剖析Hadoop DateNode:目录结构与类继承详解
PDF格式 | 218KB |
更新于2024-08-28
| 200 浏览量 | 举报
在Hadoop源码分析中,DateNode是Hadoop分布式文件系统(HDFS)架构中的关键组件之一,它主要负责数据的存储和副本管理。在深入研究NameNode启动流程之前,理解DateNode的目录构成与类继承结构至关重要,因为它们直接影响数据节点的运行和文件系统的稳定性。
DataNode的类继承结构主要关注与存储文件相关的功能,而不涉及数据交换的具体实现。其核心目录结构由`${dfs.data.dir}`属性定义,这个属性允许设置多个存储路径,通过逗号分隔,例如`"/data1/datanode,/data2/datanode"`,用于分散数据存储,提高数据的冗余和可靠性。
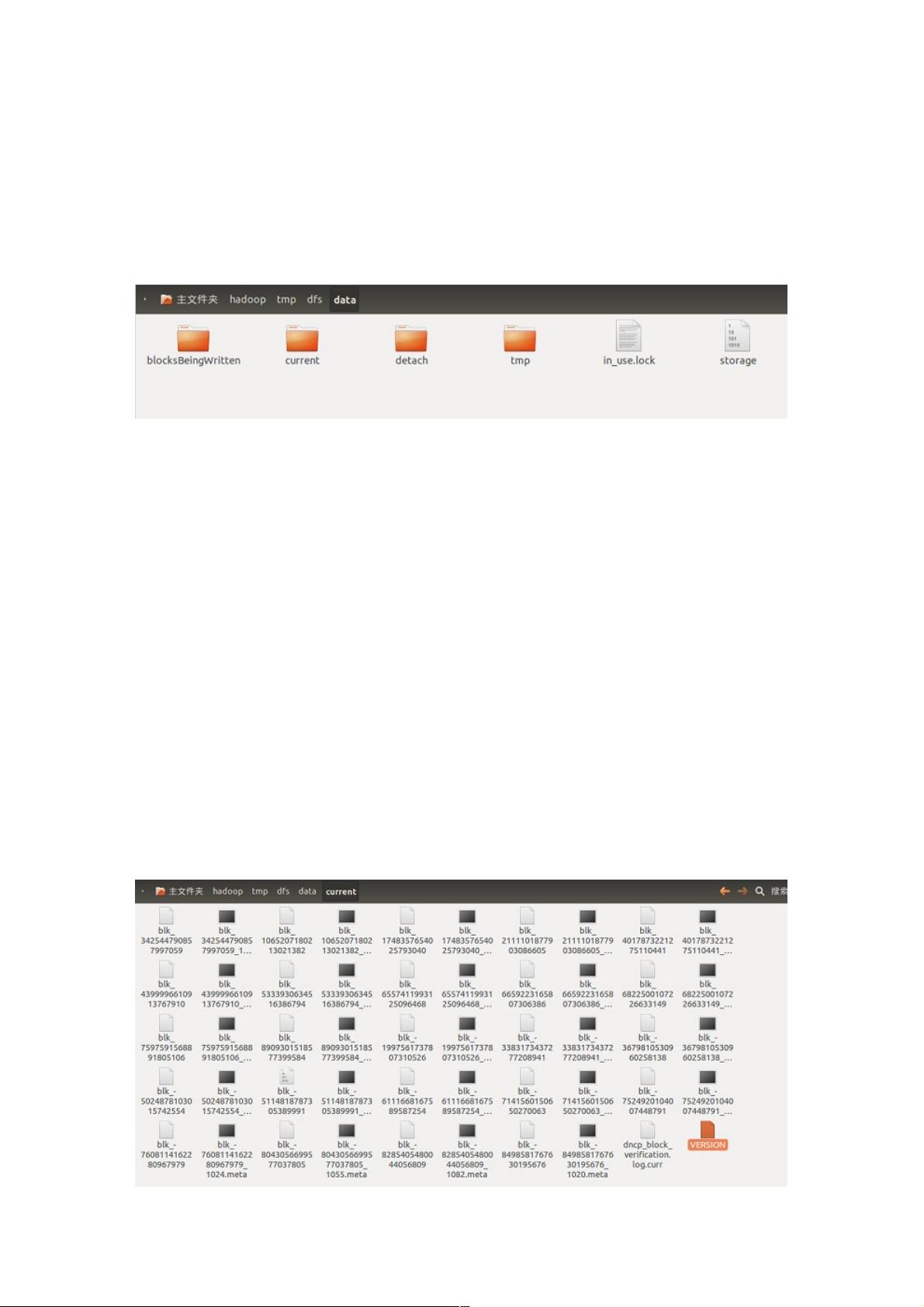
当`${dfs.data.dir}`没有被明确指定时,默认会创建一个名为`tmp`的临时目录,用于存储临时数据块。DataNode启动后,`${dfs.data.dir}`下的目录结构包括:
1. `blocksBeingWritten`:存储当前正在被写入的数据块,这些数据块可能还在处理中。
2. `current`:存放已成功提交到HDFS的数据块,是数据节点的核心存储区域,包含HDFS文件内容的块和元数据。
3. `detach`:用于数据节点升级期间的数据块分离操作,保存临时的工作文件。
4. `tmp`:与`blocksBeingWritten`类似,但写操作通常由数据块复制引发,而非客户端直接写入。
5. `storage`(在0.13版本之前使用,现已废弃):旧版本Hadoop的数据块存储目录,不兼容新结构,主要用于向后兼容。
在`current`目录中,文件分为两类:
- HDFS数据块:存储实际的文件内容。
- 其他辅助文件:包括元数据和用于管理数据块的文件,确保数据一致性。
`in_use.lock`文件是一个重要的同步机制,当DataNode启动时,如果该文件存在,表示目录已被占用,其他节点将不会尝试使用。当DataNode停止时,此文件会被删除,确保数据节点对存储目录的独占,避免数据冲突。
了解DateNode的目录结构和类继承结构对于理解和优化HDFS的性能、容错性和扩展性至关重要。在实际部署和维护过程中,正确配置这些参数和理解其工作原理,能够帮助我们更好地管理和利用Hadoop的分布式存储能力。
Hadoop源码分析之源码分析之DateNode的目录构成与类继承结构的目录构成与类继承结构
在继续分析NameNode启动之前,先看看DateNode与NameNode的目录构成与类继承结构,NameNode与DataNode的启动
过程与这些目录结构和类继承结构相关,在启动的过程中会检查目录的状态。这里所分析的类的继承结构是与存储文件相关的
类,与数据交换有关的类暂不考虑。
DataNode的文件目录结构
DataNode目录就是数据节点上存放与数据块相关数据的目录,由${dfs.data.dir}属性指定,这个属性可以指定多个值,值之间
使用逗号隔开,如“/data1/datanode,/data2/datanode”指定类两个目录来存放数据节点。如果不指定${data.data.dir}数据块将
会放在一个名为tmp的临时目录中,下文中就用${dfs.data.dir}代表数据节点的存储目录。DataNode启动之后${dfs.data.dir}目
录中有四个目录和两个文件,如下图所示。
其中in_use.lock文件是在DataNode节点启动之后产生的,其中各个目录的作用如下:
blocksBeingWritten:该文件夹保存着当前正在”写“的数据块。
current:保存着HDFS文件系统中的数据块,这些数据块是成功提交到HDFS中的数据块。detach:用于配合数据节点升级,
共数据块分离操作保存临时工作文件。
tmp:该文件夹保存着当前正在”写“的数据块,和blockBeingWritten文件夹的区别是,blockBeingWritten中的数据块写操作由
客户端发起,tmp中的写操作由数据块复制引发,另一个数据节点正在发送数据到数据块中。
storage:0.13版本以前的Hadoop使用storage文件作为数据块的保存目录,和现在的目录结构不兼容,这个文件用于防止过
旧的Hadoop版本在新的目录结构上启动,损坏系统。
in_use.lock:表明目录已经被使用,停止数据节点,该文件会消失,通过in_use.lock文件,数据节点可以保证独自占用该目
录,防止两个数据节点示例共享一个目录,造成混乱。
current目录是数据节点中最重要的一个目录,它用于存放数据块,该目录中既包含目录,也包含文件,其中文件有两种类
型:
HDFS数据块,保存着HDFS文件的内容;
用于保存数据块的校验信息的校验信息文件,以meta后缀名标识;
VERSION文件是一个Java属性文件,包含了HDFS的版本信息。
current目录如下图所示:
在这个图片中,没有目录,是因为当前的数据节点中的文件块的数量较少,只有当目录中存储的数据块增加到一定规模时,子
目录名以subdir为前缀,然后后面加上目录编号,数据节点会创建一个新目录,用于保存新的块及元数据。目录中的数据块数
达到64时,便会创建子目录,并形成一个更宽的目录结构,同时\统一父目录下最多会创建64个子目录,所以在默认配置下,
下载后可阅读完整内容,剩余6页未读,立即下载
相关推荐







weixin_38643141
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 免费教程:Samba 4 1级课程入门指南
- 免费的HomeFtpServer软件:Windows服务器端FTP解决方案
- 实时演示概率分布的闪亮Web应用
- 探索RxJava:使用RxBus实现高效Android事件处理
- Microchip USB转UART转换方案的完整设计教程
- Python编程基础及应用实践教程
- Kendo UI 2013.2.716商业版ASP.NET MVC集成
- 增强版echarts地图:中国七大区至省详细数据解析
- Tooloop-OS:定制化的Ubuntu Server最小多媒体系统
- JavaBridge下载:获取Java.inc与JavaBridge.jar
- Java编写的开源小战争游戏Wargame解析
- C++实现简易SSCOM3.2功能的串口调试工具源码
- Android屏幕旋转问题解决工具:DialogAlchemy
- Linux下的文件共享新工具:Fileshare Applet及其特性介绍
- 高等应用数学问题的matlab求解:318个源程序打包分享
- 2015南大机试:罗马数字转十进制数代码解析
