图布局算法详解:可视化与历史回顾
需积分: 10 170 浏览量
更新于2024-09-09
收藏 259KB DOC 举报
本文是一篇深入探讨图布局算法的综述文章,作者Boštjan Pajntar来自南斯拉夫Jozef Stefan Institute的知识技术部门。文章旨在帮助读者理解和选择最适合可视化工件关系数据的算法,同时提供了一个历史视角,回顾了图布局算法的发展历程。
首先,文章指出在信息时代,数据的规模迅速扩大,传统的信息获取方式转变为挖掘有价值的信息。为了更有效地传达这些大数据,可视化的需求应运而生,图形化表示关系数据成为了重要的信息呈现手段。图论在不同的研究文献中可能有不同的定义,但本文采用了一个通用的框架,包括顶点集V、边集E和边缘映射函数λ。简单图指无环且无多重边的图,而有向图则包含方向性的边。
文章强调了图的大小或规模的概念,这里并未采用单一的术语,而是结合了顶点数量和计算复杂度来衡量。根据图的规模,图被分为小、中、大和超大四类:
- 小图(规模n*10,通常不超过150个顶点):适用于各种算法,因为它们的规模较小,可以轻易处理。
- 中图(规模n*100):可以由多项式时间复杂度的算法绘制,适合在常规屏幕上展示。
- 大图:由于屏幕限制,无法直接绘制,需要通过其他方法如分块或缩放来处理。
对于大图,作者提到了存在的挑战,即如何在有限的屏幕空间内有效地展现复杂的关系网络。这涉及到一系列的算法优化,如力导向布局(Force-Directed Layout)、层次布局(Hierarchical Layout)和分层聚类(Hierarchical Clustering)等,这些算法利用吸引力和排斥力原则、层级结构或聚类分析来组织节点的位置。
此外,文章还可能讨论了其他经典算法,如Fruchterman-Reingold算法、Spring Embedding算法、Kamada-Kawai算法以及Gephi等工具中的算法实现。这些算法各有特点,如Fruchterman-Reingold算法适用于展示大型网络的全局结构,而Spring Embedding则关注保持相邻节点之间的相似距离。
本文通过详细的算法描述,不仅为读者提供了实用的工具选择指南,也揭示了图布局算法在数据可视化的实际应用和研究中的重要性。对于从事数据分析、图形用户界面设计或者网络科学等领域的人来说,这篇文章是一份宝贵的参考资源。
OVERVIEW OF ALGORITHMS
FOR GRAPH DRAWING
图布局算法综述
Boštjan Pajntar
Department of Knowledge Technologies
Jozef Stefan Institute
Jamova 39, 1000 Ljubljana, Slovenia(南斯拉夫)
Tel: +386 1 4773128
E-mail: bostjan.pajntar@ijs.si
摘要
本文综述若干种图可视化算法,并详细描述了最常用的几个算法。本文的首要目的是帮助读者
选择合适的算法去可视化关系数据。另一方面,也可以当作对图布局算法及其发展的历史回顾
1 概要
从前,信息只是一种 commodity(?商品,不足大量)。然而随着互联网的发展,大规模的数
据变得随处可见。问题从获取信息,变为抽取其中的有用信息。使用统计分析与数据挖掘,我
们能够抽取所需的信息。但是,由于显示是平面的,大部分这些数据挖掘的结果难以为人们所
阅读,由此就产生了对可视化的需求。因为一张图画常常可以蕴含一篇文章(的信息),对任
何关系数据的描绘成为了一种非常常用的表示已获信息的途径。
2 关于图
图论中的定义在不同文献中有所不同。针对我们的需求,图G的一个宽松的定义是一个三元组
(V,E, λ)
- 顶点集V
- 边集E
- 函数λ,映射每条边的端点到一个顶点
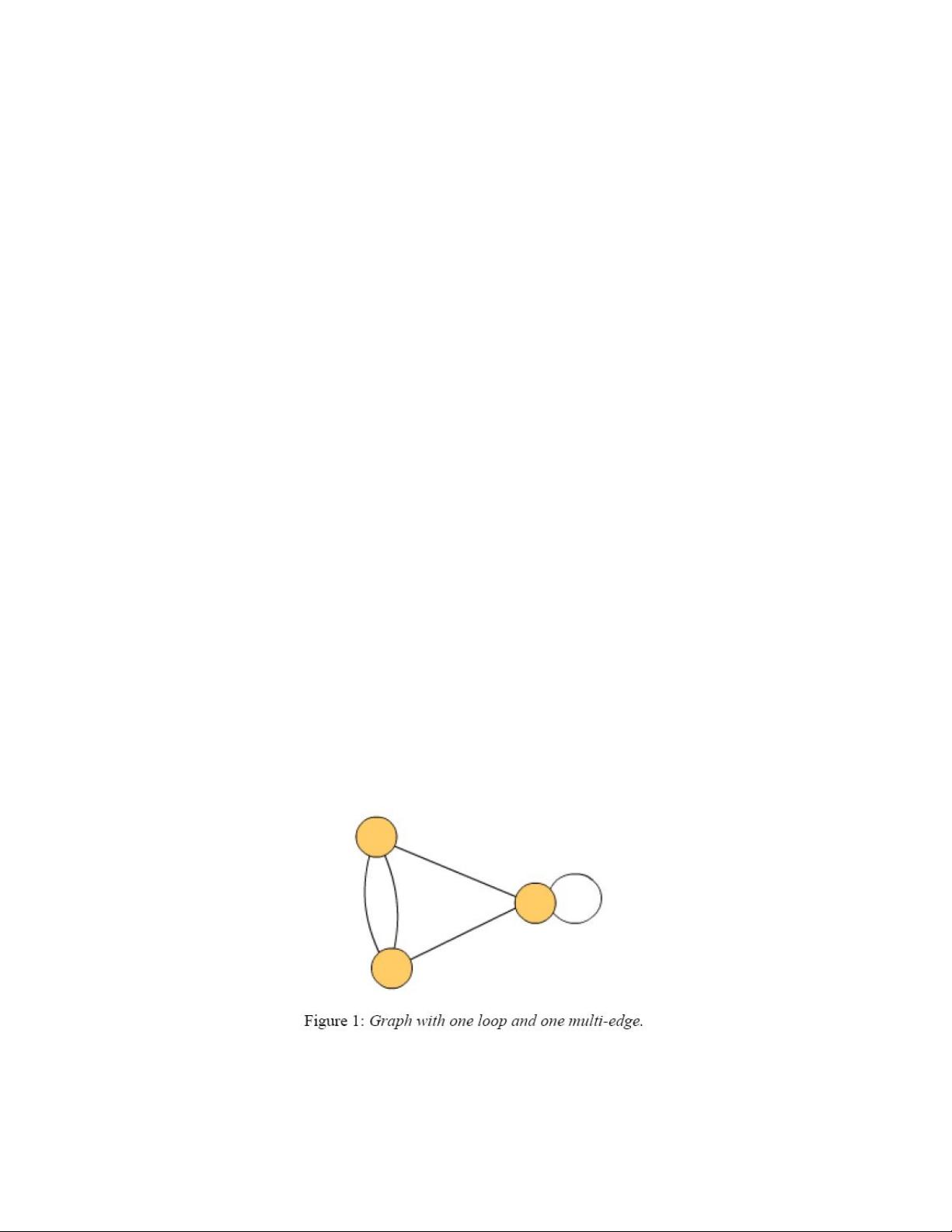
一个循环是一条两端指向相同顶点的边。一条多重边表示两个顶点同时关联多条边(图1)。一个
没有循环和多重边的图称为简单图。如果边是有向的,则图为有向图(digraph)。
3 图的大小(size,规模)
关于图的大小并没有专门的术语。图的大小常常被定义为顶点的数目,这并非是一个最好的定义。
由于计算机运行速度日益增长,图的大小会随着时间而改变(译者注:暗示图的大小跟计算机运行
下载后可阅读完整内容,剩余6页未读,立即下载
2009-01-04 上传
2012-04-19 上传
2013-04-17 上传
2023-04-22 上传
2024-02-24 上传
2023-02-07 上传
2023-02-06 上传
2023-05-13 上传
2023-10-03 上传

jlumarvin
- 粉丝: 0
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







