
1520-9210 (c) 2019 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TMM.2020.2972168, IEEE
Transactions on Multimedia
JOURNAL OF L
A
T
E
X CLASS FILES, VOL. 14, NO. 8, AUGUST 2019 3
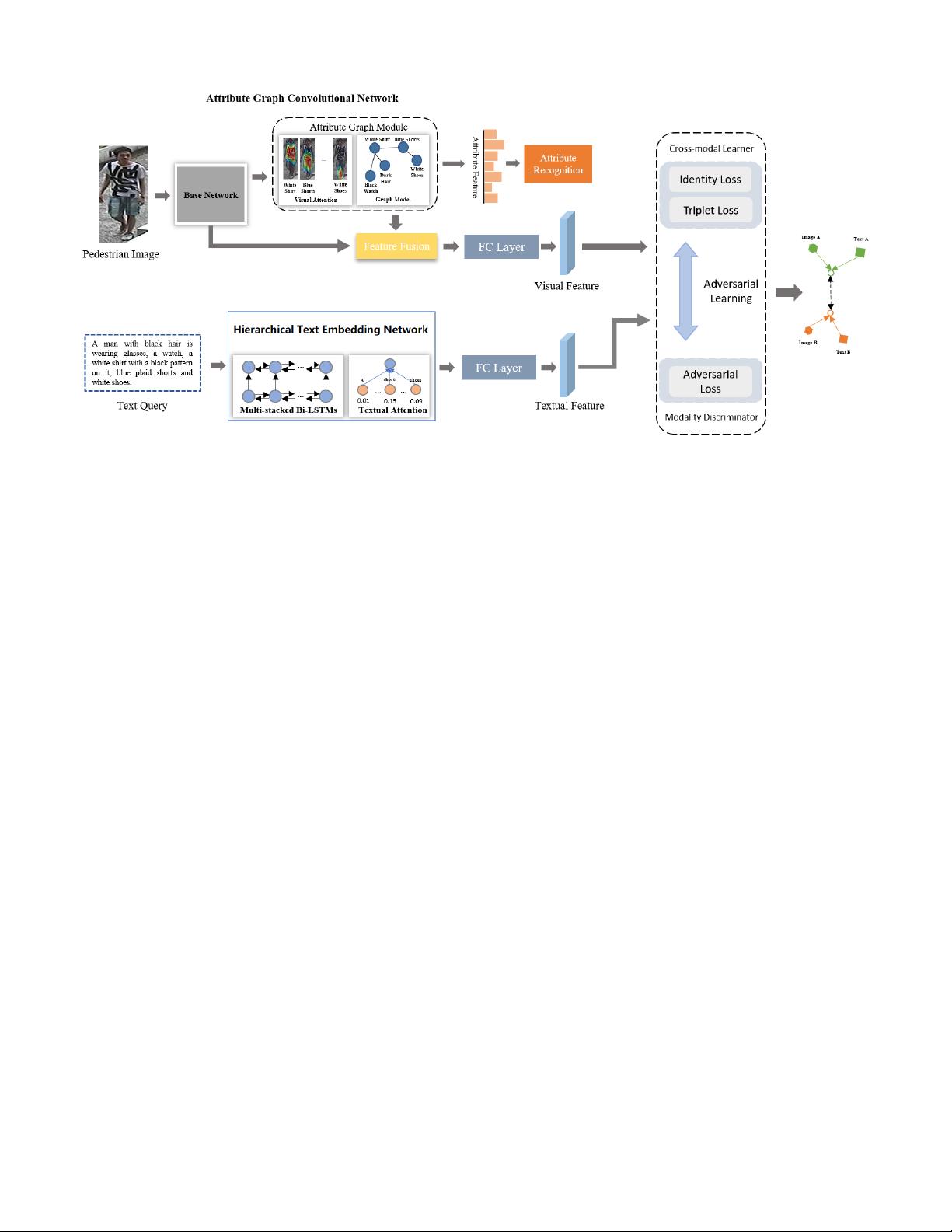
Fig. 2. The overall architecture of the proposed AATE network. It consists of a visual attribute graph convolutional network for learning visual feature, a
hierarchical text embedding network for learning textual feature as well as a cross-modal adversarial learning module for learning modality-invariant and
discriminative visual-textual representation.
which captures visual appearance of a person at multiple scales
by a comparative similarity loss on sample triplets.
Video-based Person Search. Video-based person search is
an extension of image-based person search. It searches for
the target pedestrian by one or multiple video clips of the
pedestrian [47]–[51]. Compared to images, video sequences
contain motion patterns of pedestrians as well as more pres-
ence of pedestrian appearance. Early methods are based on
hand-crafted video representations and/or appropriate distance
metric. For example, You et al. [49] developed a top-push
distance learning model to optimize the matching accuracy of
top rank results. Recent works proposed deep learning models
for video-based person search [47], [52]–[55]. For example,
Liu et al. [52] proposed a Dense 3D-Convolutional Network
(D3DNet), which introduces multiple 3D dense blocks to
learn spatio-temporal and appearance features of pedestrians.
McLaughlin et al. [47] presented a recurrent neural network
architecture, which consists of optical flow, recurrent layers
and mean-pooling layer to learn visual appearance and motion
features of pedestrians. Li et al. [53] proposed to jointly learn
local and global features in a CNN model by optimizing
multiple classification losses in different context. Shen et al.
[54] proposed a similarity-guided graph neural network to
incorporate gallery-gallery similarities into the training process
of person re-identification model.
III. METHOD
Supposing a training set {I
i
, T
i
}
N
i=1
, it includes N pairs
of pedestrian image and text description, where {I
i
}
N
i=1
are
pedestrian images taken by non-overlapping cameras and
{T
i
}
N
i=1
are the corresponding text descriptions of pedestrians.
Y = {y
i
}
N
i=1
, where y
i
∈ [1, 2, ··· , K] is pedestrian ID.
The task is to identify the target pedestrian images in gallery
based on a text query. Figure 2 illustrates the architecture
of the proposed adversarial attribute-text embedding (AATE)
network, consisting of a visual attribute graph neural network,
a hierarchical text embedding network and a cross-modal
adversarial learning module.
A. Visual Attribute Graph Convolutional Network
Text description usually describes multiple attributes of the
target pedestrian. Hence, detecting visual attributes of pedes-
trian is of great importance for searching pedestrian. Moreover,
visual attributes possess better descriptiveness, interoperability
and robustness as compared to appearance feature. An attribute
usually arises from one or more regions rather than the entire
pedestrian image. It is thus necessary to concentrate on related
regions during attribute learning. Moreover, different attributes
correlate semantically. The presence or absence of a certain
attribute is usually useful for inferring the presence/absence
of other related attributes. For example, “wearing a dress”
and “long hair” are likely to co-occur, while “carrying a bag”
and “carrying a backpack” may mutually exclusive. Based on
the above observation, we develop a visual attribute graph
convolutional network to learn effective attribute features of
pedestrians. As illustrated in Figure 3, the network consists of
a visual attention block and a graph convolutional network.
The visual attention block infers spatial attention for each
attribute and concentrates the network on the corresponding
local regions during attribute learning. The graph network ex-
ploits the underlying semantic dependencies among attributes
which could effectively boost the learning of attributes [56]–
[58].
The ResNet-50 [59] is used as the base network to extract
feature map V
r
from input image. The dimension of V
r
is
7 ×7 ×2048. The appearance feature with 2,048 dimension is
Authorized licensed use limited to: TIANJIN UNIVERSITY. Downloaded on March 07,2020 at 08:22:59 UTC from IEEE Xplore. Restrictions apply.
剩余10页未读,继续阅读

佑林杉
- 粉丝: 10
- 资源: 28
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebLogic集群配置与管理实战指南
- AIX5.3上安装Weblogic 9.2详细步骤
- 面向对象编程模拟试题详解与解析
- Flex+FMS2.0中文教程:开发流媒体应用的实践指南
- PID调节深入解析:从入门到精通
- 数字水印技术:保护版权的新防线
- 8位数码管显示24小时制数字电子钟程序设计
- Mhdd免费版详细使用教程:硬盘检测与坏道屏蔽
- 操作系统期末复习指南:进程、线程与系统调用详解
- Cognos8性能优化指南:软件参数与报表设计调优
- Cognos8开发入门:从Transformer到ReportStudio
- Cisco 6509交换机配置全面指南
- C#入门:XML基础教程与实例解析
- Matlab振动分析详解:从单自由度到6自由度模型
- Eclipse JDT中的ASTParser详解与核心类介绍
- Java程序员必备资源网站大全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


