文本分类基础:向量空间模型与特征选择
"文本分类是自然语言处理领域的一个基础任务,主要目标是将文本自动归类到预定义的类别中。对于初学者来说,理解文本分类的流程和关键概念至关重要。本文将概述文本分类的基本步骤,包括向量空间模型、特征选择和特征加权,并介绍几种常见的特征选择算法。
文本分类流程通常包括以下步骤:数据预处理、特征提取、特征选择、训练分类器以及测试和评估。预处理涉及清洗文本,去除无关字符,进行词干提取或词形还原等。特征提取则是将文本转化为数值形式,常用的方法是向量空间模型。
向量空间模型是将文本转化为向量的一种方式,其中每个文本被表示为一个特征项的二元特征向量。每个特征项ti对应一个权重wi,特征空间的大小为n。例如,文本d可以用一个向量来表示,其中每个元素代表一个特征项的出现情况。计算文本之间的相似度,可以通过计算向量的内积或夹角余弦值等方法。
特征选择是降低维度和减少噪声的关键步骤,目的是选取最具区分性的特征子集。常见的特征选择算法包括:
1. 信息增益(Information Gain, IG):衡量特征对分类的重要性,通过比较特征出现前后的熵变化来评估。但它可能过于重视罕见特征。
2. 期望交叉熵(Expected Cross Entropy):相比于信息增益,它不考虑未发生的单词,有时在分类精度上表现更好。
3. χ2(卡方检验)统计:这是一种监督特征选择方法,与信息增益相当,有时效果更优。
特征加权是对特征的重要性进行量化,常用的方法包括TF-IDF(词频-逆文档频率),它结合了词频和文档中出现的频率,强调在少数文档中频繁出现的词汇。
在实际应用中,例如有一个包含“经济”和“发展”这两个特征的系统,通过卡方检验选出的特征,我们可以为这些特征分配权重,以提高分类器的性能。分类器的训练和评估是整个流程的最后阶段,常见的分类器有朴素贝叶斯、支持向量机和深度学习模型如卷积神经网络(CNN)和双向循环神经网络(BiLSTM)等。
文本分类是通过将文本转化为可计算的向量表示,然后利用特征选择和加权来优化模型性能,最终训练出能够准确预测文本类别的模型。理解并掌握这些基础知识对于深入学习文本处理和自然语言理解至关重要。"
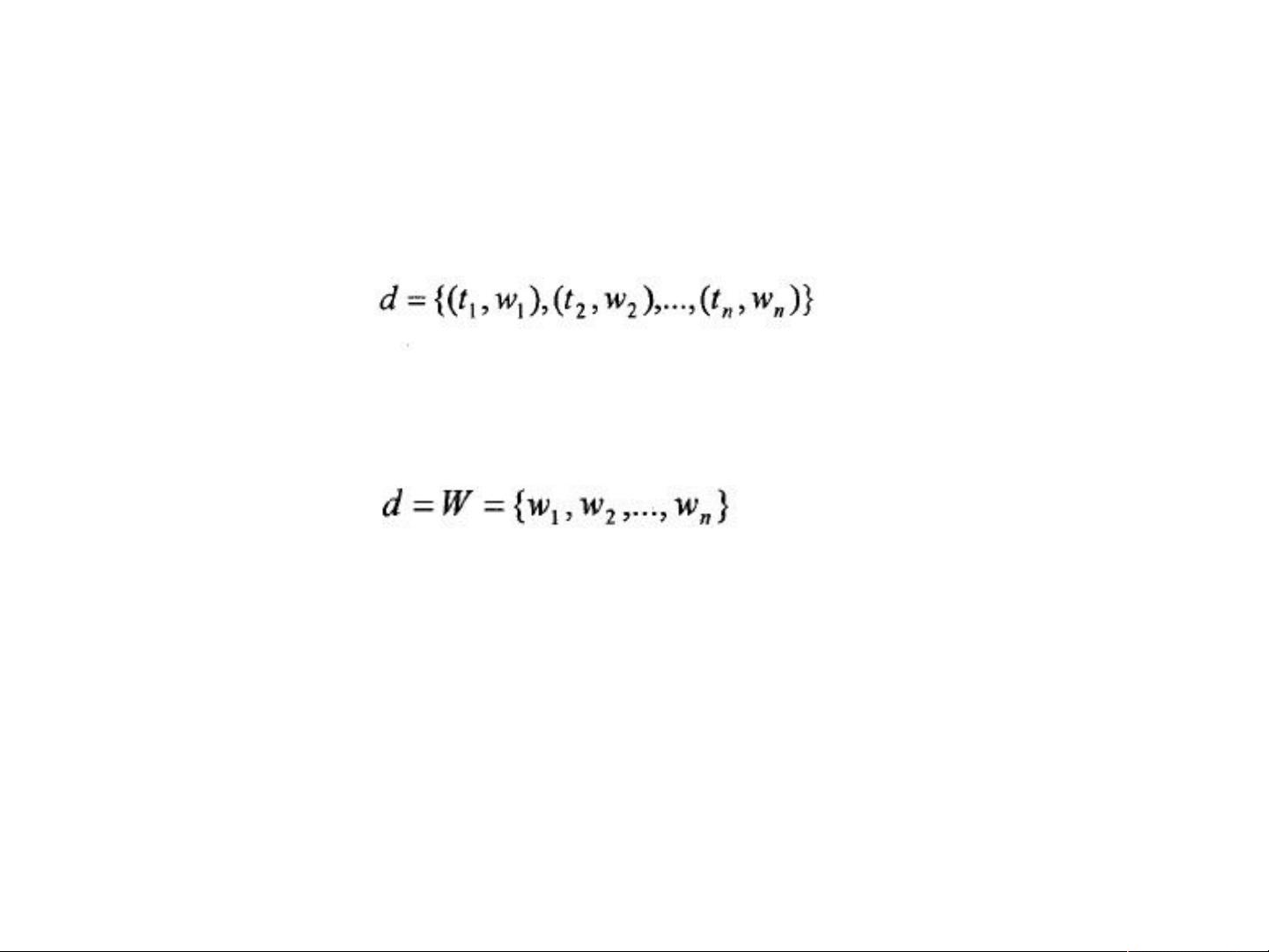
3/12
向量空间模型
•
本文 d 被看成由二元特征组组成的特征向量,表示如下
•
其中 t
i
为 d 中的特征项, w
i
为 t
i
对应的权重, n 为特征空间的大小。
•
当数据集中的特征空间确定时,每个特征项对应于特征空间中的一个点,则
公式可以简化表示为公式
•
此时计算两个文本 d1 , d2 的相似度的问题便转换为计算两个特征向量间某
种距离的问题,如向量内积、夹角余弦值等。
剩余11页未读,继续阅读
205 浏览量
2014-02-22 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

Tianzhenzi
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
