词嵌入提升中文文本蕴含识别性能
36 浏览量
更新于2024-08-28
收藏 664KB PDF 举报
本文主要探讨了中文文本蕴含识别技术在自然语言处理任务中的应用和改进。文本蕴含(Textual Entailment)是一种通用框架,用于理解和推断不同语言表达之间的语义关系,它在诸如问答系统、机器翻译和信息检索等领域发挥着关键作用。在特定的研究背景下,研究者针对NTCIR-11 RITE 3简体中文子任务数据集,进行了深入的探索。
首先,论文介绍了对中文文本蕴含识别模型的性能评估。研究者对比了几种结合了不同类型的特征,如词汇(lexical)、句法(syntactic)和语义(semantic)的模型。这些特征旨在捕捉语言的多维度表达,以提升模型对文本蕴含关系的理解。通过实验,作者揭示了这些特征组合对于识别中文文本蕴含的重要性,并提供了相应的性能比较。
然而,为了进一步提高系统的分类能力,论文引入了基于词嵌入(Word Embedding)的词汇蕴含模块。词嵌入是将词语映射到低维连续向量空间的技术,它们能够捕获词语之间的语义相似性和上下文关系。通过这种方式,模型能够更有效地利用词义信息来推断文本间的逻辑联系,从而增强中文文本蕴含识别的精确度和效率。
实验结果显示,词嵌入在中文文本蕴含识别中展现出显著的优势。它不仅提高了模型的准确性,而且在处理大量数据时具有较高的计算效率,有助于提升整个系统的整体性能。此外,研究还强调了在处理汉语这种语法和词汇结构复杂的语言时,词嵌入技术的有效性。
这篇论文通过对中文文本蕴含识别的深入分析和词嵌入技术的应用,为改进中文文本处理系统的性能提供了一种创新方法。未来的研究可以在此基础上探索如何更好地整合各种特征和更先进的嵌入技术,以实现更高效、准确的文本蕴含识别。
Following Table 1 illustrates the lexical features used in our system, where the
symbol T stands for the text in text pair and H for the hypothesis.
These lexical features cannot capture the syntactic structures of two texts and view
a text as a bag of words. But for some text pairs, their entailment relation could not be
correctly detected if their syntactic structure is not considered and compared. Using the
lexical features as a base, more complex features from syntactic to semantic aspects
should be checked too.
2.1.2 Syntactic Features
As we discussed above, lexical features can’t capture the text syntactic information. For
example:
<pair id = “30”>
<t>《瀛台泣血记》为清朝宫廷女 官 裕德龄所撰写的一本有关光绪皇帝一
生的故事。(Son of heaven that talks about Guangxu emperor’s whole life is written by
DeLing yu who is a female official in Qing dynasty) </t>
<h>《瀛台泣血记》为清朝宫廷女官裕光绪所撰写的一本有关德 龄 皇帝一
生的故事。(Son of heaven that talks about DeLing emperor’
s whole life is written by
Guangxu yu who is a female official in Qing dynasty) </h>
</pair>
<pair id = “237”>
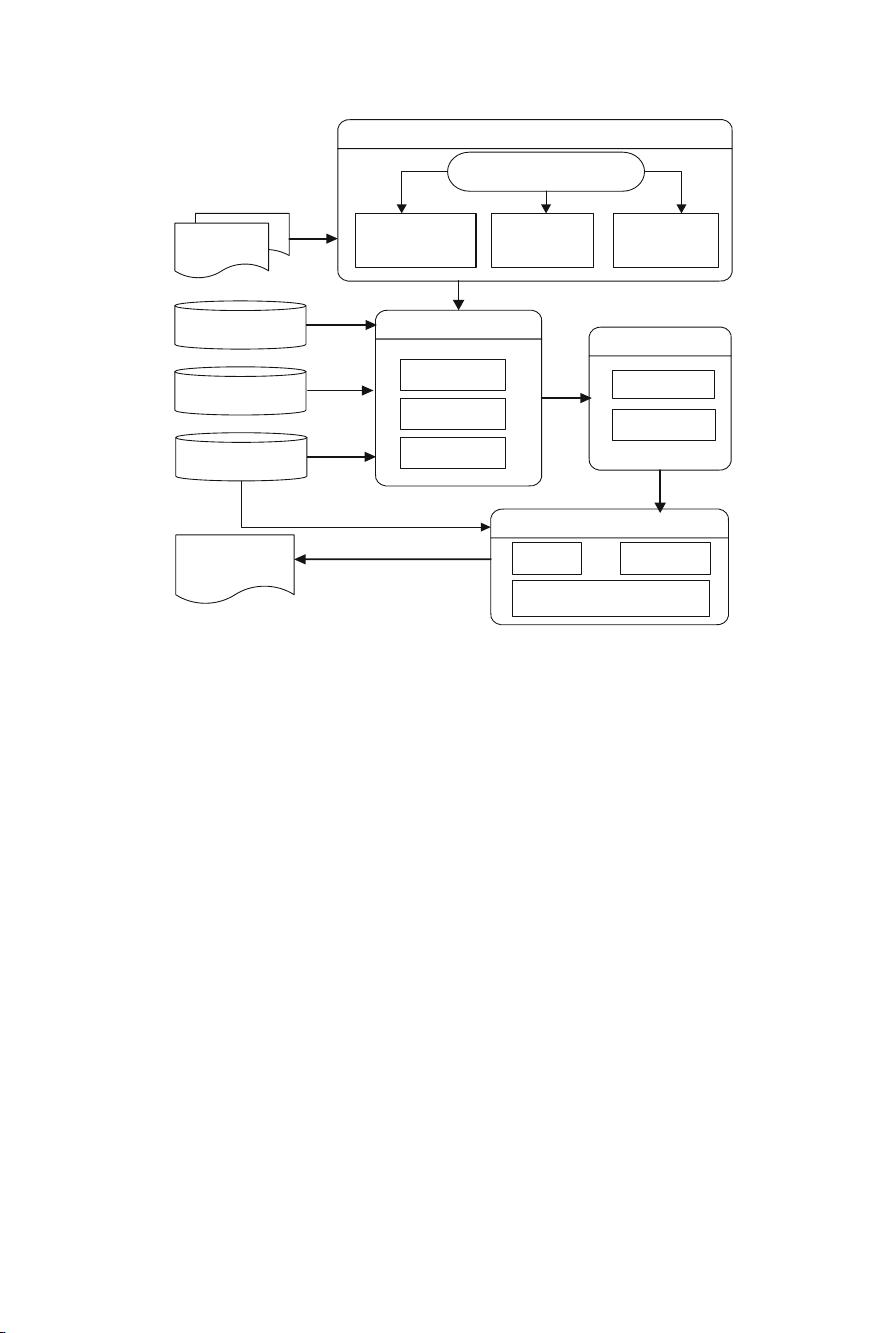
(T,H) pairs
Pre-Processing
LTP/Stanford
Feature Extraction
Lexical
Semantic
Syntactic
Classification
SVM
NB
Amending
TemporalNumber
Specific Syntactic analysis
recongnition
result
Chinese Word
Segment
Syntactic
Parsing
Name Entity
Recognition
TongYiCiCiLin
Antonyms
Internet
Knowledge
Fig. 1. System architecture
Chinese Textual Entailment Recognition Enhanced 91
剩余11页未读,继续阅读
145 浏览量
点击了解资源详情
126 浏览量
138 浏览量
2023-06-09 上传
2021-02-11 上传
551 浏览量
2021-07-21 上传
123 浏览量

weixin_38545485
- 粉丝: 5
- 资源: 982
 我的内容管理
展开
我的内容管理
展开







最新资源
- basix:FEniCS运行时基础评估库
- 易语言超级列表框简单实现表项可编辑
- LCL型并网逆变器的控制技术_逆变器并网_逆变器_阮新波_并网逆变器_gridcontrol
- redux-websocket-example:在Redux驱动JavaScript应用程序中使用WebSockets的示例
- cchw41
- webtest-casperjs:将 casperjs 与 WebTest 结合使用
- nodegit:本机节点绑定到Git
- 易语言超级列表框消息操作
- 1、基于电流正反馈控制的三相四桥臂逆变器_逆变器_三相四桥臂_四桥臂逆变器_四桥臂_fourleg
- Gerenciador产品
- mbed-hx711:用于Mbed的HX711称重传感器放大器库
- sub
- iux1.2.2爱前端主题 自媒体资讯博客WordPress主题模板
- from-zero-to-hero-with-RSpec
- LLC闭环程序_stm32_withinf9g_闭环LLC_LLC闭环_llc闭环参数
- data-collecter:数据采集器
