Azkaban实战:从多job执行到MapReduce程序
36 浏览量
更新于2024-08-29
收藏 468KB PDF 举报
"Azkaban实战案例"
Azkaban是一个开源的工作流执行引擎,常用于大数据处理中的任务调度。本文将通过三个实战案例介绍如何在Azkaban中配置和执行任务。
1. Command类型多job执行
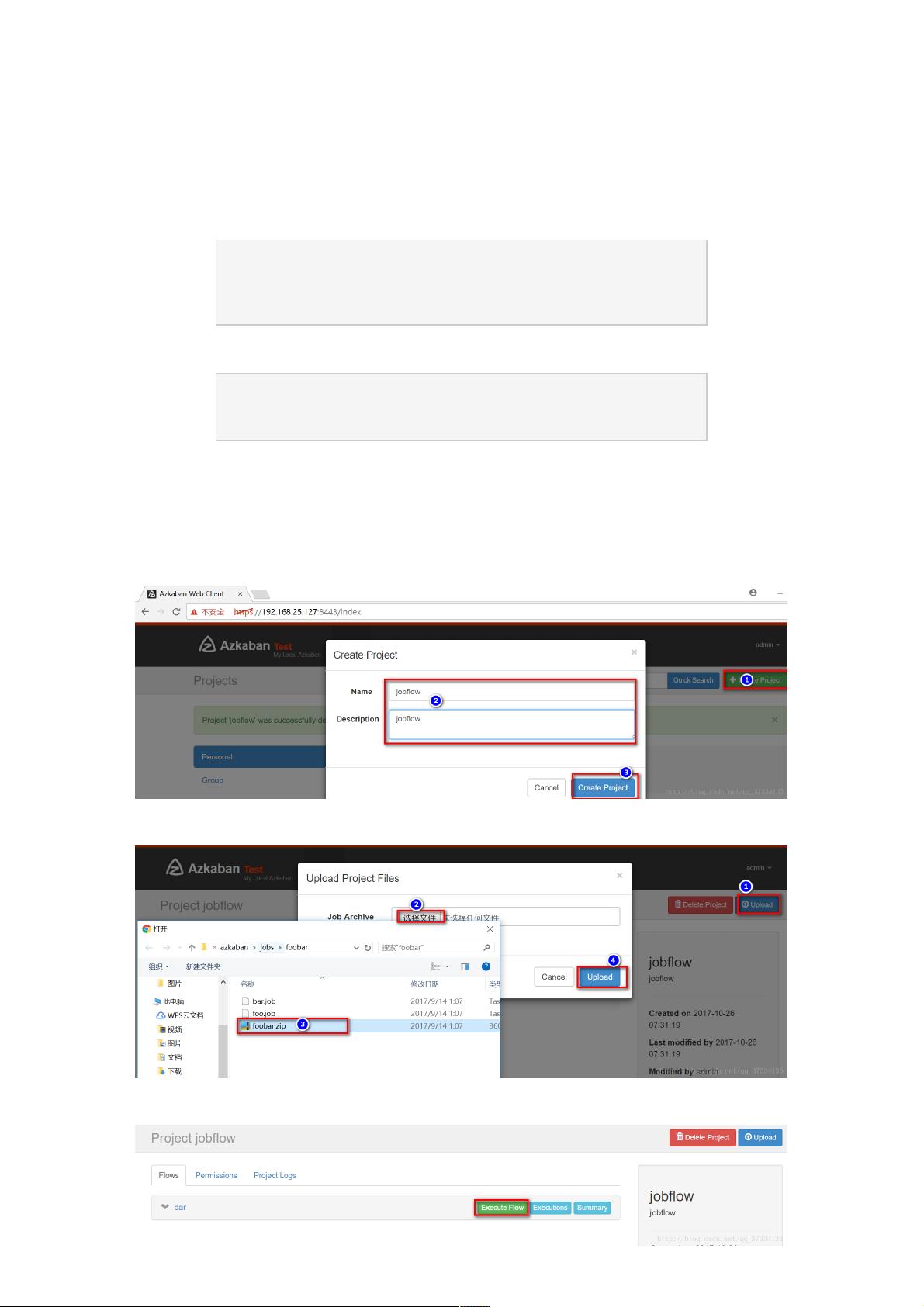
在Azkaban中,可以创建多个job并定义它们之间的依赖关系。例如,`bar.job`依赖于`foo.job`,这意味着在`foo.job`执行成功后才会执行`bar.job`。每个job的配置文件中定义了job类型(在这里是`command`)和要执行的命令。例如,`foo.job`执行`echofoo`命令,而`bar.job`执行`echobar`命令。这些job被打包成`foobar.zip`,然后在Azkaban的web管理界面创建项目并上传此zip包。上传后,可以选择立即执行或按计划执行,执行成功后可以在details中查看执行详情。
2. HDFS操作任务
Azkaban还支持执行HDFS相关的操作。例如,`fs.job`定义了一个命令,用于在HDFS上创建目录。这个job指定了`/root/apps/hadoop-2.6.4/bin/hadoopfs-mkdir/azaz`作为命令,确保指定了Hadoop命令的完整路径。使用`which hadoop`可以查找Hadoop的安装位置。将`fs.job`打包成`fs.zip`后,同样上传到Azkaban创建的项目中,并执行该job。如果Hadoop集群运行正常,job执行完成后会在HDFS上看到新创建的目录。
3. 跑MapReduce程序
Azkaban可以通过`command`类型的job执行MapReduce程序。以WordCount为例,创建`mrwc.job`,指定执行`wordcount`程序的命令,包括Hadoop的路径、jar包以及输入输出目录。确保包含MapReduce程序的jar包也在上传的zip包中。执行`mrwc.job`后,Azkaban会运行WordCount任务,并在指定的输出目录下生成结果。
总结来说,Azkaban提供了一种灵活的方式来组织和调度大数据处理任务,涵盖了从简单的命令执行到复杂的MapReduce程序的运行。通过编辑job内容,定义job间的依赖,打包上传到Azkaban,用户可以方便地管理和执行一系列数据处理流程。此外,Azkaban的web管理界面提供了详细的执行状态和日志,便于监控和调试任务。
Azkaban实战案例实战案例
1、Commond类型多job执行
1)、编辑job内容
第一个job(bar.jab)内容如下,依赖foo.job
# bar.job
type=command
dependencies=foo
command=echo bar
第二个job(foo.job)内容如下
# foo.job
type=command
command=echo foo
2)、两个job打到一个zip包中(foobar.zip)
3)、在azkaban的web管理界面创建工程并上传zip包
这里演示一遍后面就不演示了
创建project
选择刚打好的foolbar.zip上传
上传后选择执行
下载后可阅读完整内容,剩余4页未读,立即下载
2022-04-30 上传
2021-10-21 上传
点击了解资源详情
2022-04-30 上传
2015-06-18 上传
2022-04-10 上传
2022-02-15 上传
点击了解资源详情
点击了解资源详情

weixin_38660579
- 粉丝: 11
- 资源: 918
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新代数控API接口实现CNC数据采集技术解析
- Java版Window任务管理器的设计与实现
- 响应式网页模板及前端源码合集:HTML、CSS、JS与H5
- 可爱贪吃蛇动画特效的Canvas实现教程
- 微信小程序婚礼邀请函教程
- SOCR UCLA WebGis修改:整合世界银行数据
- BUPT计网课程设计:实现具有中继转发功能的DNS服务器
- C# Winform记事本工具开发教程与功能介绍
- 移动端自适应H5网页模板与前端源码包
- Logadm日志管理工具:创建与删除日志条目的详细指南
- 双日记微信小程序开源项目-百度地图集成
- ThreeJS天空盒素材集锦 35+ 优质效果
- 百度地图Java源码深度解析:GoogleDapper中文翻译与应用
- Linux系统调查工具:BashScripts脚本集合
- Kubernetes v1.20 完整二进制安装指南与脚本
- 百度地图开发java源码-KSYMediaPlayerKit_Android库更新与使用说明
