DeepThings:物联网边缘动态环境下分布式自适应深度学习推理框架
需积分: 0 196 浏览量
更新于2024-08-05
收藏 2.39MB PDF 举报
在物联网(IoT)边缘计算日益受到重视的背景下,如何在资源受限的设备集群中高效、灵活地部署深度学习(Deep Learning)模型,尤其是卷积神经网络(Convolutional Neural Networks, CNNs),已成为一个关键挑战。本文《DeepThings:资源受限IoT边缘集群中的分布式自适应深度学习推理》发表在2018年11月的IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems上,由作者Zhuoran Zhao、Kamyar Mirzazadeh Barijough和Andreas Gerstlauer提出。
传统的深度学习部署方法往往难以在保持准确性的同时满足IoT设备的资源限制,特别是当数据源具有动态性时,静态的部署策略无法适应这种变化。为解决这一问题,DeepThings框架应运而生。该框架专注于在资源极其有限的IoT边缘设备集群中,实现CNN基础的推理应用的分布式、自适应执行。
DeepThings的核心贡献是提出了一种可扩展的融合块分区(Fused Tile Partitioning, FTP)方法,用于对CNN的卷积层进行分解和优化。FTP旨在在保持模型性能的同时,根据实时环境和资源可用性动态调整计算任务的分配。通过这种动态分区策略,DeepThings能够在设备之间动态平衡负载,提高整体系统的效率和响应能力,同时考虑到硬件资源和能量消耗的限制。
此外,该框架还着重于适应性,能够根据输入数据的特征和变化动态调整模型的复杂度,从而在处理实时数据流时展现出更高的灵活性。这使得DeepThings在资源受限的环境中展现出更好的性能,提升了IoT边缘设备在诸如图像识别、语音识别等应用中的处理能力,同时兼顾了隐私保护和数据处理的效率。
总结来说,DeepThings是一项创新的工作,它针对IoT边缘设备的特性,提出了一个分布式、自适应的深度学习推理解决方案,旨在解决资源有限的环境下的性能与效率问题,对于推动边缘计算在物联网中的广泛应用具有重要意义。
2350 IEEE TRANSACTIONS ON COMPUTER-AIDED DESIGN OF INTEGRATED CIRCUITS AND SYSTEMS, VOL. 37, NO. 11, NOVEMBER 2018
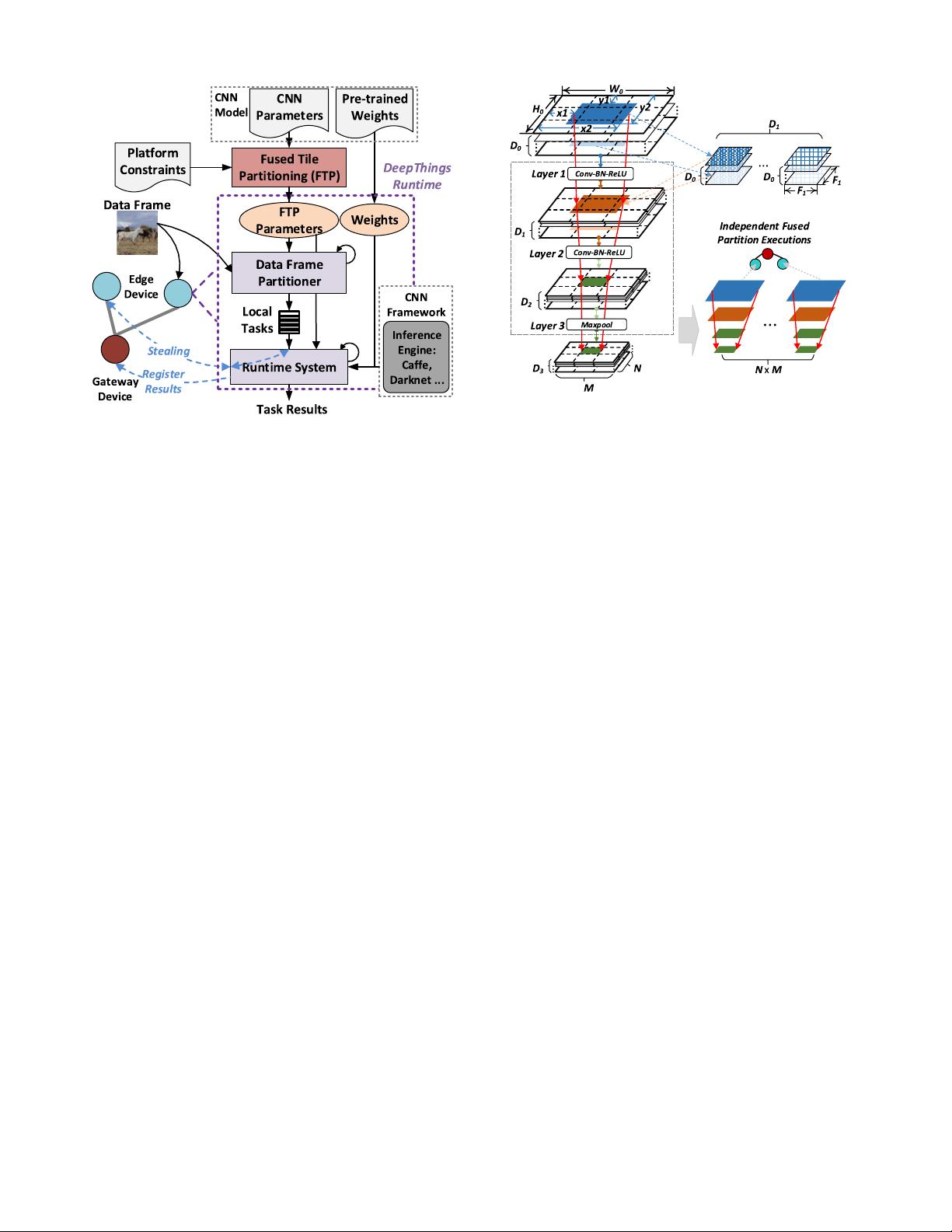
Fig. 3. Overview of the DeepThings framework.
between edge and gateway devices. However, this straightfor-
ward approach cannot explore the inference parallelism within
one data frame, and significant computation is still happening
in each layer. Apart from the long computation time, early
convolutional layers also leave a large memory footprint, as
shown by memory profiling results in Fig. 2. Taking the first
16 layers in You Only Look Once, version 2 (YOLOv2) as an
example, the maximum memory footprint for layer execution
can be as large as 70 MB, where the input and output data
contribute more than 90% of the total memory consumption.
Such large memory footprint prohibits the deployment of CNN
inference layers directly on resource-constrained IoT edge
devices.
In this paper, we focus on partition and distribution meth-
ods that enable execution of early stage convolutional layers
on IoT edge clusters with lightweight memory footprint. The
key idea is to slice original CNN layer stacks into indepen-
dently distributable execution units, each with smaller memory
footprint and maximal memory reuse within each IoT device.
With these small partitions, DeepThings will then dynami-
cally balance the workload among edge clusters to enable
efficient locally distributed CNN inference under time-varying
processing needs.
IV. D
EEPTHINGS FRAMEWORK
An overview of the DeepThings framework is shown in
Fig. 3. In general, DeepThings includes an offline CNN
partitioning step and an online executable to enable dis-
tributed adaptive CNN inference under dynamic IoT appli-
cation environments. Before execution, DeepThings takes
structural parameters of the original CNN model as input
and feeds them into an Fused Tile Partitioning (FTP). Based
on resource constraints of edge devices, a proper offloading
point between gateway/edge nodes and partitioning parameters
are generated in a one-time offline process. FTP parame-
ters together with model weights are then downloaded into
Fig. 4. Fused Tile Partitioning for CNN.
each edge device. For inference, a DeepThings runtime is
instantiated in each IoT device to manage task computa-
tion, distribution, and data communication. Its Data Frame
Partitioner will partition any incoming data frames from local
data sources into distributable and lightweight inference tasks
according to the precomputed FTP parameters. The Runtime
System in turn loads the pretrained weights and invokes an
externally linked CNN inference engine to process the parti-
tioned inference tasks. In the process, the Runtime System will
register itself with the gateway device, which centrally moni-
tors and coordinates work distribution and stealing. If its task
queue runs empty, an IoT edge node will poll the gateway
for devices with active work items and start stealing tasks
by directly communicating with other DeepThings runtimes
in a peer-to-peer fashion. Finally, after edge devices have fin-
ished processing all tasks for a given data source associated
with one of the devices, the gateway will collect and merge
partition results from different devices and finish the remain-
ing offloaded inference layers. A key aspect of DeepThings
is that it is designed to be independent of and general in
supporting arbitrary pretrained models and external inference
engines.
A. Fused Tile Partitioning
Fig. 4 illustrates our FTP partitioning on a typical exam-
ple of a CNN inference flow. In DNN architectures, multiple
convolutional and pooling layers are usually stacked together
to gradually extract hidden features from input data. In a
CNN with L layers, for each convolutional operation in layer
l = 1 ···L with input dimensions W
l−1
× H
l−1
,asetofD
l
learnable filters with dimensions F
l
× F
l
× D
l−1
are used to
slide across D
l−1
input feature maps with a stride of S
l
.Inthe
process, dot products of the filter sets and corresponding input
region are computed to generate D
l
output feature maps with
dimensions W
l
× H
l
, which in turn form the input maps for
layer l + 1. Note that in such convolutional chains of DNNs,
the depth of intermediate feature maps (D
l
) are usually very
剩余11页未读,继续阅读
2024-04-10 上传
2020-08-31 上传
2024-05-14 上传
2024-07-04 上传
2023-05-31 上传
2023-03-26 上传
2023-03-26 上传
2023-06-06 上传
2023-05-12 上传

老许的花开
- 粉丝: 34
- 资源: 328
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于RGB空间的彩色图像处理GUI设计.pdf
- RapidWebSpherePortletFactory
- 物流信息系统的设计与实现
- 高速串行背板总线的仿真设计
- ssh框架集成的详细说明
- 基于模糊神经网络的多传感器自适应
- 模糊神经网络信息融合在移动机器人的应用
- FIFO算法的c++实现
- 运筹案例分析详细车车
- 二叉树的遍历代码(递归)
- VB与单片机之间通信-RS232
- 让CPU占用率曲线听你指挥
- 用c++解决饮料供货的问题
- 《ajax框架:dwr与ext》实战
- pci_cust_tutorial.pdf
- O' Reilly - Practical C Programming 3rd Edition
