
SparkK-Means
介绍
K-Means是被应用的最广泛的基于划分的聚类算法,是一种硬聚类算法,属于典型的局域原型的目标函数聚类的代表。算法首
先随机选择k个对象,每个对象初始地代表一个簇的平均值或者中心。对于剩余的每个对象,根据其到各个簇中心的距离,把
他们分给距离最小的簇中心,然后重新计算每个簇平均值。重复这个过程,直到聚类准则则函数收敛。准则函数一般采用两种
方式:第一种是全局误差函数,第二种是前后两次中心误差变化。
与分类不同,分类是监督学习,要求分类前明确各个类别,并断言每个元素映射到一个类别,而聚类是观察式学习,在聚类前
可以不知道类别甚至不给定类别数量,是无监督学习的一种。目前聚类广泛应用于统计学、生物学、数据库技术和市场营销等
领域,相应的算法也非常的多。
K-Means属于无监督学习,最大的特别和优势在于模型的建立不需要训练数据。在日常工作中,很多情况下没有办法事先获取
到有效的训练数据,这时采用K-Means是一个不错的选择。但K-Means需要预先设置有多少个簇类(K值),这对于像计算某
省份全部电信用户的交往圈这样的场景就完全的没办法用K-Means进行。对于可以确定K值不会太大但不明确精确的K值的场
景,可以进行迭代运算,然后找出cost最小时所对应的K值,这个值往往能较好的描述有多少个簇类。
运用场景
1.商务上,帮助市场分析人员从客户基本库中发现不同的客户群,并且用购买模式来刻画不同的客户群特征。
2.生物学上,用于推导植物和动物的分类,对基因的分类,获得对种群中固有结构的认识。
3.互联网上,用于对Web上的文档进行分类从而发现信息。
4.对一个游戏中的玩家进行分类(下面的案例)。
工作原理
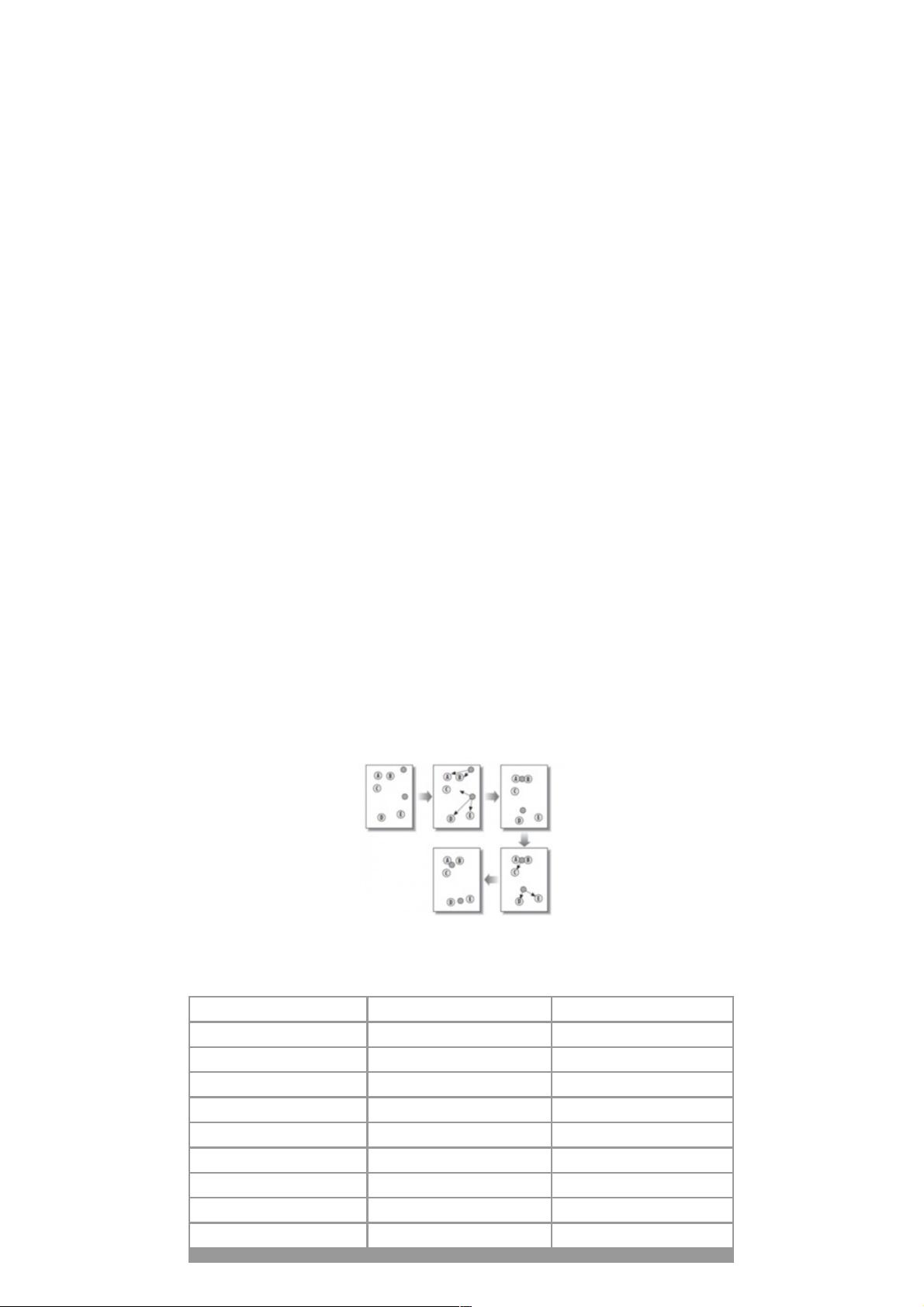
针对包含n个对象的数据集合D以及初始化的聚类数目k,使用下面的算法。
1.从数据集合D中随机选择k个对象作为初始簇中心。
2.根据簇的中心值,把数据集合中的n个对象全部分给最“相似”的簇(“相似”根据距离长短来判断)。
3.根据簇的中心值,重新计算每个簇的中心值。
4.计算准则函数。
5.若准则函数满足阈值则退出,否则返回第二步继续。
输入数据说明
数据:玩家信息(月)
玩家(ID) 游戏时间(小时) 充值金额(元)
1 60 55
2 90 86
3 30 22
4 15 11
5 288 300
6 223 200
7 0 0
8 14 5
9 320 280
下载后可阅读完整内容,剩余3页未读,立即下载

weixin_38734037
- 粉丝: 5
- 资源: 902
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


