Apache Hudi在阿里云DLA的实践与优化解析
版权申诉
145 浏览量
更新于2024-07-05
收藏 9.51MB PDF 举报
"3-3+Apache+Hudi在阿里云DLA的实践与优化.pdf"
Apache Hudi 是一个开源的数据湖平台,专为大规模数据处理提供高效的数据更新能力。它在阿里云DLA(Data Lake Analytics)上的实践与优化展示了其在云计算环境中的强大功能。Hudi 的核心特性包括基于可插拔索引机制的快速更新、增量拉取、时间旅行、原子化数据提交及回滚、读写快照隔离和小文件管理。这些特性使得Hudi不仅适合静态数据分析,还能处理实时或近实时的数据更新需求。
Hudi的新定位是作为一个全面的数据湖解决方案,它支持多种数据源接入,包括流式和批处理的数据摄入,并兼容多种查询引擎如Spark、Flink、Hive、Presto、Impala等。Hudi的数据集可以存储在各种云对象存储上,如HDFS、OSS、S3等,其可插拔架构设计便于扩展和适应不同的存储格式和索引机制。
Hudi的架构由Pluggable Index(如Bloom Filter或HBase)、Pluggable Dataformat(如Avro、Parquet、ORC、HFile)和Timeline Metadata组成。Timeline是一个关键组件,它记录了表的所有操作,每个操作都有一个时戳和状态,实现异步化执行。文件布局采用不同的存储类型,如Copy-On-Write (COW) 和Merge-On-Read (MOR),以满足不同场景的需求。
在读取数据时,Hudi提供了三种模式:读优化视图提供高性能的只读访问;快照视图能获取最新数据,结合Parquet文件和日志;增量视图支持增量数据处理,适用于构建增量ETL管道。这些视图的灵活性使得Hudi能够根据业务需求调整读取策略。
Hudi在众多云服务商如AWS、阿里云等,以及互联网公司(字节跳动、百度、快手等)和金融机构(工商银行、中原银行等)中得到广泛应用,显示了其广泛适用性和高可靠性。
在阿里云DLA的实践中,Hudi可能被优化以适应云环境的特定需求,例如提升数据处理速度、优化资源利用率、增强数据安全性和确保服务稳定性。未来规划可能涉及进一步集成阿里云的其他服务,提升跨服务的数据流动效率,以及持续优化性能和增加新功能,以满足不断变化的业务需求。
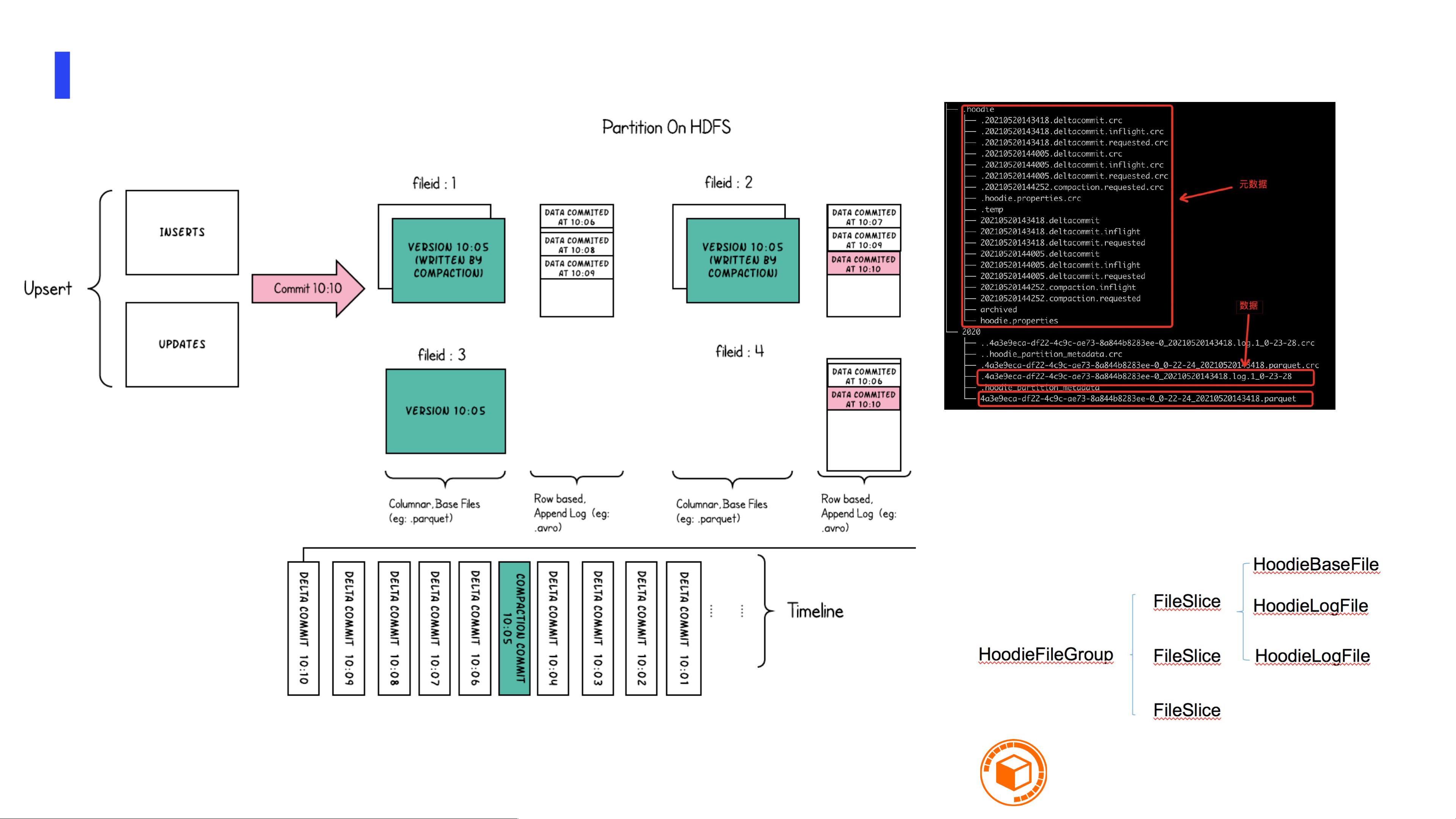
Apache Hudi文件组织
DataFunSummit|
• Timeline:有序记录单表所有操
作,赋予不同时戳(事务版本)和
状态(状态机控制,异步化执行)
• 文件布局:
剩余33页未读,继续阅读
146 浏览量
208 浏览量
2022-03-18 上传
195 浏览量
149 浏览量
2024-06-13 上传
2022-03-18 上传
2024-08-18 上传
2022-03-18 上传

普通网友
- 粉丝: 13w+
- 资源: 9194
 我的内容管理
展开
我的内容管理
展开







最新资源
- ReviverSoft_Driver_Reviver_v5.39.1.8.rar
- 骨架-nea:带有按钮的澳大利亚NEA骨架
- SpeechDecoder_speech_decode_visualc++_Weapon_
- text-summarizer
- abrhs-biobuilder:Acton-Boxborough的BioBuilder网站
- Instagram:演示 Instagram 源代码
- stuff-cs
- lilu_movie:用于学习表达和React。
- harris_solutions_odd_harris_solutions_odd_
- unity像素绘制线条
- CCR-Plus.rar
- saltestPython01
- swh_material_ws20:Kursmaterialfürden Kurs,“冬季素描与硬件”,202021年冬季
- Maika:用JavaScript制作的强大稳定的Discord多功能机器人
- CodeDomUtility:简化代码生成
- tksolfege ear training program:音乐耳朵训练练习-开源
