Elasticsearch查询优化:理解Search的Query-Then-Fetch策略与相关性算分
93 浏览量
更新于2024-08-30
收藏 928KB PDF 举报
在深入理解Elasticsearch搜索的运行机制时,我们首先要了解搜索过程分为两个关键阶段:Query阶段和Fetch阶段。这两个阶段构成了Query-Then-Fetch的基本工作流程。
Query阶段是搜索过程的初始步骤,它负责解析和执行用户的查询请求,包括语法解析、查询条件的处理以及构建查询计划。在这个阶段,Elasticsearch会对查询进行优化,如词法分析、解析查询语法、构建查询树等,以便有效地找到相关的文档。
Fetch阶段则是在Query阶段筛选出候选文档后,进一步从每个Shard中实际读取数据。在这个阶段,每个Shard独立计算文档的相关性得分,但存在一个问题:由于IDF值(逆文档频率)在不同Shard上可能不一致,当文档量较少时,可能导致相关性得分不准确。这可能导致搜索结果偏离预期,尤其是在百万到千万级别文档量的场景下。
解决这个问题有两种策略:
1. 设置单个分片:当文档量较小,为了确保相关性得分的一致性,可以将分片数设为1,这样可以避免跨Shard的相关性差异。然而,这将牺牲水平扩展能力,并可能在高并发情况下性能下降。
2. 使用DFS Query-then-Fetch:这是一种特殊的查询方式,它会在所有文档被收集后,在内存中重新计算整个文档集合的相关性得分。这种方法虽然可以提供更准确的结果,但代价是消耗大量的CPU和内存资源,导致性能较低,因此在大多数情况下并不推荐使用。用户可以自定义排序规则,例如针对text和keyword类型的排序,其中text类型排序依赖于正排索引,而keyword类型则可以直接利用存储的原始值。
Elasticsearch提供了三种排序实现方式:默认的排序基于相关性得分,但用户可以调整;`fielddata`允许按分词后的term排序,适用于聚合分析;`docvalues`是默认启用的,提供更快的排序速度,但文本类型除外。若需切换到`docvalues`,可能需要重新索引。通过这些选项,开发者可以根据具体需求选择最合适的排序策略来优化搜索性能和结果质量。
Elasticsearch之深入了解之深入了解Search的运行机制的运行机制
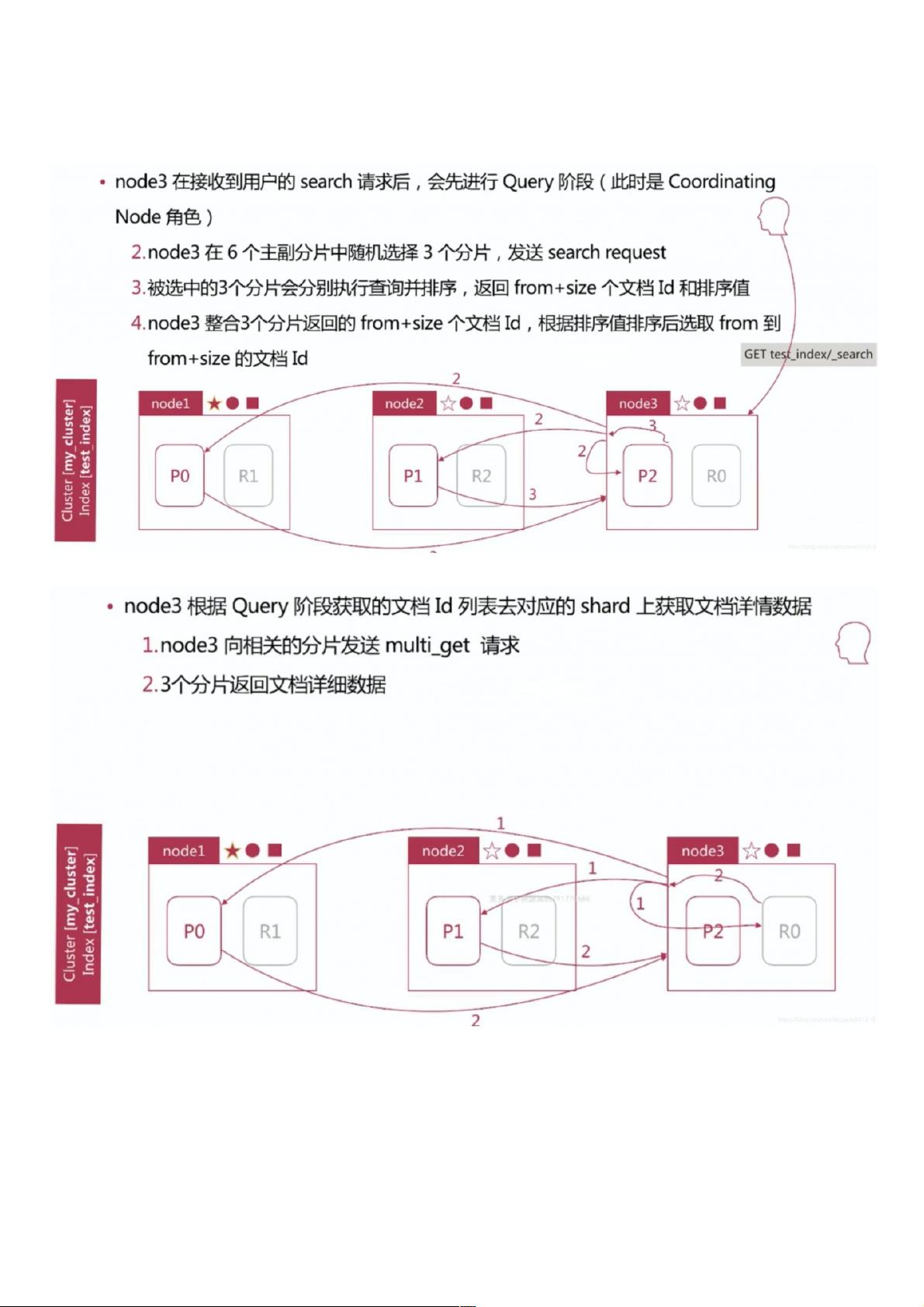
Search 执行的时候实际分两个步骤运作的
– Query 阶段
– Fetch 阶段
Query-Then-Fetch
Query阶段阶段
Fetch阶段阶段
相关性算分问题相关性算分问题
相关性算分在shard与shard间是相互独立的,也就意味着同一个term的IDF值在不同shard上是不同的。文档的相关性算分和他所处的shard相关
在文档数量不多是,会导致相关性算分严重不准的情况发生
解决思路有两个:
– 一是设置分片数为1个,从根本上排除问题,在问当数量不多的时候可以考虑该方案,比如百万到千万级别的文档数量
– 二是使用 DFS Query-then-Fetch 查询方式
– DFS Query-then-Fetch 是在拿到所有文档后再重现完整的计算一次相关性算分,耗费更多的cpu和内存,执行新能底下,一般不建议使用。使用方式如下:
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
2024-07-18 上传
2021-05-02 上传
2021-03-12 上传
2019-08-07 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38671048
- 粉丝: 4
- 资源: 870
 我的内容管理
展开
我的内容管理
展开







最新资源
- equation_database
- Image to EPUB3-crx插件
- android-ColorPickerPreference-master.zip项目安卓应用源码下载
- tuxedo_test,易语言源码转换c代码,c语言项目
- 投资组合:我的投资组合网站,如果需要请检查!
- Escrever-e-ler-arquivo-txt:Abrir o arquivo“ data.txt”,格劳瓦·奥勒·达斯和费加尔·阿基沃
- [信息办公]PHP在线考试系统PPExam 1.3.2_ppframe.rar
- jTree:jTree是一个小型jQuery插件,可帮助您从JSON对象构建良好的干净,可排序和可选的文件树结构
- 虚拟现实地形建模:在虚拟现实工具箱中使用实际地形数据。-matlab开发
- PetsCitizens
- 带有单词的GUI
- antlr-test
- e-Varisto-crx插件
- Python库 | pycodestyle-2.7.0.tar.gz
- Scratch少儿编程项目音效音乐素材-【打斗】音效-刀剑类.zip
- PRC公交网IP查询系统PHP版 v1.0_prc_chaip_工具查询网站开发模板(使用说明+PHP源代码+html).zip
