三层结构的图像标注模型:内容表示与多层分割
56 浏览量
更新于2024-07-15
收藏 2.38MB PDF 举报
本文主要探讨了一种新颖的图像标注模型,该模型旨在解决基于内容的图像检索中的一个重要问题——图像自动标注。由于语义鸿沟的存在,这一任务仍然具有挑战性。作者提出了一个由三层结构组成的创新模型,旨在提高标注的准确性和效率。
首先,模型的第一层是多层图像分割,它结合了显著性分析和归一化切割技术。显著性分析有助于识别图像中最重要的视觉元素,而归一化切割则能够将这些元素进一步分解成更具有语义意义的区域。这种多层次的分割策略有助于减少原始图像到有意义概念之间的抽象差距。
第二层是对这些语义区域进行进一步划分,采用了基于区域的 Bag-of-Words (RBoW) 模型。RBoW模型是传统的 Bag-of-Words (BoW) 模型的一种变体,它通过统计每个区域内的视觉特征词汇出现频率,来构建图像的视觉描述。这种表示方法强调了局部特征的组合,有助于捕捉图像内容的丰富细节。
然而,单一的局部特征描述可能会忽视不同区域之间的关系,因此,模型的第三部分引入了二阶条件随机场(Conditional Random Fields, CRF)。CRFs考虑了标签间的相互依赖性,通过概率图模型优化全局标注结果,从而提高了整体标注的准确性。这种方法能够减少孤立标注的不一致性,确保最终标注结果更加连贯和精确。
实验结果显示,基于多层分割的图像标注模型在性能上表现出色,它不仅能够有效地提取图像内容,还能考虑到不同区域之间的关系,从而显著提升了图像自动标注的精度。这为实际的图像检索系统提供了有效的工具,对于提升用户搜索体验和图像内容的理解具有重要意义。
After preprocessing, we can obtained the normal image
dataset as follows:
D ¼ I
1
; I
2
; ...; I
N
0
fg
; ð1Þ
where I
i
2R
N
1
N
2
or ðR
N
2
N
1
Þ, N
0
is the total number of
images, N
1
and N
2
represent the size of each image.
The first-layer segmentation operator is denoted as
s
1
ðI
i
Þ,
s
1
: I
i
! R
i
1
; R
i
2
; ...; R
i
M
i
no
; i ¼ 1; 2; ...; N
0
; ð2Þ
where M
i
is the number of regions of the ith image. With
the operator s
1
, we can get the segmented dataset by
D
s
1
¼ s
1
ðDÞ; ð3Þ
actually,
D
s
1
¼ R
1
1
; R
1
2
; ...; R
1
M
1
; R
2
1
; R
2
2
; ...; R
2
M
2
; ...; R
N
0
1
; R
N
0
2
; ...; R
N
0
M
N
0
no
:
ð4Þ
The basic procedures of the operator s
1
ðI
i
Þ are shown in
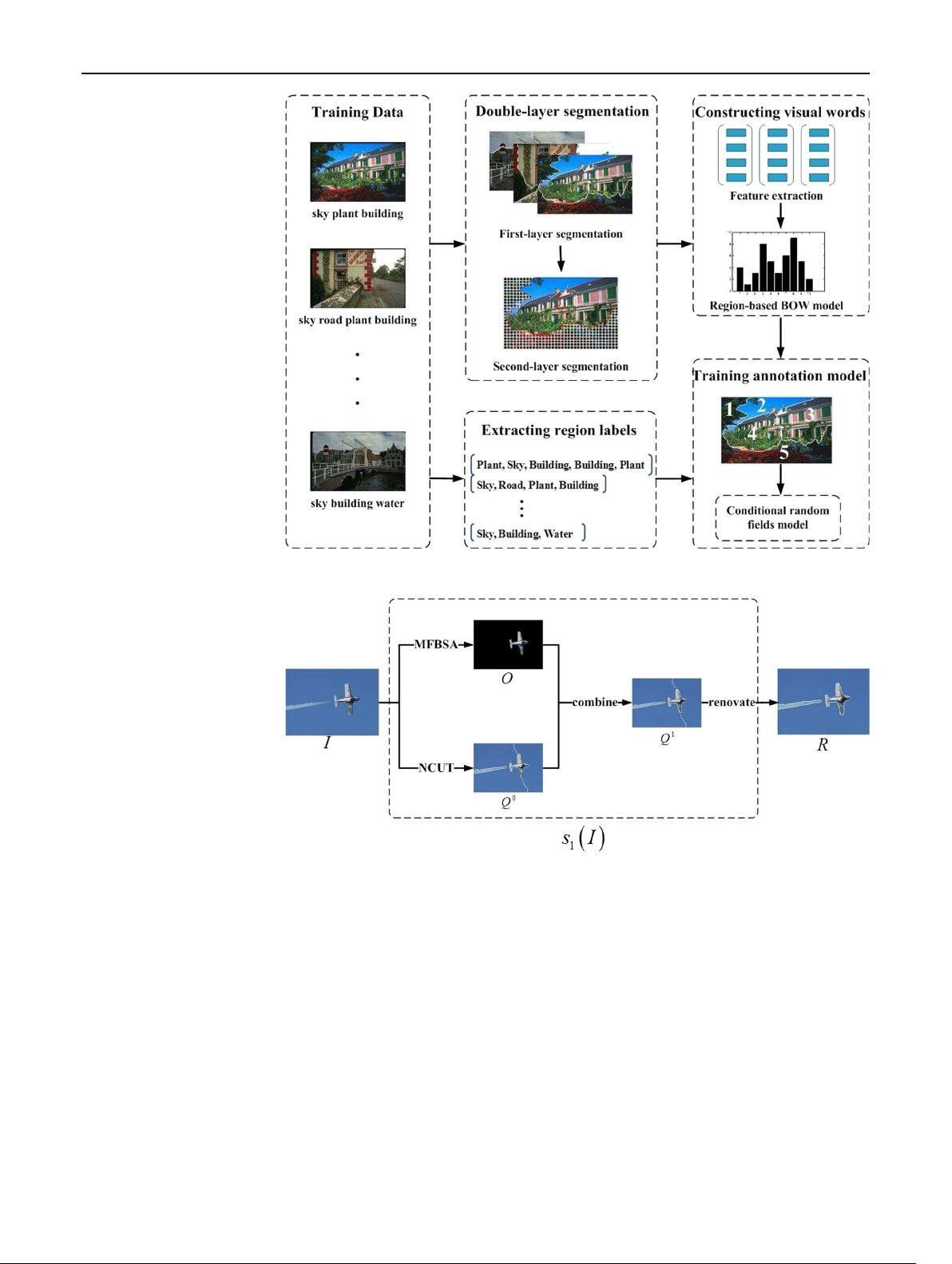
Fig. 2, in which an image I is segmented by two methods.
The most salient area O is detected by MFBSA, and image
I is segmented to Q
0
by Ncut. Then O and Q
0
are combined
to Q
1
. Finally, we achieve R by renovating Q
1
. Small
region, whose pixels are less than the threshold, is merged
Fig. 2 First-layer segmentation
Fig. 1 The framework of
MLSIA: the input images are
segmented into semantic
regions with saliency analysis
and normalized cut (Ncut) in the
first layer and each semantic
regions are segmented into grids
with given scale. Another
important step is to represent
image content with region-
based bag-of-words (RBoW)
model. The final step is to label
the semantic regions with the
second-order CRFs and
annotate the input images
Neural Comput & Applic
123
剩余15页未读,继续阅读
2013-07-26 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-10-26 上传
2024-10-26 上传

weixin_38628990
- 粉丝: 5
- 资源: 934
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握压缩文件管理:2工作.zip文件使用指南
- 易语言动态版置入代码技术解析
- C语言编程实现电脑系统测试工具开发
- Wireshark 64位:全面网络协议分析器,支持Unix和Windows
- QtSingleApplication: 确保单一实例运行的高效库
- 深入了解Go语言的解析器组合器PARC
- Apycula包安装与使用指南
- AkerAutoSetup安装包使用指南
- Arduino Due实现VR耳机的设计与编程
- DependencySwizzler: Xamarin iOS 库实现故事板 UIViewControllers 依赖注入
- Apycula包发布说明与下载指南
- 创建可拖动交互式图表界面的ampersand-touch-charts
- CMake项目入门:创建简单的C++项目
- AksharaJaana-*.*.*.*安装包说明与下载
- Arduino天气时钟项目:源代码及DHT22库文件解析
- MediaPlayer_server:控制媒体播放器的高级服务器
