
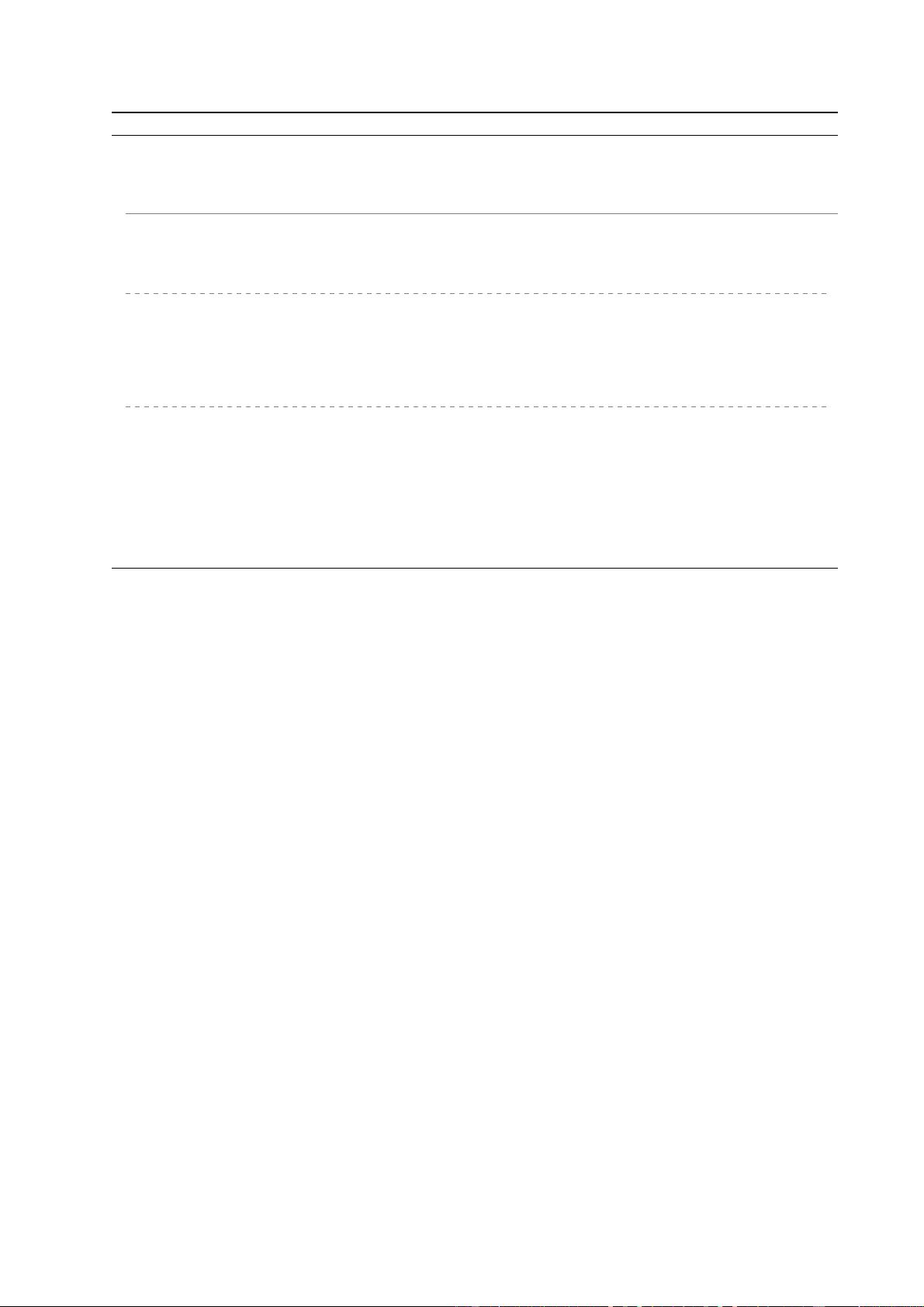
Algorithm 1 Classic Cache Channel Protocol
Cache[N]: A shared processor cache, conceptually divided into N regions;
Cache[N]: Each cache region can be put in one of two states, cached or flushed.
D
Send
[N], D
Recv
[N]: N bit data to transmit and receive, respectively.
Sender Operations: Receiver Operations:
(Wait for receiver to initialize the cache)
for i := 0 to N − 1 do
{Put Cache[i] into the cached state}
Access memory maps to Cache[i];
end for
for i := 0 to N − 1 do
if D
Send
[i] = 1 then
{Put Cache[i] into the flushed state}
Access memory maps to Cache[i];
end if
end for
(Wait for sender to prepare the cache)
(Wait for receiver to read the cache)
for i := 0 to N − 1 do
Timed access memory maps to Cache[i];
{Detect the state of Cache[i] by latency}
if AccessTime > Threshold then
D
Recv
[i] := 1; {Cache[i] is flushed}
else
D
Recv
[i] := 0; {Cache[i] is cached}
end if
end for
paid to limit covert channels within the Virtual Machine
Monitor (VMM). Hu [8, 9] and Gray [6, 7] have pub-
lished a series of follow up research on mitigating cache
channels and bus contention channels, using timing noise
injection and lattice scheduling techniques. However,
this research field has lost its momentum until recently,
probably due to the cancellation of the VAX security ker-
nel project, as well as the lack of ubiquity of virtualized
systems in the past.
3 Struggles of the Classic Cache Channels
Existing cache covert channels (namely, the classic cache
channels) employ variants of Percival’s technique, which
uses a hybrid timing and storage scheme to transmit in-
formation over a shared processor cache, as described in
Algorithm 1.
The classic cache channels work very well on hyper-
threaded systems, achieving transmission rates as high as
hundreds of kilobytes per second [16]. However, when
applied in today’s virtualized environments, the achiev-
able rates drop drastically, to only low single-digit bits
per second [18, 30]. The multiple orders of magnitude
reduction in channel capacity clearly indicates that the
classic cache channel techniques are no longer suit-
able for cross–VM data transmission. In particular, we
found that on virtualized platforms, the data transmis-
sion scheme of a classic cache channel suffers three ma-
jor obstacles—addressing uncertainty, scheduling uncer-
tainty, and cache physical limitation.
3.1 Addressing Uncertainty
Classic cache channels modulate data by the states of
cache regions, and hence a key factor affecting chan-
nel bandwidth is the number of regions a cache being
divided. From information theory’s perspective, a spe-
cific cache region pattern is equivalent to a transmitted
symbol. And the number of regions in a cache thus cor-
responds to the number of symbols in the alphabet set.
The higher symbol count in an alphabet set, the more in-
formation can be passed per symbol.
On hyper-threaded single processor systems, for
which classic cache channels are originally designed, the
sender and receiver are executed on the same processor
core, using the L1 cache as the transmission medium.
Due to its small capacity, the L1 cache has a special
property that its storage is addressed purely by virtual
memory addresses, a technique called VIVT (virtually
indexed, virtually tagged). With a VIVT cache, two pro-
cesses can impact the same set of associative cache lines
by performing memory operations with respect to the
same virtual addresses in their address spaces, as illus-
trated in Figure 1(a). This property enables processes to
precisely control the status of the cache lines, and thus
剩余14页未读,继续阅读

nnnm030303
- 粉丝: 0
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建Cadence PSpice仿真模型库教程
- VMware 10.0安装指南:步骤详解与网络、文件共享解决方案
- 中国互联网20周年必读:影响行业的100本经典书籍
- SQL Server 2000 Analysis Services的经典MDX查询示例
- VC6.0 MFC操作Excel教程:亲测Win7下的应用与保存技巧
- 使用Python NetworkX处理网络图
- 科技驱动:计算机控制技术的革新与应用
- MF-1型机器人硬件与robobasic编程详解
- ADC性能指标解析:超越位数、SNR和谐波
- 通用示波器改造为逻辑分析仪:0-1字符显示与电路设计
- C++实现TCP控制台客户端
- SOA架构下ESB在卷烟厂的信息整合与决策支持
- 三维人脸识别:技术进展与应用解析
- 单张人脸图像的眼镜边框自动去除方法
- C语言绘制图形:余弦曲线与正弦函数示例
- Matlab 文件操作入门:fopen、fclose、fprintf、fscanf 等函数使用详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


