十分钟入门:Pandas数据处理关键操作
Pandas是Python中强大的数据分析工具库,其设计目标是提供一种数据结构,使得数据清洗、整理、分析和可视化变得更加直观和高效。本文将带你快速入门pandas,通过翻译官网的《10 Minutes to pandas》指南,了解如何在十分钟内掌握基本操作。
首先,我们从创建pandas对象开始。pandas支持多种数据结构:
1. Series:它是pandas中最基础的数据结构,类似于一维数组,可以由一个list对象创建,pandas会自动为它生成整型索引。例如,`pd.Series([1, 2, 3], index=['a', 'b', 'c'])` 创建一个带有标签的Series。
2. DataFrame:是二维表格数据,可以由numpy数组和列标签构建,或者通过字典对象(其中的键作为列名,值作为一维数组或Series)生成。例如,`pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}, index=[1, 2, 3])`。
3. 数据类型检查:pandas提供了内置的方法来查看数据类型,如`df.dtypes`,这对于确保数据一致性非常重要。
接着,我们学习如何查看和处理数据:
- 查看数据的头和尾部分,以及索引、列和底层的numpy数据,使用`head()`和`tail()`方法。
- `describe()`函数用于生成数据的统计摘要,如计数、均值、标准差等。
- 转置DataFrame,使用`.T`属性或`df.transpose()`。
- 排序数据,包括按行轴(index)或列轴(columns)升序或降序排列,以及基于值的排序。
进入数据选择和访问部分,pandas提供了多种高效的选择机制:
- 使用`.at`, `.iat`, `.loc`, `.iloc` 和 `.ix` 方法,针对不同的访问方式(标签、位置和混合索引)进行数据选取。
- `.at`和`.iat`用于基于位置和标签的精确匹配。
- `.loc`基于标签选择,支持复杂的条件和切片。
- `.iloc`则基于整数位置进行选择,包括行和列的切片。
- `.ix`在旧版本中支持混合索引,新版本建议使用其他方法。
- 选择单列或通过标签获取特定区域,同时支持维度缩减操作。
- 布尔索引允许根据条件选择数据,比如`df[df['column'] > 10]` 或 `df[df['column'].isin([1, 2, 3])]`。
通过这些基础操作,你将能够快速掌握pandas的基本工作流程,并在实际的数据分析任务中游刃有余。为了深入理解和更高级的技巧,强烈推荐查阅官方Cookbook文档和其他在线教程,以扩展你的知识库。
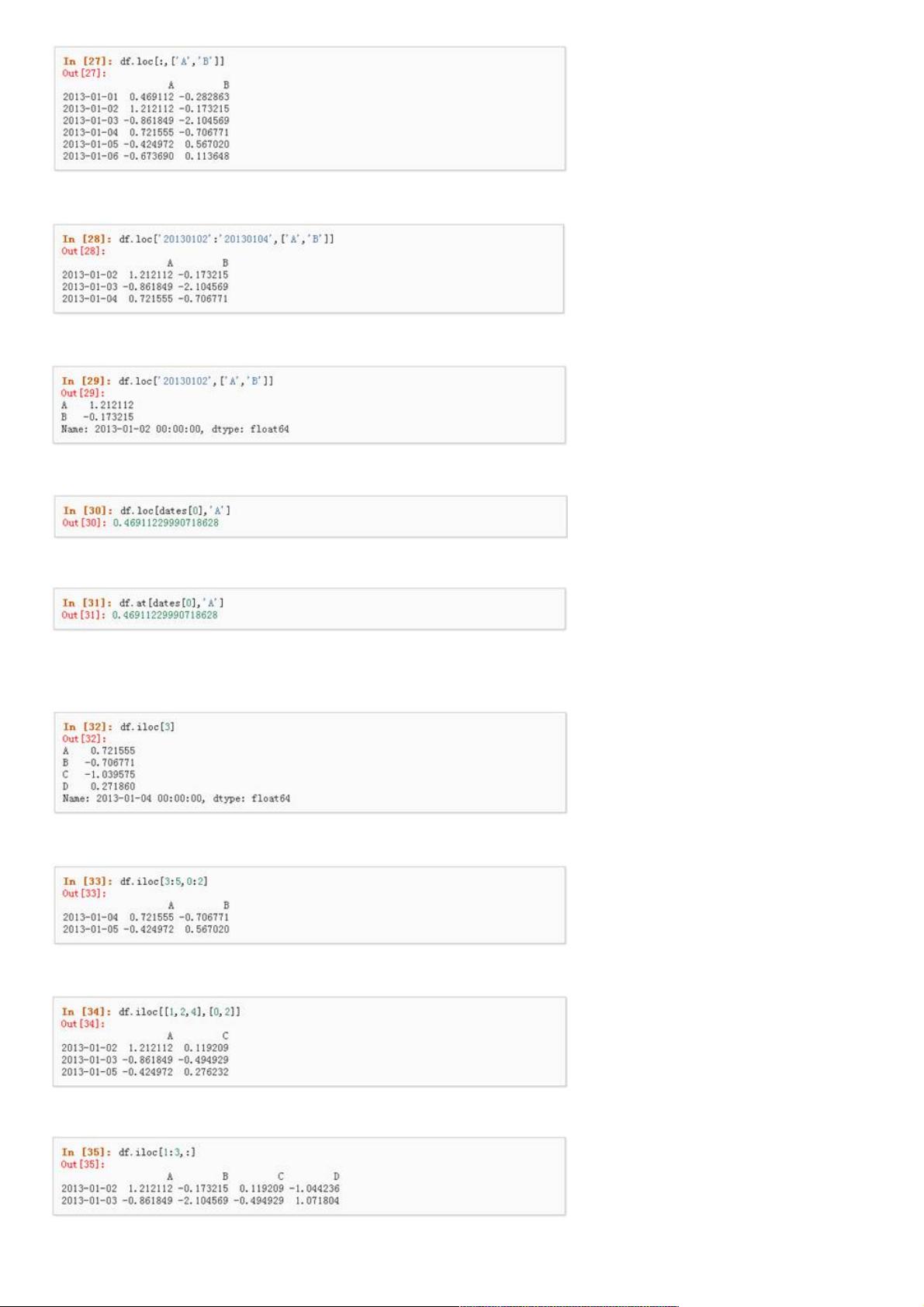
3、 标签切片
4、 对于返回的对象进行维度缩减
5、 获取一个标量
6、 快速访问一个标量(与上一个方法等价)
l 通过位置选择通过位置选择
1、 通过传递数值进行位置选择(选择的是行)
2、 通过数值进行切片,与numpy/python中的情况类似
3、 通过指定一个位置的列表,与numpy/python中的情况类似
4、 对行进行切片
5、 对列进行切片
剩余15页未读,继续阅读
199 浏览量
546 浏览量
152 浏览量
507 浏览量
139 浏览量
169 浏览量
3039 浏览量
223 浏览量
377 浏览量









