BEiT:图像Transformer的BERT预训练
180 浏览量
更新于2024-06-21
收藏 13.58MB PDF 举报
"BEiT: BERT 预训练图像变换器PPT"
BEiT(BERT Pre-Training of Image Transformers)是一种新兴的预训练模型,它借鉴了自然语言处理领域非常成功的BERT(Bidirectional Encoder Representations from Transformers)的预训练策略,并将其应用到计算机视觉(CV)领域,特别是图像理解任务上。BEiT的目标是利用大量的未标注图像数据进行自监督学习,以生成强大的视觉表示,这些表示可以进一步用于各种下游的CV任务,如图像分类、目标检测等。
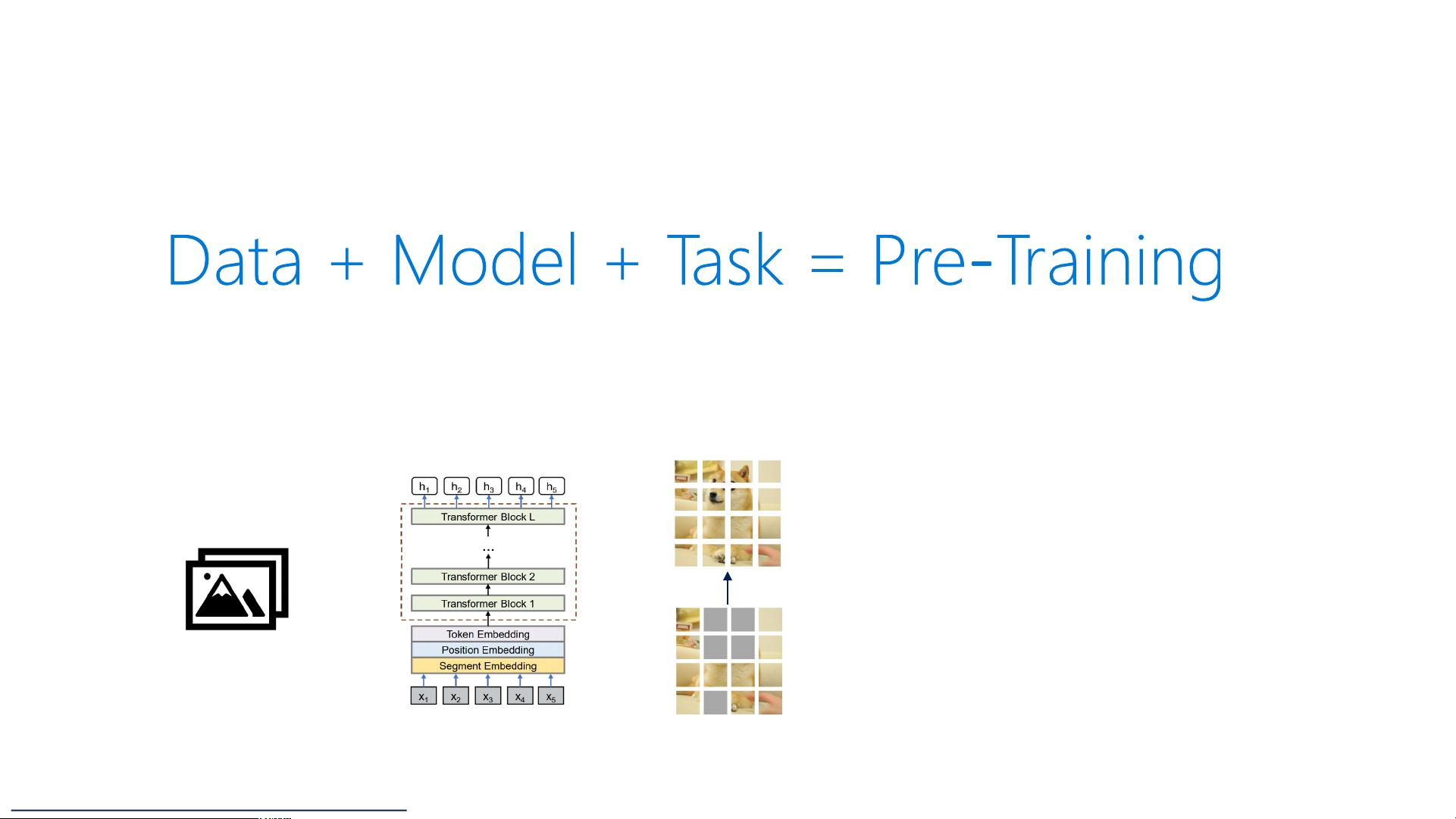
BEiT的工作原理与BERT类似,都是基于Transformer架构。在BERT中,模型通过预测被随机掩码的单词来学习语言的上下文表示。而在BEiT中,图像被转化为离散的视觉令牌,模型则需要预测这些令牌,这一过程称为“图像掩码语言模型”(Image Masked Language Modeling)。这种预训练方法使模型能够捕捉到图像的全局结构和语义信息,而无需依赖任何人工标注的数据。
预训练模型已成为人工智能领域的新范式,尤其在自监督学习(self-supervised learning)的推动下。预训练模型在大量无标注数据上进行训练,形成通用的特征表示,然后针对特定任务进行微调。这种方法极大地降低了对每个任务特定标签数据的依赖,甚至在少量或零样本标注的情况下也能取得良好的效果。
过去一年的关键词包括更大的模型(如WuDao2.0和M6)、混合专家模型(Mixture-of-Experts, MOE)以及密集模型。这些发展表明,Transformer架构正逐渐成为跨领域的标准骨干网络,涵盖了自然语言处理(NLP)、计算机视觉(CV)、语音识别等多个AI领域。同时,自我监督的预训练任务也在不同模态间融合,例如从语言到视觉、音频的生成。
随着技术的发展,多模态预训练模型正在涌现,它们能够处理多种类型的数据,如文本、图像和声音,以实现更加综合和智能的应用。BEiT作为这一趋势的一部分,展示了预训练模型在CV领域的巨大潜力,有望推动计算机视觉领域向更少依赖标注数据、更多依赖模型泛化能力的方向发展。未来,BEiT和类似方法可能会促进跨领域的AI模型进一步融合,从而在更多的应用中实现更好的性能。
剩余24页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-05-17 上传
2021-06-11 上传
2024-02-24 上传


迪菲赫尔曼
- 粉丝: 8w+
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
