集群服务:大数据流框架上的AI模型分布式推理实践
版权申诉
98 浏览量
更新于2024-07-05
收藏 2MB PDF 举报
“集群服务:大数据流框架上的分布式自动模型推理.pdf”主要探讨了在大数据流框架上实现分布式自动模型推理的挑战与解决方案,涉及到的技术包括分布式系统、Zookeeper以及云原生环境。文档中提到了集成大数据分析和人工智能生产管道的重要性,并引用了Andrew Ng的“Machine Learning Yearning”以及Sculley等人在Google的NIPS 2015论文“Hidden Technical Debt in Machine Learning Systems”。
在大数据流处理领域,Flink等框架被广泛用于实现实时数据的高效处理。这篇报告指出,AI生产面临的首要挑战是可扩展的在线服务,这需要解决模型的高性能需求以及与大数据处理的集成。分布式模型推理是应对这一挑战的有效手段,它能够利用多节点并行计算能力提高服务的响应速度和处理能力。
Zookeeper作为一个分布式协调服务,被用于管理集群中的配置信息、命名服务、集群同步以及组服务等,对于实现分布式模型推理至关重要。在云原生环境中,服务必须具备高度的弹性和可移植性,这通常通过容器化(如Docker)和编排工具(如Kubernetes)来实现。
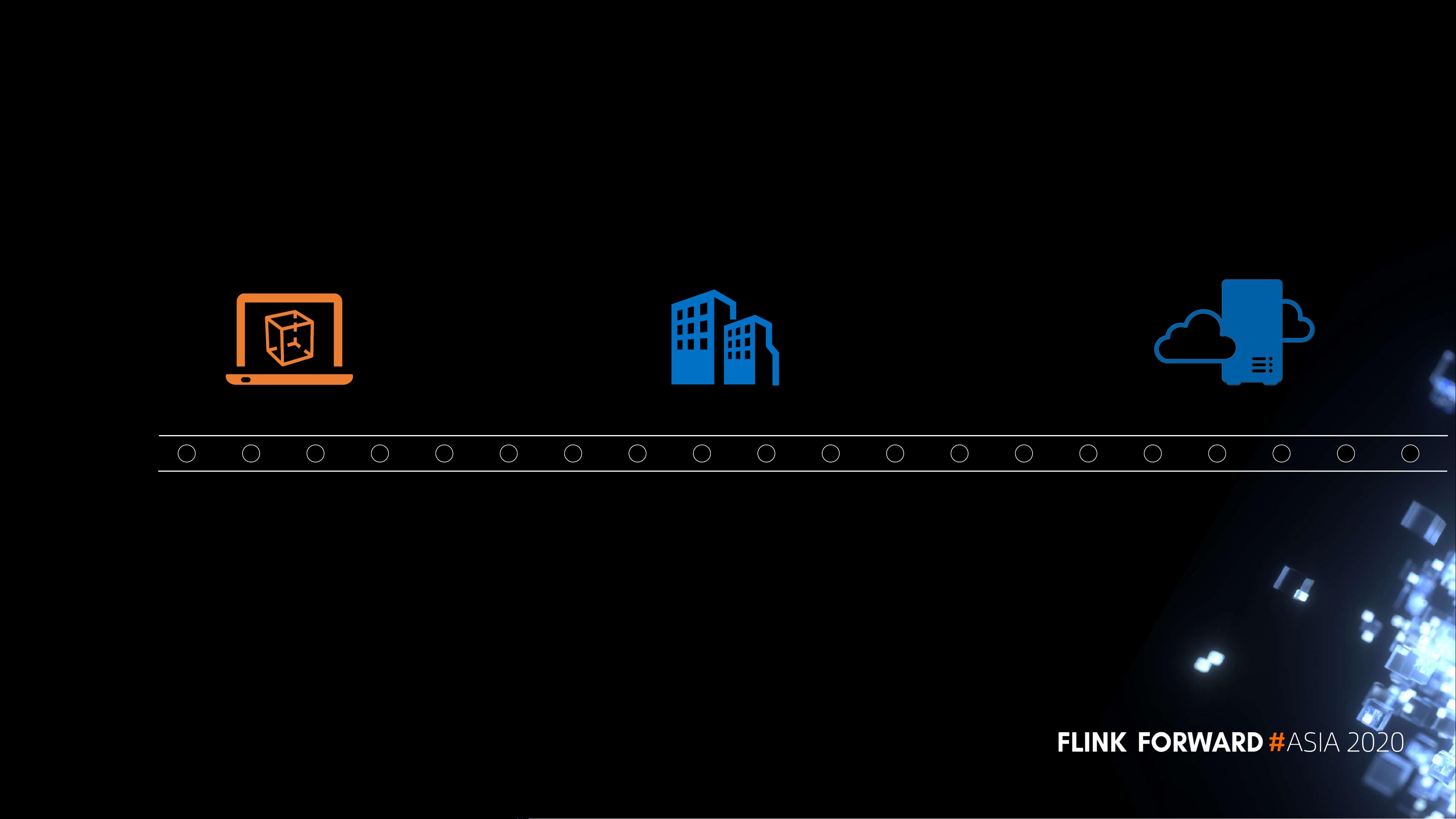
报告中提到了从原型到生产的流程,即在笔记本电脑上使用样本数据进行初步的数据管道构建,然后在集群上用历史数据进行实验验证,最后进行生产部署。这个过程反映了从开发到上线的完整生命周期,强调了实际应用中的复杂性。
集成的大数据与AI管道旨在简化这一流程,将数据处理和模型推理紧密结合起来,形成一个端到端的解决方案。这不仅可以提升效率,还能减少技术债务,确保模型在面对不断变化的数据和业务需求时能快速适应和更新。
该文档提供了关于如何在大数据流框架上实现分布式自动模型推理的深入见解,涵盖了从理论到实践的关键技术和挑战,对于理解和优化AI在大数据环境下的应用具有很高的参考价值。

2022精品解决方案/精品实践方案/精选研究报告
Integrated Big Data and AI pipeline
#2
剩余32页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-08-09 上传
2021-08-11 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

Build前沿
- 粉丝: 1064
- 资源: 2233
 我的内容管理
展开
我的内容管理
展开







最新资源
- 应用数据科学峰会第5周
- xml2ddl:隐秘xml到ddl文件
- Dipterv_KNX:他正在康复
- 企业手机微网站模板
- 电信设备-基于相似度的多模态信息分类贡献差异性计算方法.zip
- piero:节点事件管理包
- SALIENT-EDGE-S-and-REGION-S-EXTRACTIONFOR-RGBD-IMAGES
- c是最好的编程语言之C语言实现的数独游戏.zip
- 神经网络算法:神经网络算法(包括BP,SOM,RBF)
- naive-bayes-author-email:电子邮件作者的机器学习
- Mochila_De_Mollein_M_Florencia:Cursada de“Introduccióna laInformática”(认证技术开发人员)
- rf:Go的重构工具
- onkormanyzati-adatbazis-parser:töosz.huönkormányzatiadatbázisadatoksajátadatbázisbamentéséreszántkód
- 焊缝检测PLC程序.rar
- shark_tooth_data_collector:使用OpenCV进行鲨鱼牙齿的圆形测量
- 易语言-新浪微博登录发微博
