使用KSQL简化Apache Kafka的流处理操作
95 浏览量
更新于2024-08-27
收藏 236KB PDF 举报
"使用ApacheKafka和KSQL实现普及化流处理"
Apache Kafka是一个分布式流处理平台,被广泛用于构建实时数据管道和流应用程序。它的核心功能是作为一个高吞吐量、低延迟的消息队列,允许应用程序高效地发布和订阅多主题的数据流。KSQL是建立在Kafka之上的数据流SQL引擎,它极大地简化了流处理,使得开发人员可以通过SQL语句而不是复杂的编程来执行实时数据分析。
KSQL的关键特性包括:
1. **SQL接口**:KSQL引入了SQL,使得熟悉关系数据库的开发者能够轻松地理解和操作流数据。这降低了学习曲线,提高了开发效率。
2. **流处理操作**:KSQL支持多种流处理操作,如过滤(Filter)、转换(Transform)、聚合(Aggregate)、连接(Join)、窗口(Windowing)以及会话化(Sessionization)。这些操作使得用户可以方便地处理实时数据流,进行实时分析。
3. **动态更新**:KSQL的查询是动态的,这意味着当数据发生变化时,查询结果会自动更新,无需重新启动查询。
4. **轻量级部署**:由于KSQL是构建在Kafka Stream API之上,它不需要额外的运行时环境,可以直接在现有的Kafka集群上运行,降低了资源消耗。
5. **实时应用**:KSQL的实时处理能力使其适用于各种应用场景,如实时报表和仪表板、基础设施监控、物联网(IoT)数据处理、异常检测和欺诈行为识别等。
6. **扩展性**:Kafka和KSQL的设计使得系统可水平扩展,能够处理海量数据流。
在上述客户档案创建和维护的案例中,Kafka和KSQL可以接收来自多个来源的数据流,如交易系统、位置服务、社交媒体等,实时地整合这些信息,构建出客户的实时视图。当有新数据到来时,KSQL会自动更新档案,从而及时响应异常情况,如潜在的欺诈交易,或提供定制化的客户服务。
Kafka和KSQL的结合使用,为企业提供了一种强大的工具,能够实时地处理和分析大量的流数据,适应快速变化的业务需求,提升决策速度,优化客户体验,并降低风险。这在当今竞争激烈的市场环境中显得尤为重要,因为企业需要实时响应用户行为,快速调整策略,以保持竞争优势。
使用使用ApacheKafka和和KSQL实现普及化流处理实现普及化流处理
本文要点
大多数的流处理技术,需要开发人员使用Java或Scala等编程语言编写代码。
KSQL是Apache Kafka的数据流SQL引擎,它使用SQL语句替代编写大量代码去实现流处理任务。
KSQL基于Kafka的Stream API构建,它支持过滤、转换、聚合、连接、加窗操作和Sessionization(即捕获单一会话期间的所
有的流事件)等流处理操作。
KSQL的用例涉及实现实时报表和仪表盘、基础设施和物联网设备监控、异常检测和欺骗行为报警等。
你会根据一分钟前的交通信号灯过马路吗?当然不会!当前,现代企业或者出于竞争上的压力,或者因为企业的客户对产品或
服务的交互方式有着更高的期望,它们也面对着同样的需求。
如果人们在iPad上轻点按钮就可以租赁和观看最新的影片,那么为什么还要因为银行账户吃紧而必须等待数小时?
数据在现代企业中处于核心地位,数据的量也在不断增加中,并且持续快速变化。流处理技术正是支持企业实时利用这些洪流
信息的一种技术。目前为重新塑造自身的业务,Netflix、奥迪、PayPal、Airbnb、Uber和纽约时报等上万家企业已经选择了
Apache Kafka?作为流处理平台的事实标准。
人们的很多日常活动,例如阅读报纸、在线购物、预订酒店或航班、搭乘出租车、玩电子游戏或是拨打电话,其后台都已由
Kafka提供支持。
为什么需要流处理?
为了说明流处理技术的作用,我在此给出一个适用于多个不同行业的很好例子。假设我们需要去实时创建并维护客户的全面档
案。这样做出于很多的原因,包括:
为创造更好的客户体验。例如,“这位高级客户在过去五分钟内尝试多次结账购物车,但由于我们最近的网站更新错误而产生
失败。因此,我们需要立即向该客户提供折扣,并对所造成的不良用户体验致歉。”
为尽量降低风险。例如,“这笔新的付款操作似乎存在欺诈。因为该付款是在美国境外发起的,但客户的手机应用报告她身处
纽约市。我们应立即阻止这笔付款,并第一时间联系该客户。”
该用例需要实时汇集来自各种内部渠道的以及一些可能外部渠道的数据,然后将这些信息整合到全面客户档案(也称为客户
的“360度档案”)中。而且一旦任何渠道有新的信息可用,档案都会得到立即更新。
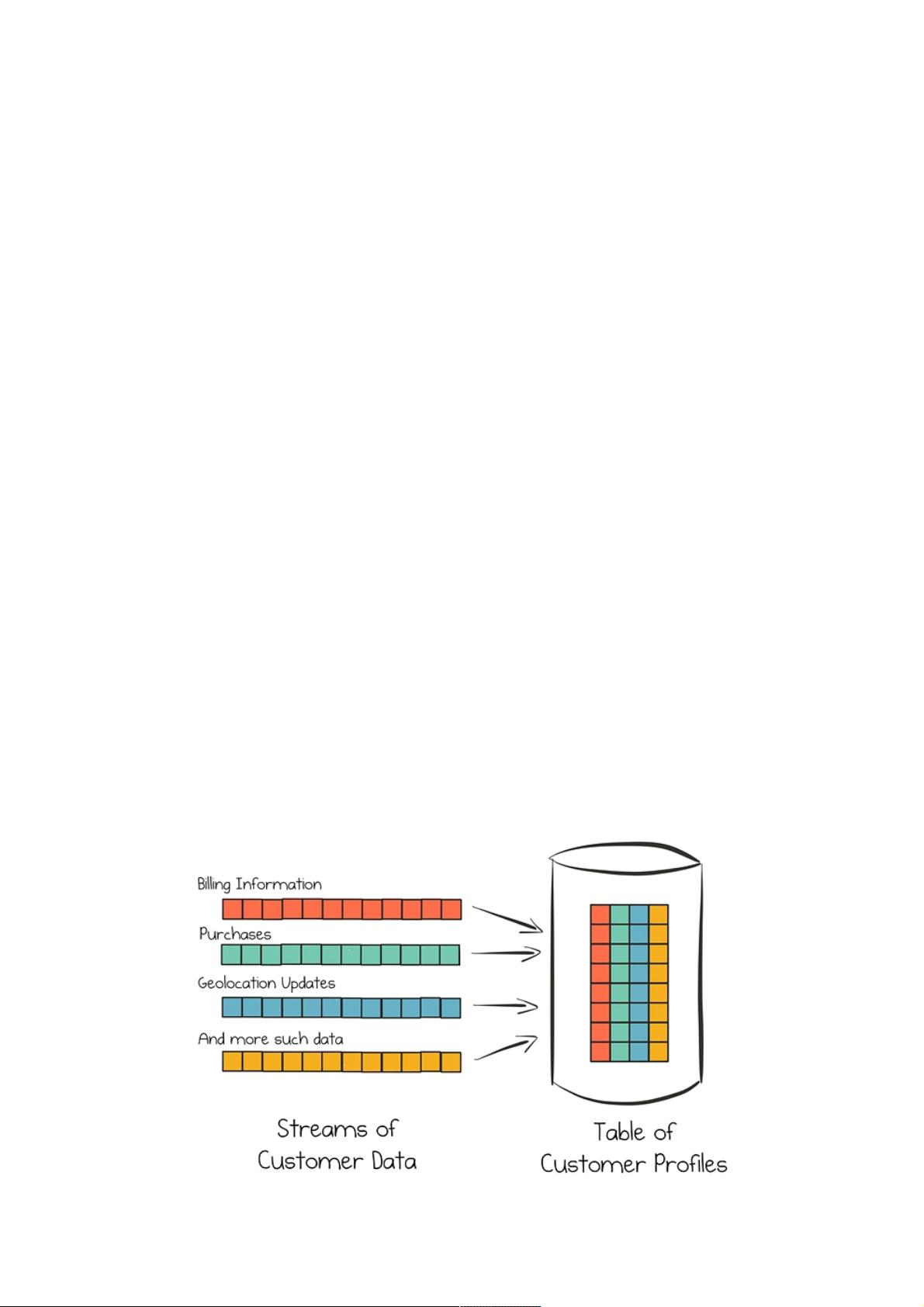
下图描绘了我们如何使用Kafka实现该用例的高层设置。其中,客户数据从各种来源的数据流中持续收集。全面客户档案保持
在表中,表根据这些数据来源构建并持续更新。所有这些操作都是实时的,并具有一定的规模。
图1 从内部和外部客户数据流实时构建全面客户档案
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-30 上传
2019-08-08 上传
2021-01-27 上传
2022-09-24 上传
2021-05-17 上传
2021-09-29 上传

weixin_38617451
- 粉丝: 4
- 资源: 903
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
