Transformer在视觉识别中的预训练进展
需积分: 45 66 浏览量
更新于2024-08-05
收藏 1.7MB PPTX 举报
"这篇资源主要讨论的是在计算机视觉领域中,Vision Transformer的预训练方法,特别是自监督学习的应用。文章提到了多个研究工作,包括如何有效地训练Transformer模型,以及利用知识蒸馏和数据效率优化的方法。"
在计算机视觉(CV)领域,Transformer模型的引入是一个重大的突破。传统上,卷积神经网络(CNNs)是处理图像任务的主要工具,但Google的研究人员在ICLR 2021发表的文章《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》中,首次大规模地展示了纯Transformer在CV任务中的潜力。他们证明了Transformer不仅能够处理序列数据,同样也能有效处理图像数据,尤其是在大规模数据集JFT-300M上的表现。
然而,Transformer模型在CV领域的训练通常需要大量的数据,这带来了训练的困难。为了解决这个问题,Facebook AI在ICML 2020年提出了Data-efficient image Transformers (DeiT)。DeiT通过引入类标记(class token)和蒸馏标记(distillation token),并应用知识蒸馏技术,使得模型能在相对较小的数据集如ImageNet上进行训练,减少了对大量数据的依赖。
另一篇ICML 2020的工作《Generative Pretraining from Pixels》探讨了从像素级别进行生成式预训练的可能性。研究者通过k-means聚类将像素值离散化,然后使用自回归或BERT目标函数进行无监督训练。这种方法降低了图像分辨率,将二维图像转换为一维输入,创新性地探索了无监督学习的路径。
在ICLR 2022年的BEiT(BERT Pre-Training of Image Transformers)中,研究人员转向了图像补丁(patches)级别的预训练,通过类似BERT的预训练策略,为图像Transformer建立了一个像素级别的编码框架。与之对比,另一篇由Kaiming等人提出的工作,采用了不同的图像处理方式,通过移除部分补丁来节省计算资源。
此外,PeCo(Perceptual Codebook for BERT Pre-training of Vision Transformers)是由中国科学技术大学和微软合作的研究,其出发点是传统的像素级方法难以捕捉到语义信息。因此,PeCo引入了感知码本(perceptual codebook),以捕获更高级别的语义特征,从而改进了Vision Transformer的预训练效果。
这些研究都集中在提升Transformer在计算机视觉任务中的性能,通过自监督学习、数据效率优化、像素或补丁级别的编码等策略,逐步克服了Transformer在CV领域的训练难题,并为后续的模型设计提供了新的思路和方向。
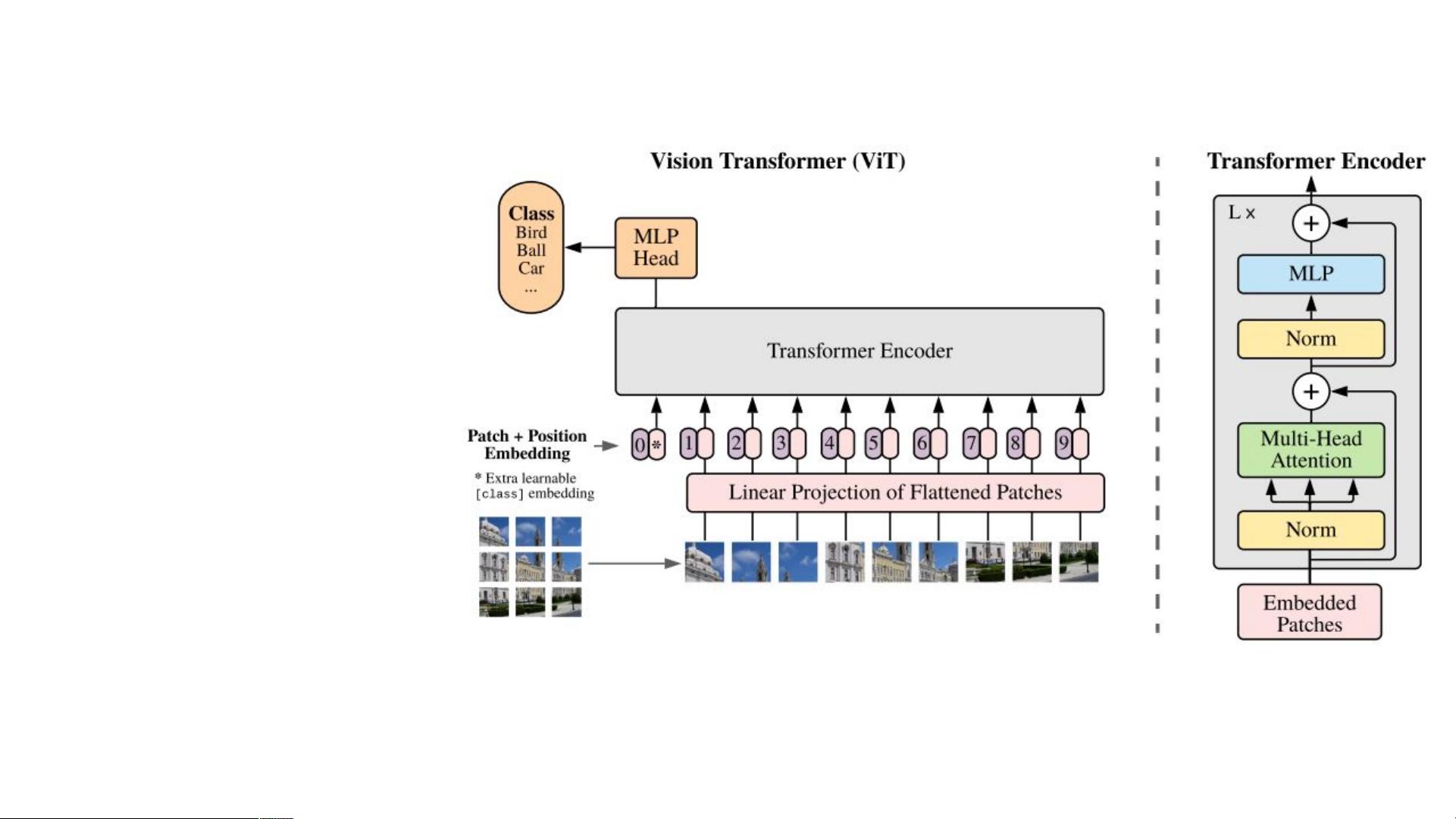
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale ( Google 发表在 ICLR
2021 )
第一次大规模的采用纯
transformer 做 cv 任务的文章,
验证了 transformer 在 cv 领域
的有效性,大大的挖坑之作
hard to train+ 使用谷歌私有数据集 JFT-300M
剩余13页未读,继续阅读
7267 浏览量
1328 浏览量
3922 浏览量
215 浏览量
788 浏览量
221 浏览量
369 浏览量
179 浏览量

DeepWWJ
- 粉丝: 98
 我的内容管理
展开
我的内容管理
展开







最新资源
- 革新操作体验:无需最小化按钮的窗口快速最小化工具
- VFP9编程实现EXCEL操作辅助软件的使用指南
- Apache CXF 2.2.9版本特性及资源下载指南
- Android黄金矿工游戏核心逻辑揭秘
- SQLyog企业版激活方法及文件结构解析
- PHP Flash投票系统源码及学习项目资源v1.2
- lhgDialog-4.2.0:轻量级且美观的弹窗组件,多皮肤支持
- ReactiveMaps:React组件库实现地图实时更新功能
- U盘硬件设计全方位学习资料
- Codice:一站式在线笔记与任务管理解决方案
- MyBatis自动生成POJO和Mapper工具类的介绍与应用
- 学生选课系统设计模版与概要设计指南
- radiusmanager 3.9.0 中文包发布
- 7LOG v1.0 正式版:多元技术项目源码包
- Newtonsoft.Json.dll 6.0版本:序列化与反序列化新突破
- Android实现SQLite数据库高效分页加载技巧
