NTCIR-11 RITE-3任务: NWNU文本蕴含系统
158 浏览量
更新于2024-08-28
收藏 633KB PDF 举报
"这篇文章是关于西北师范大学在NTCIR-11 RITE-3任务中的工作,主要涉及简体中文的二元分类(BC)子任务和多类(MC)子任务。他们提出了一种结合多种特征的混合方法来构建文本蕴含系统。该方法在正式运行中在BC子任务中达到了59.71%的Macro-F1分数,而在MC子任务中仅为23.19%。"
本文是针对NTCIR-11 RITE-3挑战的报告,该挑战关注的是识别文本表达对之间的蕴含关系。文本蕴含(Textual Entailment)是指一个文本(T,即entailing "Text")可以推断出另一个文本(H,即entailed "Hypothesis")最有可能为真。当人类读取T时,通常会推理出H的真实性。
西北师范大学的团队参与了这项比赛的两个子任务:二元分类(BC)和多类(MC)。在BC子任务中,目标是区分两个文本之间是否存在蕴含关系,而MC子任务则更复杂,需要识别多种类型的蕴含关系。他们提出的系统采用了混合方法,整合了多种特征以提高性能。这种混合方法可能包括基于规则的方法、统计学习方法以及深度学习方法,以充分利用各种信息源来捕获文本之间的语义联系。
在BC子任务中,系统表现优秀,取得了59.71%的Macro-F1分数。Macro-F1分数是评估多类别分类任务性能的一个指标,它考虑了所有类别的精确度和召回率的平均值。这表明系统在判断两个文本是否具有蕴含关系方面有较高的准确性和全面性。
然而,在MC子任务中,系统的性能显著下降,只有23.19%的Macro-F1分数。这可能表明在处理多类别蕴含关系时,模型面临的挑战更大,可能需要更复杂的特征工程或更强大的模型来处理多种不同类型的蕴含关系。
关键词:文本蕴含、机器学习、RITE
这个研究工作突显了在处理文本蕴含问题时,设计有效的特征和采用混合方法的重要性。尽管在某些情况下,如BC子任务,这种方法可以取得较好的结果,但在更复杂的任务中,如MC子任务,仍然存在改进的空间。未来的研究可能会探索更先进的机器学习算法,如深度神经网络,以提高在多类别的文本蕴含识别中的性能。
NWNU Minimum Information Recognizing Entailment System for NTCIR-11 RITE-3 Task
Zhichang Zhang, Dongren Yao, Longlong Mao, Songyi Chen
School of Computer Science and Engineering, Northwest Normal University, Lanzhou, China
zzc@nwnu.edu.cn;wade330628704@163.com;
775919087@qq.com;snail200x@163.com
Abstract
This paper describes our work in NTCIR-11 on
RITE-3 Binary-class (BC) subtask and Multi-class
(MC) subtask in Simplified Chinese. We proposed a
textual entailment system using a hybrid approach that
integrates many features. The performance of the
proposed method in the formal run achieved
Macro-F1’s of 59.71% in BC subtask and only 23.19%
in MC subtask
Key words
Textual entailment, Machine Learning, RITE.
1 Introduction
The Recognizing Inference in TExt (RITE)
challenge focuses on detecting the directional
entailment relationship between pairs of text
expressions, denoted by T (the entailing “Text”) and H
(the entailed “Hypothesis”). We say that T entails H if
human reading T would typically infer that H is most
likely true [1].
NWNU team participated in NTCIR-11 RITE-3
Binary-class (BC) subtask and Multi-class (MC) in
Simplified Chinese (CS). We submitted 5 official runs
for BC subtask and 3 runs for MC subtask. Our system
focuses on the minimum information between two
texts, and we find out those information help our
system recognize the entailment relationship more
effectively.
The rest of the paper is arranged as follows:
section 2 describes the features and algorithms
employed in our system in detail; section 3 presents
and discusses the official evaluation; section 4
concludes this paper with a description of the future
work.
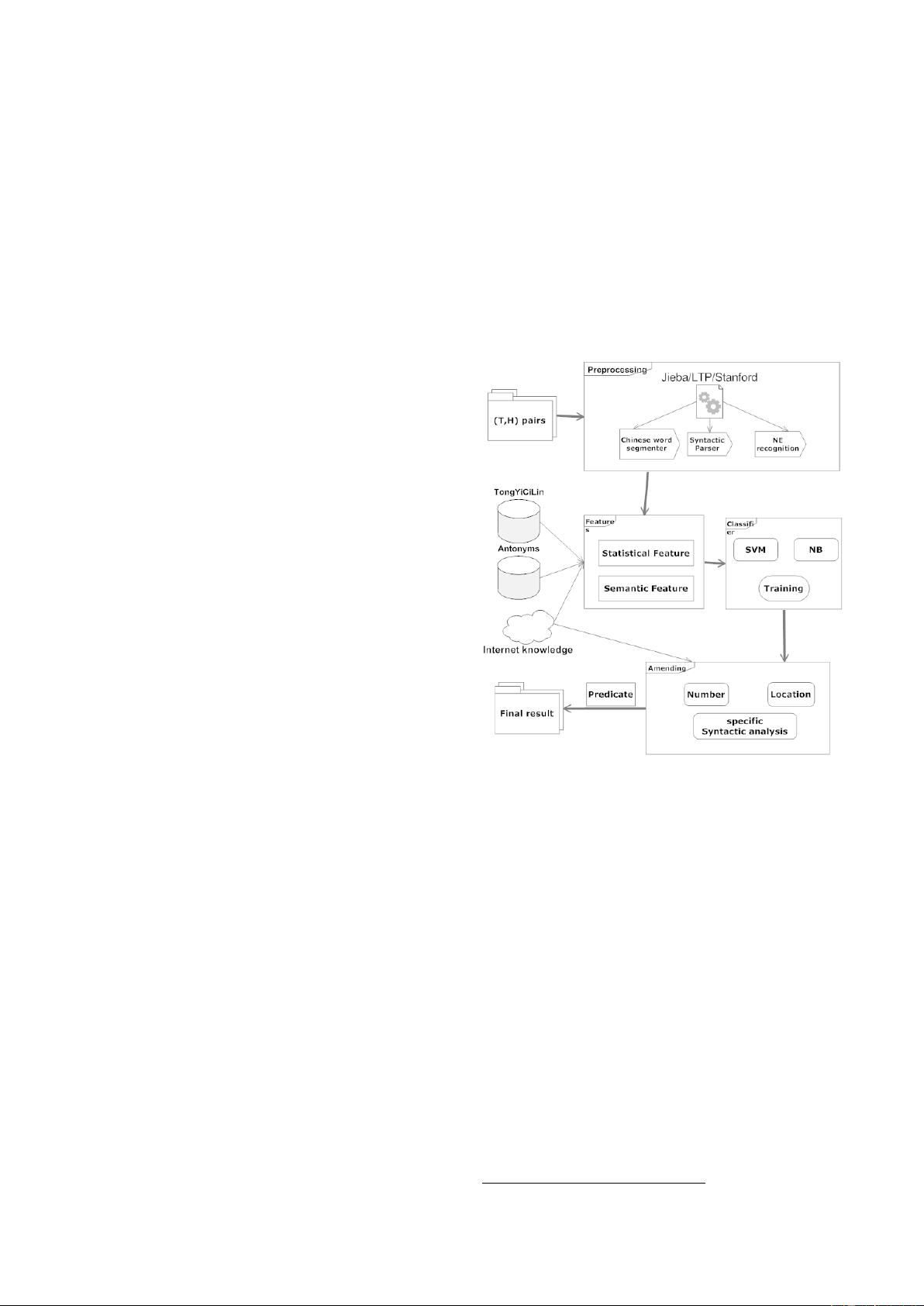
2 System description
There will be four main modules in our system,
i.e. preprocessing, feature extraction, classifier and
amending module. Figure 1 show more details in our
system:
Figure1. System architecture
2.1 Preprocessing module
This module uses hybrid NLP resources and tools
for basic processing like word segment, POS, and NE
recognition. We use Jieba as our word segment tool,
and LTP
1
tool for POS tagging, dependency syntactic
parsing and Stanford classifier for recognizing on
named entity.
2.2 Feature extraction
Because of the complexity on textual entailment,
many factories should be taken into consideration.
Some traditional features including statistical and
lexical semantic features are used in the statistical
machine learning models to classify whether T in a
given text-hypothesis pair entail H. The following table
1
http://www.ltp-cloud.com/demo/
Proceedings of the 11th NTCIR Conference, December 9-12, 2014, Tokyo, Japan
288
下载后可阅读完整内容,剩余3页未读,立即下载
141 浏览量
2022-07-09 上传
123 浏览量
2023-06-10 上传
179 浏览量
409 浏览量

weixin_38732519
- 粉丝: 2
- 资源: 951
 我的内容管理
展开
我的内容管理
展开







最新资源
- Music Alarm Clock with Sleep Timer-开源
- GuessNumberOneTen:和一篇有关猜测1到10的数字的博客文章一起使用!
- 通用队列的草图-多线程变得容易
- APx500_4.5.2_w_dot_Net 音频分析仪软件 apx515 apx525
- py_course
- 考试系统:教师出题,学生进行考试自动换算成绩系统
- CPU_SELF_monocycle_单周期CPU设计_单周期cpu_单周期_FPGAverilog_cpu_
- Hacker News Stack-crx插件
- accumulo-upgrade-test:测试 Apache Accumulo 升级
- Bobby.jl-bd34264e-e812-11e8-1ee8-bfb20fea2fb4:最后由https://github.comalemelisBobby.jl.git镜像于2019-11-18T18:50:36.398-05:00(@UnofficialJuliaMirrorBot)通过Travis作业481.6触发特拉维斯·克朗在“大师”分支上的工作
- ubuntu-14.04.3-desktop-i386.rar
- bab-3:源代码练习题第3章java书2
- MongoDbPython:用于连接mongo数据库的示例python脚本
- JavaFacul2021:2021年运动会报名
- 无线传感器课设_串口调试助手_
- APx500_4.5.2 音频分析仪软件 apx515 apx525
