信息检索与自然语言处理中的学习排序
需积分: 12 58 浏览量
更新于2024-07-17
收藏 2.82MB PDF 举报
“Learning to Rank for Information Retrieval and Natural Language Processing” 是一本由Hang Li撰写的合成讲座系列书籍,由Graeme Hirst编辑,由Morgan Claypool Publishers出版。这本书专注于介绍如何在信息检索和自然语言处理领域应用学习排名算法。
在信息检索中,学习排名(Learning to Rank)是一种关键的技术,它的目标是根据用户查询优化结果的排序,以提供最相关、最有用的信息。这一领域与推荐系统紧密相关,因为推荐系统的本质就是对大量可能的选项进行排序,以提供用户最可能感兴趣的内容。学习排名通过机器学习方法来训练模型,这些模型能够理解数据中的模式,并据此对文档或物品进行排序。
本书深入探讨了学习排名在信息检索中的应用,包括搜索引擎的搜索结果排序。在信息检索中,有效的排名算法可以显著提高用户体验,帮助用户快速找到他们需要的信息。这涉及到对查询理解和文本相似度计算的理解,以及如何构建和优化排序模型。
在自然语言处理(NLP)方面,学习排名也有广泛应用。例如,它可以用于文档分类、情感分析、机器翻译等任务,通过比较不同文本特征的权重来决定文本的分类或排序。此外,它还可能涉及文本生成、问答系统以及对话理解等复杂任务,其中准确地评估和排序可能的响应至关重要。
书中可能会讨论各种学习排名的算法,如梯度提升决策树(Gradient Boosted Decision Trees)、支持向量机(Support Vector Machines)和神经网络模型,如深度学习中的卷积神经网络(CNN)和递归神经网络(RNN)。这些模型会根据训练数据学习到的特征权重对输入进行排序,从而实现自动化和精准的决策过程。
此外,学习排名还可以与其他技术结合,如协同过滤(Collaborative Filtering)和内容过滤(Content-Based Filtering),以增强推荐系统的性能。在跨语言信息检索(Cross-Language Information Retrieval, CLIR)中,学习排名可能被用来改善不同语言之间的信息检索效果,使得用户能够搜索并理解非母语内容。
“Learning to Rank for Information Retrieval and Natural Language Processing”是一本对于推荐系统爱好者和NLP研究者极具价值的资源,它涵盖了从基础理论到实际应用的广泛内容,有助于读者深入理解并掌握学习排名技术在现代信息检索和自然语言处理系统中的核心作用。
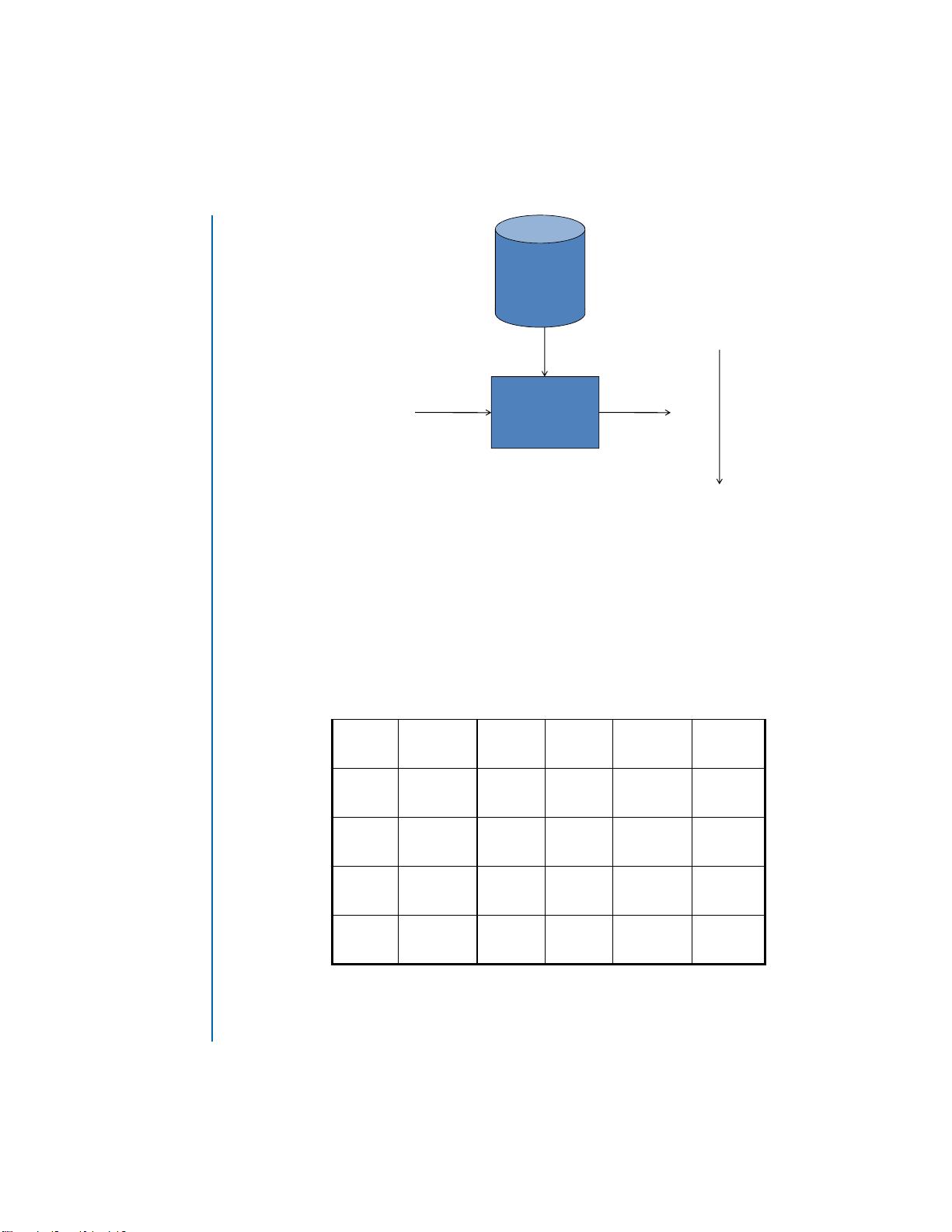
2 1. LEARNING TO RANK
documents
{}
N
dddD ,,,
21
L=
ranking based on
relevance
Retrieval
System
q
nq
q
q
d
d
d
,
2,
1,
M
q
query
ranking of documents
Figure 1.1: Document Retrieval. Downward arrow represents ranking of documents
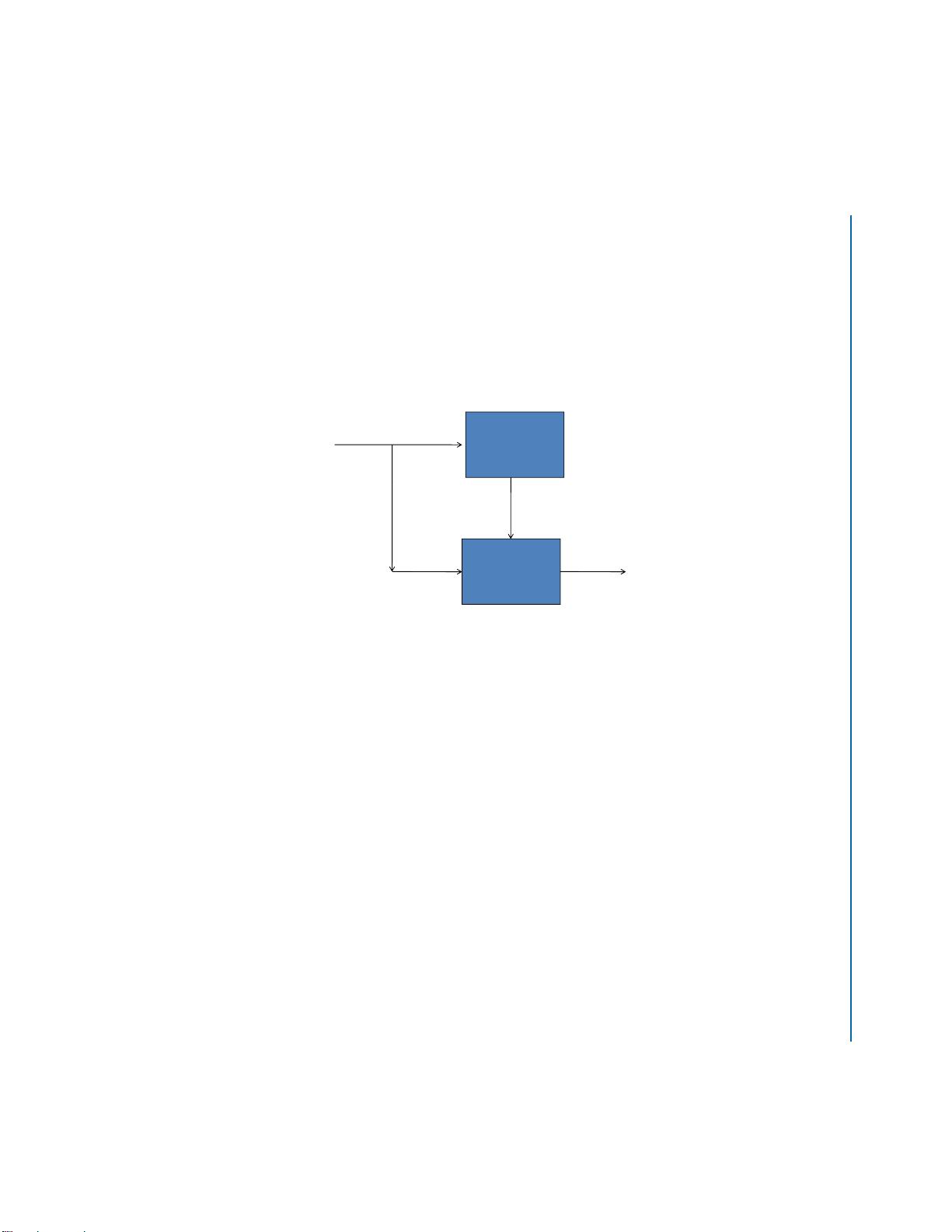
The data in collaborative filtering is given in a matrix, in which rows correspond to users and
columns correspond to items (cf., Fig. 1.2). Some elements of the matrix are known, while the others
are not.The elements represent users’ ratings on items where the ratings have several grades (levels).
The question is how to determine the unknown elements of the matrix. One common assumption
is that similar users may have similar ratings on similar items. When a user is specified, the system
suggests a ranking list of items with the high grade items on the top.
Item1 Item2 Item3 ... ItemN
User1 54
User2 1 2 2
... ? ? ?
UserM 43
Figure 1.2: Coll a b o r a t i v e Filtering

剩余114页未读,继续阅读
454 浏览量
167 浏览量
244 浏览量
438 浏览量
321 浏览量
135 浏览量
211 浏览量
2023-06-09 上传
215 浏览量

pianer3047
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







