分布式事务详解:保证数据一致性
版权申诉
185 浏览量
更新于2024-08-04
收藏 248KB DOCX 举报
"分布式事务学习资料-V1.0.docx"
分布式事务是解决现代大型分布式系统中数据一致性问题的关键技术。在分布式环境中,事务的参与者、服务支持、资源服务器及事务管理器分散在不同的网络节点上。一次完整的操作可能涉及多个子操作,这些子操作跨越不同的服务器和应用程序。分布式事务的目标是确保这些子操作要么全部成功执行,要么全部回滚,以保持数据的一致性。
分布式事务的产生主要源于两个方面:首先,数据库的分库分表策略。当单个数据库表的数据量过大时,通常会采用分库分表来提升性能和可扩展性。然而,这导致了数据分布在多个数据库中,需要分布式事务来确保跨库操作的一致性。其次,随着业务的复杂性和规模的增长,系统往往会被拆分为多个服务,如订单中心、用户中心和库存中心,每个服务都有自己的数据库。在这种SOA(面向服务架构)设计下,分布式事务成为保证各服务间数据一致性的必要手段。
事务的ACID特性是分布式事务的核心原则:
1. 原子性(Atomicity):事务中的所有操作被视为一个不可分割的整体,要么全部完成,要么全部回滚,不允许部分完成。
2. 一致性(Consistency):事务执行后,系统必须保持一致性状态,例如转账操作必须确保转账前后账户总额不变。
3. 隔离性(Isolation):事务在执行过程中与其他事务隔离,避免相互干扰,确保并发执行时的正确性。
4. 持久性(Durability):一旦事务提交,其对数据的更改将永久保存,不受系统故障影响。
在电商系统中,分布式事务的应用场景非常广泛,例如:
1. 支付过程:买家扣款和卖家收款必须在同一事务内完成,确保资金转移的准确无误。
2. 库存更新:当用户下单购买商品时,需要同时减少库存并创建订单,这两个操作必须在同一个事务中执行,防止超卖或库存计算错误。
3. 用户积分操作:用户购物、评论等行为可能涉及积分增减,这些操作需要在分布式事务中同步处理,确保积分的正确计算。
实现分布式事务的方法有很多,常见的有两阶段提交(2PC)、三阶段提交(3PC)、补偿事务(TCC)、 Saga模式、最终一致性等。每种方法都有其优缺点,需要根据系统的特定需求和性能要求来选择合适的解决方案。例如,2PC简单但可能导致长时间锁定资源;TCC和Saga模式则更加灵活,但实现复杂度较高;最终一致性适用于对强一致性要求不高的场景,能够容忍短暂的数据不一致。
分布式事务是构建大规模分布式系统时不可或缺的一部分,它确保了数据在复杂的网络环境中的准确性和一致性,为业务的正常运行提供了坚实的基础。理解和掌握分布式事务的原理及其应用,对于IT专业人士来说至关重要。
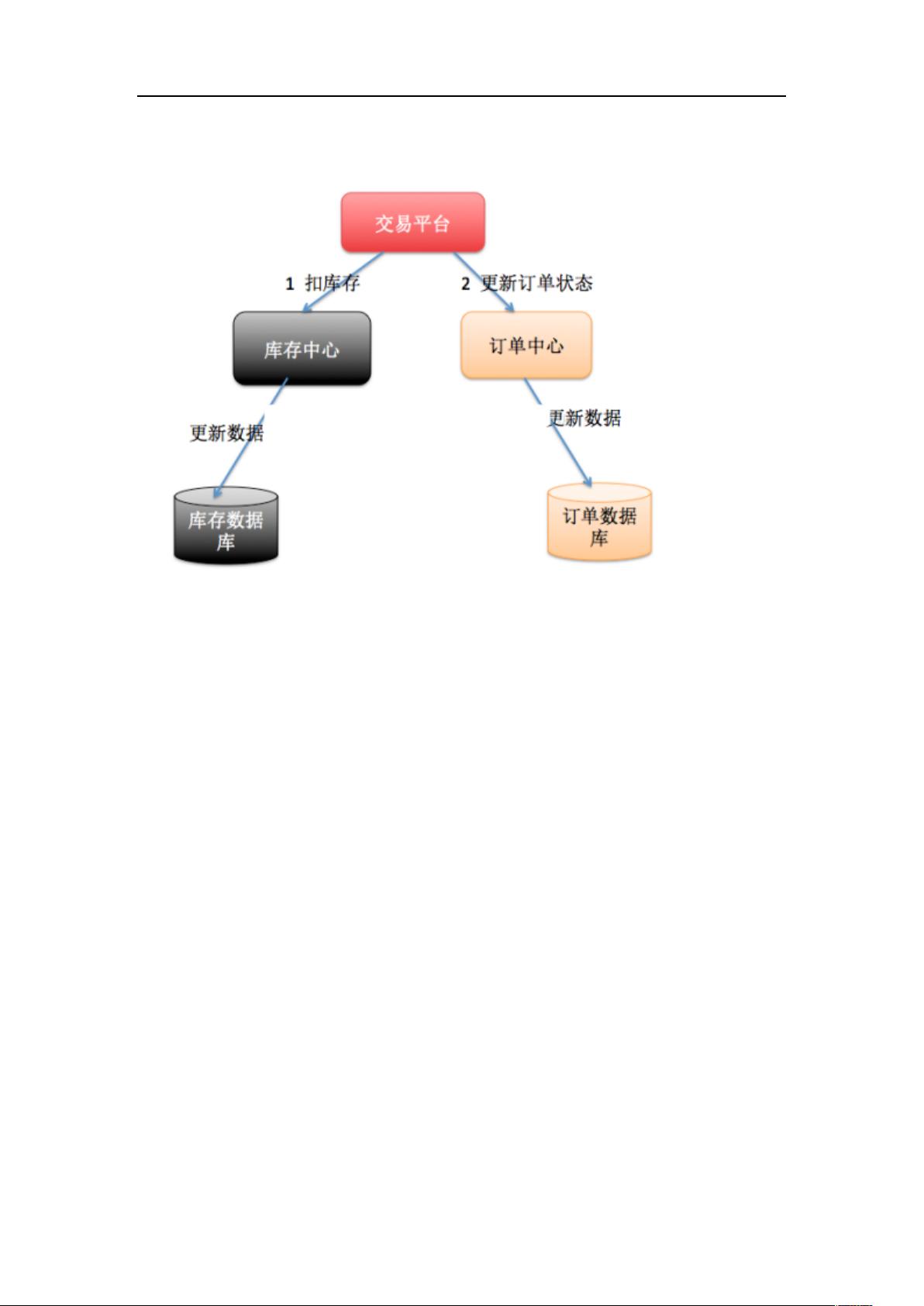
储库存信息。这时候如果要同时对订单和库存进行操作,那么就会涉及到订单数据库和库存
数据库,为了保证数据一致性,就需要用到分布式事务。
1.3 事务的 ACID 特性
1.3.1 原子性(A)
所谓的原子性就是说,在整个事务中的所有操作,要么全部完成,要么全部不做,没有
中间状态。对于事务在执行中发生错误,所有的操作都会被回滚,整个事务就像从没被执行
过一样。
1.3.2 一致性(C)
事务的执行必须保证系统的一致性,就拿转账为例,A 有 500 元,B 有 300 元,如果在
一个事务里 A 成功转给 B50 元,那么不管并发多少,不管发生什么,只要事务执行成功了,
那么最后 A 账户一定是 450 元,B 账户一定是 350 元。
1.3.3 隔离性(I)
所谓的隔离性就是说,事务与事务之间不会互相影响,一个事务的中间状态不会被其他
事务感知。
剩余13页未读,继续阅读
2024-01-30 上传
2024-01-30 上传
2024-01-30 上传
2024-01-30 上传
2024-01-30 上传
2024-01-31 上传
2024-01-30 上传
2024-01-30 上传
2024-01-30 上传

小小哭包
- 粉丝: 2089
- 资源: 4286
 我的内容管理
展开
我的内容管理
展开







最新资源
- servlet动态生成登陆验证图片
- 线性代数 第四版 同济大学
- Essential MATLAB for Engineers and Scientists 3nd
- 视频捕获 之 如何使用系统设备枚举器
- Java Persistence with Hibernate
- DirectShow编程捕捉WDM与VFW
- 全国计算机等级考试南开100题分类版
- Linux网络编程.pdf
- 经典C程序100例--Doc整理版
- 周立功公司的I2C协议标准中文
- 应急通信网络管理论文
- geoserver-openlayer.doc
- 程序员的十层楼 网上流传 思想很有高度
- 获取系统图标解决方案
- 555定时器数字钟设计
- Gps开发资料 MTK系列芯片的设置指令
