AVPASS:自动绕过Android恶意软件检测系统
需积分: 5 186 浏览量
更新于2024-06-21
收藏 4.89MB PDF 举报
"藏经阁-AVPASS_Automatically Bypassing.pdf"
这篇文档主要讨论了“AVPASS: Automatically Bypassing Android Malware Detection System”,这是一个由Jinho Jung, Chanil Jeon, Max Wolotsky, Insu Yun, 和 Taesoo Kim在2017年在乔治亚理工学院进行的研究项目。研究团队属于SSLab(@GT)和ISTC-ARSA,这两个组织专注于系统安全研究和恶意软件检测分析的强化。
AVPASS项目的核心目标是通过自动化技术来绕过Android设备上的反病毒系统(AVs),从而对抗日益增长的Android恶意软件威胁。该技术通过推断反病毒软件的特征和规则,以及混淆Android二进制文件(APK)来实现这一目标。同时,AVPASS设计时考虑了防止代码泄漏,以确保在规避安全防护的同时,不会对用户数据造成风险。
随着Android操作系统在移动市场的主导地位不断巩固,其面临的恶意软件问题也日益严重。数据显示,Android每天新增约8,400种恶意软件,安全专家预测2017年可能有超过350万新的Android恶意软件应用出现。因此,AVPASS的出现对于对抗这种趋势具有重要的现实意义。
研究者们的工作不仅揭示了Android恶意软件检测系统的弱点,还提出了一种创新的解决方案,即自动地、智能地混淆恶意软件以避开检测。这可能会对未来的反恶意软件策略产生深远影响,推动安全研究人员开发更复杂的方法来检测和防御不断演变的Android恶意软件。
AVPASS项目是一项旨在提升Android设备安全性的技术,它通过理解和利用反病毒软件的工作原理,提供了一种自动化的方法来混淆恶意软件,使其能够逃避检测。这个研究为理解恶意软件的躲避策略和改进安全防御提供了宝贵的知识,同时也警示了Android用户和开发者应持续关注并提升移动设备的安全性。

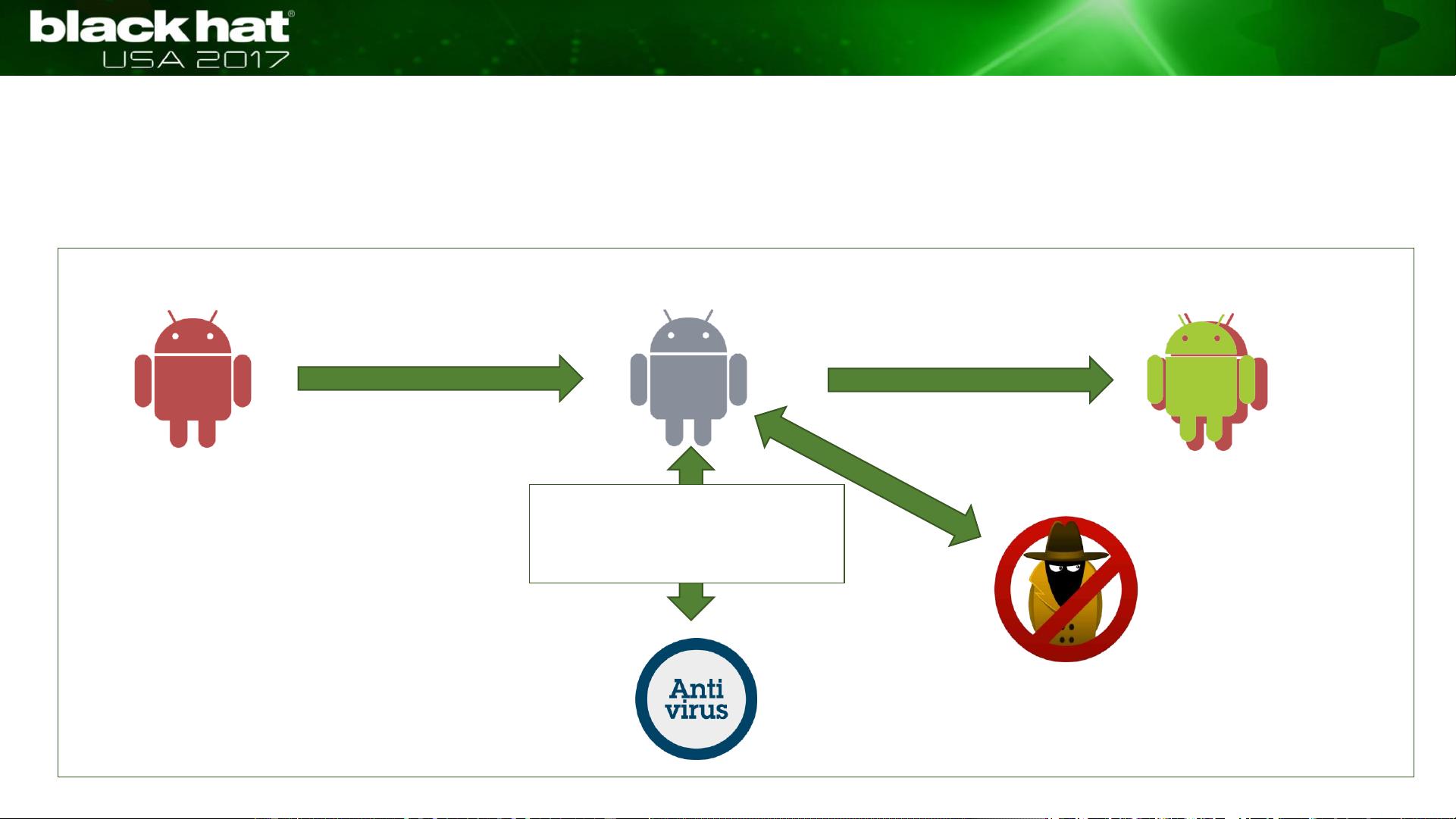
Summary of AVPASS operation
12
Bypassed most of AVs with 3.42 / 58 (5.8%) detections
Discovered 5 strong, 3 normal, and 2 weak impact features of AVs
Discovered bypassing rule combinations (about 30%)
Prevented code leakage when querying by using Imitation Mode
剩余71页未读,继续阅读
2023-07-10 上传
2023-06-02 上传
2023-03-24 上传
2023-07-12 上传
2023-03-24 上传
2023-06-03 上传
2023-07-24 上传
2023-06-07 上传

weixin_40191861_zj
- 粉丝: 83
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
