Spark中处理Key/Value对的关键技巧
需积分: 10 64 浏览量
更新于2024-07-19
收藏 1.72MB PDF 举报
"《OReilly.Learning.Spark》是一本关于Spark技术的书籍,其中第四章主要讨论了在Spark中处理Key/Value对的方法。该章节内容涵盖了如何使用Key/Value类型的弹性分布式数据集(RDD),这种数据类型在Spark中的聚合操作中非常常见,并且经常需要通过ETL过程将原始数据转换为Key/Value格式。此外,还介绍了一个高级特性,即分区(Partitioning),允许用户控制Pair RDD在节点间的布局,以优化通信成本和数据访问效率。"
在Spark中,Key/Value对是核心的数据结构之一,它对于数据处理和分析至关重要。这一章首先解释了Key/Value对的基本概念和其在各种操作中的应用。例如,统计每个产品收到的评论数量就是一个典型的Key/Value对操作,其中键可能是产品ID,值是对应产品的评论数。通过Spark提供的操作,可以方便地对具有相同键的数据进行分组,实现数据聚合。
ETL(提取、转换、加载)是数据分析的常用流程,对于Key/Value对来说,这个过程可能包括从各种数据源(如日志文件、数据库等)提取数据,然后将其转换成键值对形式,最后加载到Spark集群进行进一步处理。在这个过程中,转换步骤可能涉及数据清洗、数据格式统一等。
更进一步,本章提到了一个关键的优化技巧——分区。Spark允许用户自定义Pair RDD的分区策略,这意味着可以根据数据的属性或业务需求来决定数据在集群中的分布。通过合理的分区,可以确保相关数据被存储在同一节点上,从而减少网络通信,提高计算效率。例如,如果知道两个键相关的数据经常一起处理,那么将它们分配到同一个分区就能减少数据移动,加快计算速度。
此外,分区还有助于平衡集群的工作负载,防止某些节点过载,提高整个系统的稳定性和性能。学习如何根据具体应用场景选择和调整分区策略,是提升Spark应用性能的重要手段。
本章内容深入浅出地讲解了Spark中处理Key/Value对的基础和进阶技巧,对理解Spark的内在机制和优化数据处理流程具有很高的指导价值。无论是初学者还是经验丰富的Spark开发者,都能从中受益匪浅。

50 | Chapter 4: Working with Key/Value Pairs
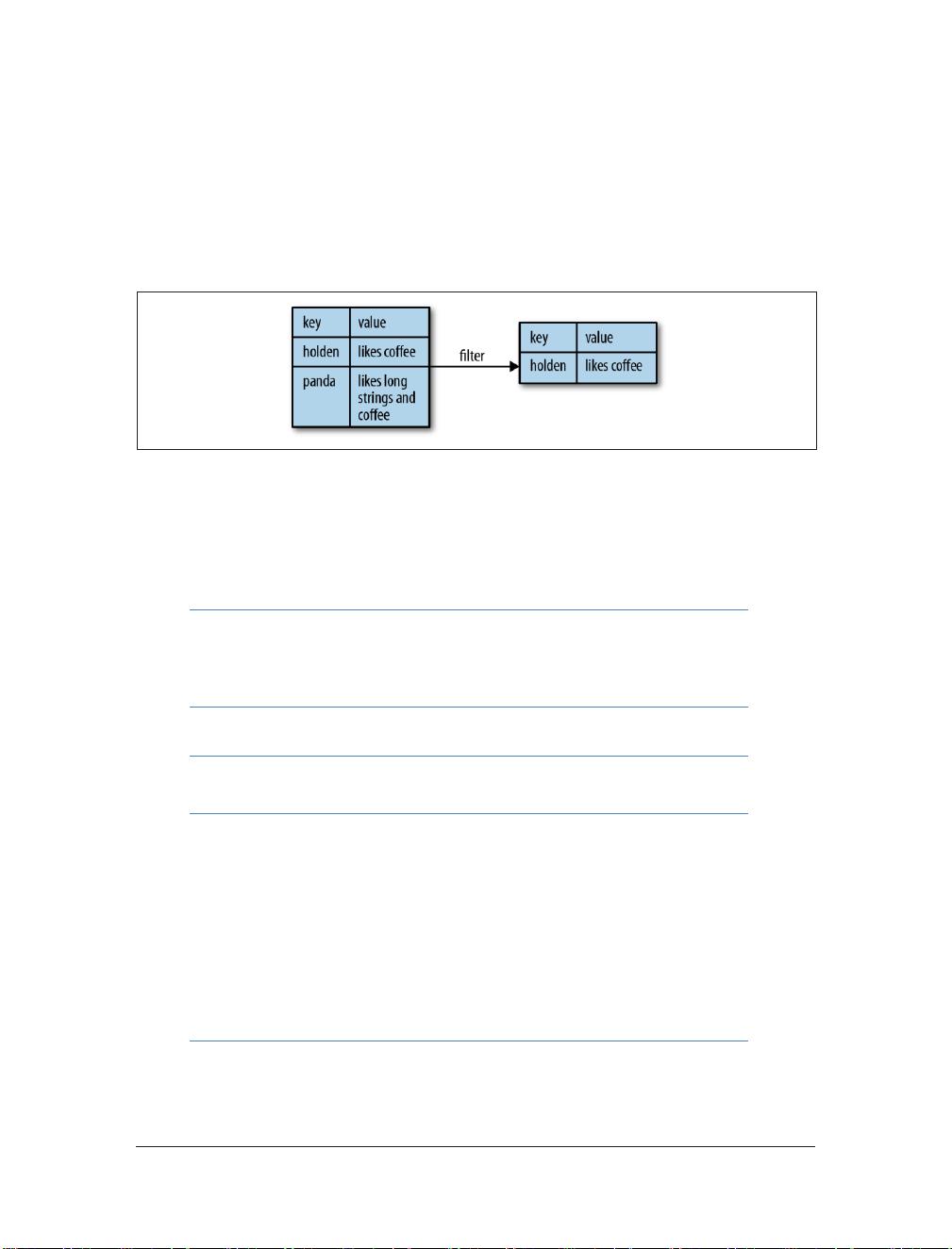
pair RDD 也仍然是 RDD(包含 Scala 或 Python 的元组、Java 的 Tuple2 对象),自然
也支持 RDD 上的函数。例如,我们可以利用我们 pair RDD 从上一节并过滤掉行超过
20 个字符,如下例 4-4 至 4-6 和图 4-1。
Example 4-4. Simple filter on second element in Python
result = pairs.filter(lambda keyValue: len(keyValue[1]) < 20)
Example 4-5. Simple filter on second element in Scala
pairs.filter{case (key, value) => value.length < 20}
剩余41页未读,继续阅读
2018-07-24 上传
183 浏览量
567 浏览量
149 浏览量
2025-03-13 上传

ryuunosuke
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Vue.js波纹效果组件:Vue-Touch-Ripple使用教程
- VHDL与Verilog代码转换实用工具介绍
- 探索Android AppCompat库:兼容性支持与Java编程
- 探索Swift中的WBLoadingIndicatorView动画封装技术
- dwz后台实例:全面展示dwz控件使用方法
- FoodCMS: 一站式食品信息和搜索解决方案
- 光立方制作教程:雨滴特效与呼吸灯效果
- mybatisTool高效代码生成工具包发布
- Android Graphics 绘图技巧与实践解析
- 1998版GMP自检评定标准的回顾与方法
- 阻容参数快速计算工具-硬件设计计算器
- 基于Java和MySQL的通讯录管理系统开发教程
- 基于JSP和JavaBean的学生选课系统实现
- 全面的数字电路基础大学课件介绍
- WagtailClassSetter停更:Hallo.js编辑器类设置器使用指南
- PCB线路板电镀槽尺寸核算方法详解
