MSSQL分布式查询详解:跨服务器数据获取与实现策略
32 浏览量
更新于2024-08-28
收藏 586KB PDF 举报
MSSQL分布式查询是SQL Server的一项特性,它允许用户访问存储在同一台或不同计算机上的SQL Server实例以及各种异构数据源,增强了数据的横向扩展和跨服务器访问能力。与普通查询相比,分布式查询的关键在于连接多个MSSQL服务器,这使得数据源不再局限于单个实例,而是可以跨越网络进行协作。
在MSSQL Server 2005及后续版本中,分布式查询主要依赖于OLE DB(Object Linking and Embedding Data Provider)接口,这是一种微软提供的通用数据访问标准。通过OLE DB,客户端可以连接到多个SQL Server实例,甚至包括那些支持OLEDB访问的非SQL数据源,如Oracle、MS Jet、ODBC等。这种方式在Transact-SQL语句中通过类似于引用SQL Server表的方式来操作这些外部数据源,尽管内部机制涉及到行集(类似于临时表,但容量大、类型丰富)。
分布式查询的主要步骤如下:
1. 客户端发起数据请求时,首先会检查本地MemCacheServer缓存,如果没有所需数据,就会触发分布式查询。
2. 分布式查询会涉及到多个远程服务器上的多个数据库表,客户端通过OLE DB连接到这些服务器。
3. 数据被检索后,会实时同步到缓存服务器以保持数据的一致性,同时直接返回给客户端。
4. 在MSSQL 2005中,有两种实现方式:一种是使用链接服务器(Linked Server),另一种是通过分布式查询代理(Distributed Query Agent)。链接服务器允许创建指向其他服务器的逻辑别名,而分布式查询代理则负责协调和执行跨服务器的查询任务。
通过分布式查询,系统可以更有效地处理大规模数据,提高查询性能,并支持灵活的数据整合,这对于企业级应用和大数据处理非常重要。然而,为了充分利用分布式查询,开发者需要了解并管理好连接配置、安全性、性能优化等方面的问题,以确保数据的可靠性和系统的稳定运行。
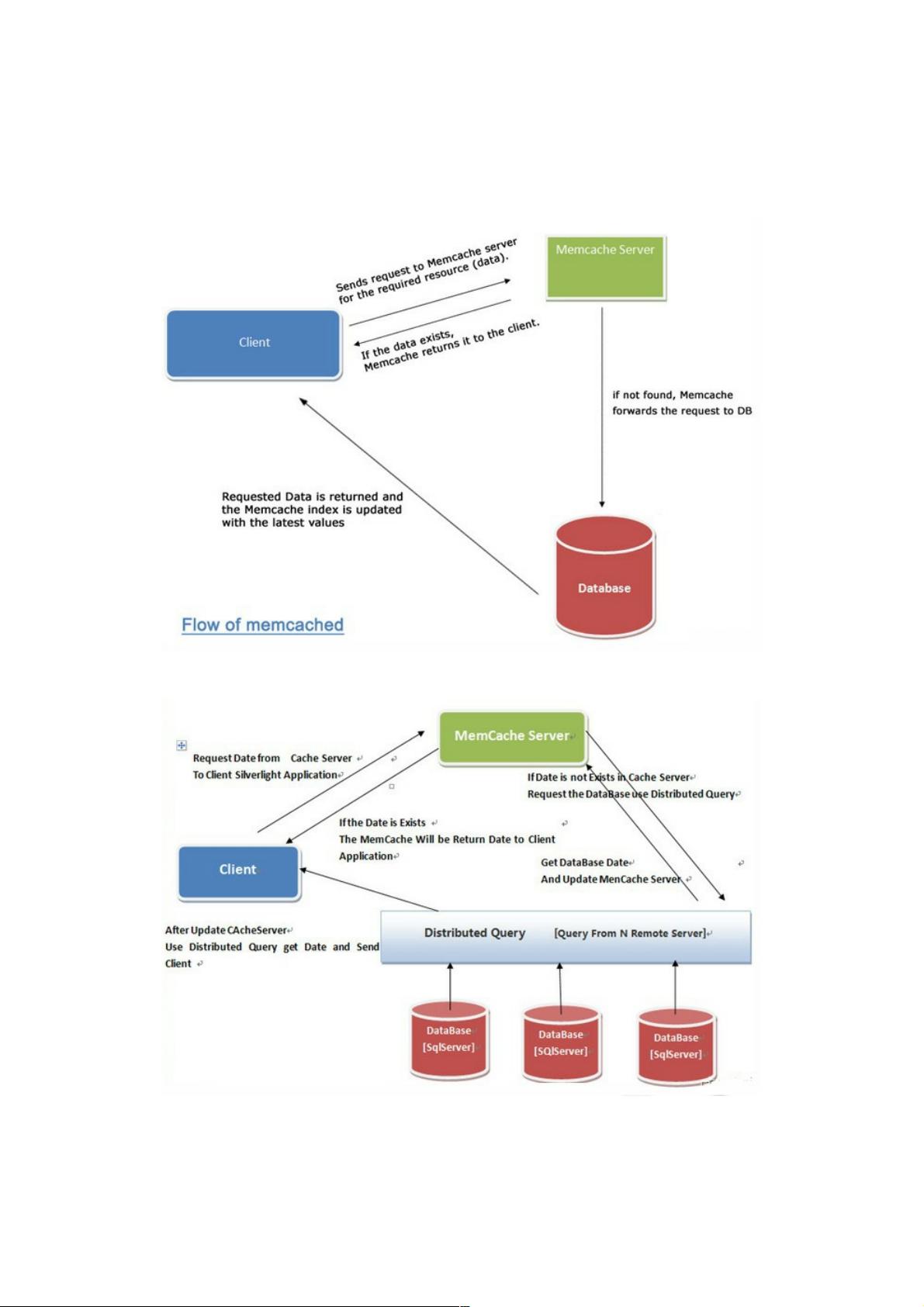
MSSQl分布式查询分布式查询
MSSQlServer所谓的分布式查询(Distributed Query)是能够访问存放在同一部计算机或不同计算机上的SQL Server或不同种类
的数据源, 从概念上来说分布式查询与普通查询区别 它需要连接多个MSSQL服务器也就是具有多了数据源.实现在服务器跨域
或跨服务器访问. 而这些查询是否被使用完全看使用的需要.
本篇将演示利用SQlExpress链接远程SQlServer来获取数据方式来详细说明分布式查询需要注意细节.先看一下系统架构数据
查询基本处理:
当然如果采用了分布式查询 我们系统采取数据DataBase也就可能在多个远程[Remote Server]上访问时:
如上截取系统架构中关于数据与缓存流向中涉及的分布式查询业务, 当我们从客户端Client发起请求数据时. 首先检查
MemCache Server缓存服务器是否有我们想要数据. 如果没有我需要查询数据库. 而此时数据要求查询多个远程服务器上多个
数据库中表, 这时利用分布式查询.获得数据 然后更新我们在缓存服务器MemCache Server上数据保持数据更新同步, 同时向客
户端Client直接返回数据.那如何来执行这一系列动作中最为关键分布式查询?
<1>分布式查询方式
我们知道Microsoft微软公用的数据访问的API是OLE_DB, 而对数据库MSSQlServer 2005的分布式查询支持也是OLE_DB方
下载后可阅读完整内容,剩余7页未读,立即下载
2011-01-25 上传
2012-03-01 上传
2011-01-03 上传
2021-08-10 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38749305
- 粉丝: 0
- 资源: 932
 我的内容管理
展开
我的内容管理
展开







最新资源
- StarModAPI: StarMade 模组开发的Java API工具包
- PHP疫情上报管理系统开发与数据库实现详解
- 中秋节特献:明月祝福Flash动画素材
- Java GUI界面RPi-kee_Pilot:RPi-kee专用控制工具
- 电脑端APK信息提取工具APK Messenger功能介绍
- 探索矩阵连乘算法在C++中的应用
- Airflow教程:入门到工作流程创建
- MIP在Matlab中实现黑白图像处理的开源解决方案
- 图像切割感知分组框架:Matlab中的PG-framework实现
- 计算机科学中的经典算法与应用场景解析
- MiniZinc 编译器:高效解决离散优化问题
- MATLAB工具用于测量静态接触角的开源代码解析
- Python网络服务器项目合作指南
- 使用Matlab实现基础水族馆鱼类跟踪的代码解析
- vagga:基于Rust的用户空间容器化开发工具
- PPAP: 多语言支持的PHP邮政地址解析器项目
