.fdt):索引字段的偏移量和实际数据。
3.2.3.3 Term字典(.tii和.tis):提供了术语到文档编号的快速查找。
3.2.3.4 Term频率数据(.frq):记录每个术语在文档中的出现次数。
3.2.3.5 Positions信息数据(.prx):存储术语的位置信息,支持短语查询。
3.2.3.6 Norms调节因子文件(.nrm):存储每个字段的长度规范化信息。
3.2.3.7 Term向量文件:存储每个术语的词频和位置信息,用于更复杂的检索策略。
3.2.3.8 删除的文档(.del):标记被删除的文档。
**4. 索引是如何创建的**
4.1 索引创建示例:通过调用`IndexWriter`类来添加文档并构建索引。
4.2 索引创建类`IndexWriter`:
4.2.1 `org.apache.lucene.index.IndexWriter`:是创建和更新索引的主要接口,负责索引的合并、优化和删除操作。
4.2.2 `org.apache.lucene.index.DocumentsWriter`:`IndexWriter`的内部工作horse,负责文档的物理写入。
4.2.3 `org.apache.lucene.index.SegmentMerger`:在索引过程中,将多个段合并成一个更大的段。
**5. 数据是如何存储的**
5.1 数据存储类`Directory`:
5.1.1 `org.apache.lucene.store.Directory`:是Lucene中存储索引数据的抽象接口,支持不同的存储实现。
5.1.2 `org.apache.lucene.store.FSDirectory`:基于文件系统的目录实现,将索引文件存储在磁盘上。
5.1.3 `org.apache.lucene.store.RAMDirectory`:内存中的目录实现,适用于测试和小型索引。
5.1.4 `org.apache.lucene.store.IndexInput`:读取索引数据的输入流。
5.1.5 `org.apache.lucene.store.IndexOutput`:写入索引数据的输出流。
**6. 文档查询与搜索过程**:Lucene的搜索过程涉及查询解析、查询执行、评分和排序,这部分未在摘要中详细展开,但也是理解Lucene的重要部分。
**7. 局限性**:尽管Lucene功能强大,但也有其局限,如不支持实时更新、不直接支持分布式搜索等。
通过深入学习和理解Lucene的源代码,开发者能够更好地利用其特性,优化搜索性能,甚至为Lucene贡献代码,推动其持续发展。

档所返回的( returned )信息。这些是通过文档编号( document number )来做为 key 得 到
的。
3 Term
Term
Term
Term 字典( dictionary
dictionary
dictionary
dictionary ): 一个包含( contains )所有 terms 的字典,被使用在所有 文
档中所有被索引的 fields 中。它还包含了该 term 所在的文档的数目( the number of
documents which contains the term
),并且指向了(
pointer to
)
term 的频率( frequenc y
)
和接近度( proximity )的数据( data )。
4 Term
Term
Term
Term 频率数据( frequency
frequency
frequency
frequency data
data
data
data ): 对字典中的每一个 term 来说,所有包含该 ter m
( contains the term )的文档的编号( numbers of
all
documents ),以及该 term 出现在 该
文档中的频率( frequency )。
5 Term
Term
Term
Term 接近度数据( proximity
proximity
proximity
proximity data
data
data
data ): 对字典中的每一个 term 来说,该 term 出现 在
( occur )每一篇文档中的位置( positions )。
6 调整因子( normalization
normalization
normalization
normalization factors
factors
factors
factors ): 对每一篇文档的每一个 field 来说,为一个存储
的值 (
a value is stored
) 用来加入到 (
multiply into
) 命中该
field
的分数 (
score for hits on that
field )中。
7 Term
Term
Term
Term 向量( vectors
vectors
vectors
vectors ): 对每一篇文档的每一个 field 来说, term 向量(有时候被称 做
文档向量) 可以被存储。 一个
term 向量由 term 文本和 term
的频率 (
frequency
) 组成 (
c
onsists
of )。怎么添加 term 向量到你的索引中请参考 Field 类的构造方法( constructors )。
8 删除的文档( deleted
deleted
deleted
deleted documents
documents
documents
documents ): 一个可选的( optional )文件标示( indicating
)
哪一篇文档被删除。
关于这些项的详细信息在随后的章节( subsequent sections )中逐一介绍。
2.1.7
2.1.7
2.1.7
2.1.7 索引文件中定义的数据类型
数据类型
所占字节长度(字
节)
说明

剩余72页未读,继续阅读
819 浏览量
2012-12-17 上传
2011-06-09 上传
2023-06-01 上传
2023-04-26 上传
2024-09-27 上传
2024-05-26 上传
2023-05-30 上传
2023-07-12 上传

monoid0805
- 粉丝: 2
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
