HBase:大数据时代的列存储数据库
需积分: 16 192 浏览量
更新于2024-07-23
收藏 606KB PDF 举报
"对HBase进行了概要分析,讨论了其历史、特性和在Hadoop生态系统中的位置,以及逻辑视图中的表结构和RowKey设计原则。"
HBase是一种开源的分布式列式数据库,源于Google的BigTable论文,自2006年开始发展,成为Apache Hadoop项目的一个子项目。它构建于HDFS(Hadoop Distributed File System)之上,旨在提供高可靠性和高性能的数据存储解决方案,尤其适合处理非结构化和半结构化的松散数据。HBase的设计理念是通过水平扩展来提升存储和计算能力,即通过添加更多的商用服务器。
在Hadoop生态系统中,HBase扮演着关键角色,位于HDFS和MapReduce之上,提供了实时读写和基于主键的高效数据访问。HBase的表非常大,可能包含上亿行和上百万列,而且这些表是面向列的,允许列族的独立存储和检索,并且具有稀疏性,空值不占用存储空间。
在逻辑视图下,HBase的数据组织成表格形式,由行和列族构成。RowKey是检索记录的关键,它必须是唯一的,并且决定了数据的物理存储顺序。用户可以通过三种方式访问数据:单个RowKey、RowKey范围或全表扫描。RowKey设计至关重要,通常为10-100字节的字符串,内部以字节数组存储并按字典序排序。为了优化查询性能,应确保经常一起读取的行具有相似的RowKey,以便利用字典序排序的特性。
在使用HBase时,还需要注意RowKey设计的其他因素,例如避免使用可能导致反常排序的类型(如整数),因为"1", "10", "100"等在字典序中排序可能会产生非预期结果。此外,由于HBase仅支持单行事务,如果需要多表JOIN等复杂操作,可以通过集成Hive等工具来实现。
HBase是一种强大的NoSQL数据库,适用于大规模数据处理,尤其在需要快速访问和列式存储的场景下。理解和掌握HBase的原理和最佳实践对于构建高效的大数据解决方案至关重要。
置。
Cell
由
{row key, column(
=<family> + <label>
), version}
唯一确定的单元。 cel l
中的数据是没有类型的,全部是字节码形式存贮。
三、物理存储
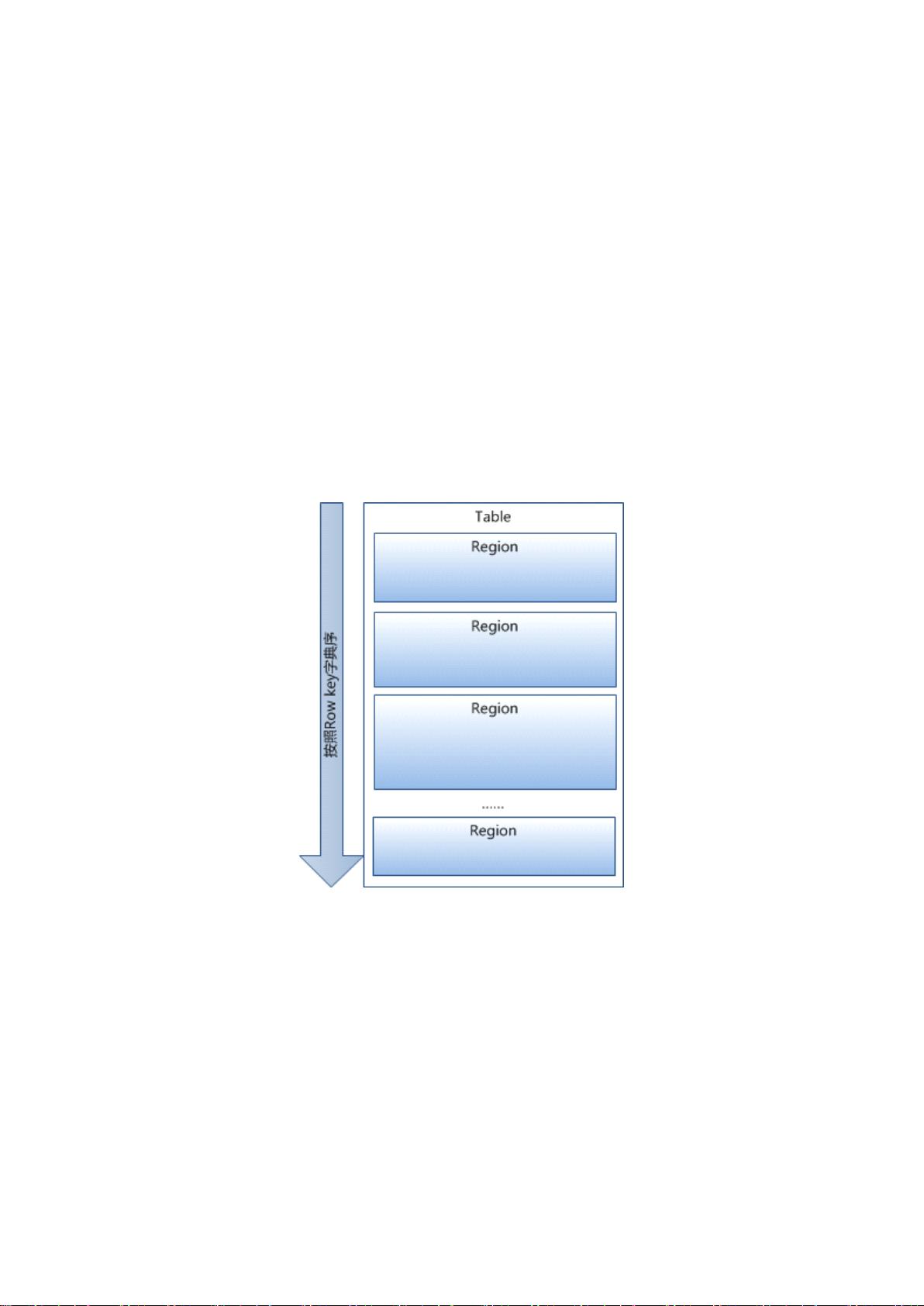
1 已经提到过, Table 中的所有行都按照 row key 的字典序排列。
2 Table 在行的方向上分割为多个 Hregion 。
3 region 按大小分割的,每个表一开始只有一个 region ,随着数据不断
插入表 , region 不断增大 , 当增大到一个阀值的时候 , Hregion 就会等分
会两个新的 Hregion 。当 table 中的行不断增多,就会有越来越多 的
Hregion 。
剩余16页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-04-20 上传
2016-03-09 上传
2018-05-31 上传
2023-08-30 上传
2021-09-29 上传
2021-09-30 上传

仲夏夜有蚊子
- 粉丝: 16
- 资源: 25
 我的内容管理
展开
我的内容管理
展开







最新资源
- AutoJs源码-打开悬浮窗看脚本那三条线的BUG
- Aide aux commentaires WattPad-crx插件
- PC 微信防撤回插件 适用3.9.10.19
- 变频器说明书大全系列-CVP.rar
- 行业分类-外包设计-支撑件传递模的介绍分析.rar
- 昆虫小动物图标下载
- Cpp-How-To-Program-9E:移至GITLAB
- 数学建模与数学实验课件14讲含源程序-第5讲 无约束优化.zip
- 基于图像超分的相机标定优化方法.zip
- bill-birthday
- 行业分类-外包设计-折叠式塑料包装箱的介绍分析.rar
- 打印图标免费下载
- 网格六边形图案svg特效
- ASP实例开发源码-百度最近收录查询asp版.zip
- react-native-typescript-starter
- SA400S37固态硬盘固件通病 群联固态 PS3111主控 SSD修复工具
