剖析Hadoop DateNode目录结构与类继承:数据节点存储详解
38 浏览量
更新于2024-08-28
收藏 218KB PDF 举报
在Hadoop源码分析中,DateNode与NameNode的目录构成与类继承结构是至关重要的部分,它们之间的交互与文件系统的运行密切相关。DataNode作为Hadoop分布式文件系统(HDFS)中的存储节点,其核心职责是管理数据块的存储和复制。DataNode的启动过程首先依赖于配置的${dfs.data.dir}属性,该属性允许指定多个数据存储路径,通过逗号分隔,如"/data1/datanode,/data2/datanode"。
DataNode启动后,其目录结构主要包括以下几个关键部分:
1. **blocksBeingWritten**:这个目录保存着正在进行写入操作的数据块,这些数据块是由客户端发起的。
2. **current**:这是数据块的主存储区域,存储已成功提交到HDFS的数据块。这些数据块对于文件系统的可用性和完整性至关重要。
3. **detach**:用于数据节点升级期间的临时工作文件,配合数据块分离操作进行文件管理。
4. **tmp**:与blocksBeingWritten类似,但这里的写操作通常由数据块复制引发,而不是客户端直接写入。
5. **storage**(0.13版本前):旧版本的Hadoop曾使用此目录作为数据块存储,但与现代目录结构不兼容,主要是为了兼容性考虑,避免新版本系统因旧结构损坏。
6. **in_use.lock**:这是一个锁文件,用来标记目录已被DataNode占用,防止多个实例同时使用同一目录,确保数据一致性。
current目录是DataNode的核心,它既是目录又是文件集合,包含HDFS数据块文件(存储文件内容)以及用于维护数据块元数据的辅助文件。理解这些目录和类的结构以及它们之间的关系有助于深入理解Hadoop的数据存储和复制机制,尤其是在集群管理、故障恢复和性能优化方面。在继续分析NameNode启动时,这些知识点将为后续的代码剖析提供基础,因为它们共同构成了Hadoop分布式文件系统的核心组件交互。
Hadoop源码分析之源码分析之DateNode的目录构成与类继承结构的目录构成与类继承结构
在继续分析NameNode启动之前,先看看DateNode与NameNode的目录构成与类继承结构,NameNode与DataNode的启动
过程与这些目录结构和类继承结构相关,在启动的过程中会检查目录的状态。这里所分析的类的继承结构是与存储文件相关的
类,与数据交换有关的类暂不考虑。
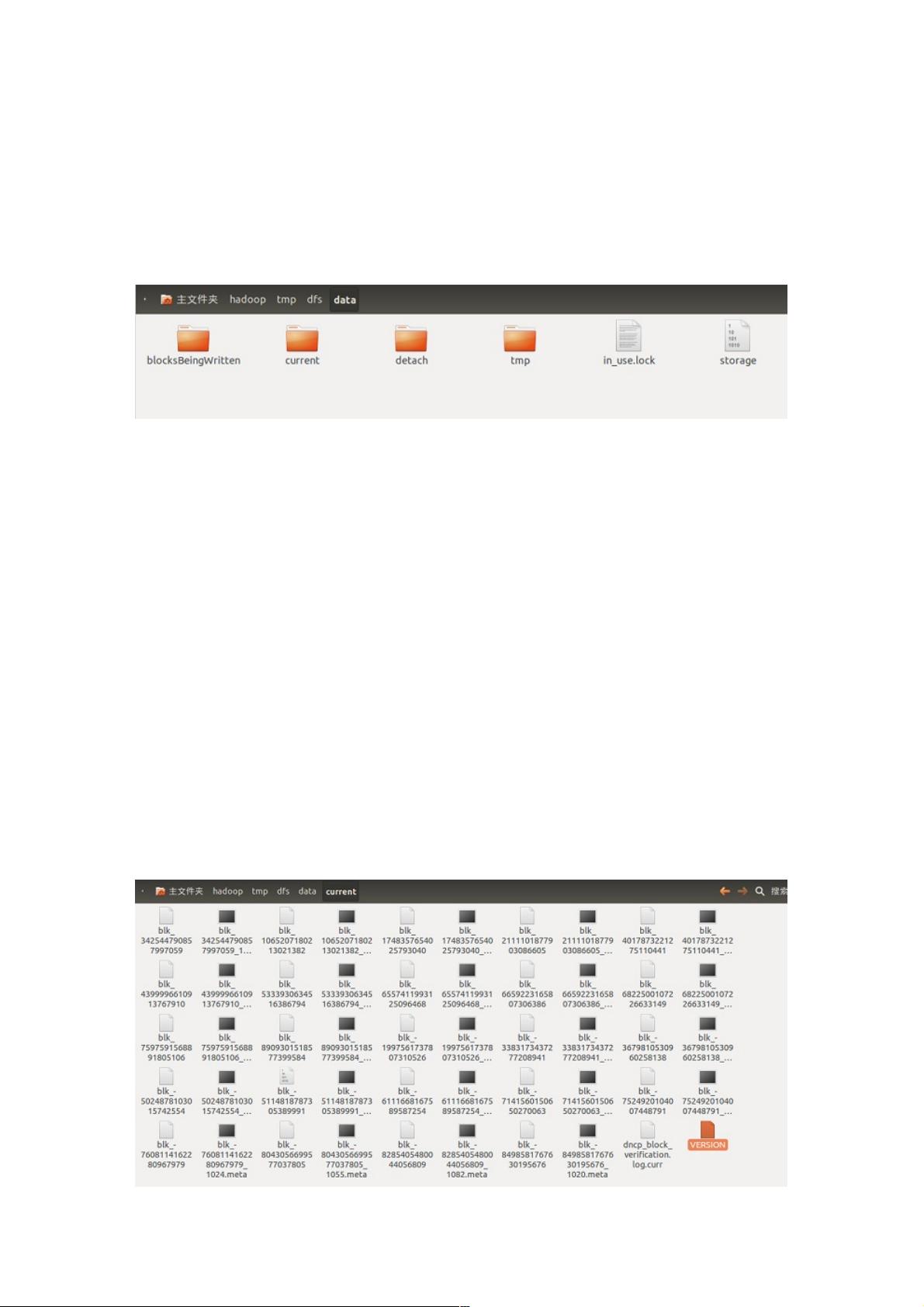
DataNode的文件目录结构
DataNode目录就是数据节点上存放与数据块相关数据的目录,由${dfs.data.dir}属性指定,这个属性可以指定多个值,值之间
使用逗号隔开,如“/data1/datanode,/data2/datanode”指定类两个目录来存放数据节点。如果不指定${data.data.dir}数据块将
会放在一个名为tmp的临时目录中,下文中就用${dfs.data.dir}代表数据节点的存储目录。DataNode启动之后${dfs.data.dir}目
录中有四个目录和两个文件,如下图所示。
其中in_use.lock文件是在DataNode节点启动之后产生的,其中各个目录的作用如下:
blocksBeingWritten:该文件夹保存着当前正在”写“的数据块。
current:保存着HDFS文件系统中的数据块,这些数据块是成功提交到HDFS中的数据块。detach:用于配合数据节点升级,
共数据块分离操作保存临时工作文件。
tmp:该文件夹保存着当前正在”写“的数据块,和blockBeingWritten文件夹的区别是,blockBeingWritten中的数据块写操作由
客户端发起,tmp中的写操作由数据块复制引发,另一个数据节点正在发送数据到数据块中。
storage:0.13版本以前的Hadoop使用storage文件作为数据块的保存目录,和现在的目录结构不兼容,这个文件用于防止过
旧的Hadoop版本在新的目录结构上启动,损坏系统。
in_use.lock:表明目录已经被使用,停止数据节点,该文件会消失,通过in_use.lock文件,数据节点可以保证独自占用该目
录,防止两个数据节点示例共享一个目录,造成混乱。
current目录是数据节点中最重要的一个目录,它用于存放数据块,该目录中既包含目录,也包含文件,其中文件有两种类
型:
HDFS数据块,保存着HDFS文件的内容;
用于保存数据块的校验信息的校验信息文件,以meta后缀名标识;
VERSION文件是一个Java属性文件,包含了HDFS的版本信息。
current目录如下图所示:
在这个图片中,没有目录,是因为当前的数据节点中的文件块的数量较少,只有当目录中存储的数据块增加到一定规模时,子
目录名以subdir为前缀,然后后面加上目录编号,数据节点会创建一个新目录,用于保存新的块及元数据。目录中的数据块数
达到64时,便会创建子目录,并形成一个更宽的目录结构,同时\统一父目录下最多会创建64个子目录,所以在默认配置下,
下载后可阅读完整内容,剩余6页未读,立即下载
773 浏览量
2016-09-09 上传
点击了解资源详情
点击了解资源详情
107 浏览量
2012-04-17 上传
2023-06-28 上传
2024-11-21 上传

weixin_38730201
- 粉丝: 5
- 资源: 922
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
