Transformer架构在时间序列预测中的优势与改进
需积分: 0 166 浏览量
更新于2024-08-03
收藏 489KB PDF 举报
"本文探讨了Transformer在时间序列预测领域的应用,着重分析了其与传统模型如RNN的区别以及优势,并提到了针对Transformer架构的优化策略,包括Convolutional Self-Attention和LogSparse技术。"
Transformer模型,最初由Vaswani等人在2017年的《Attention is All You Need》论文中提出,主要应用于自然语言处理任务。然而,随着时间序列预测领域的发展,Transformer的影响力逐渐扩大到这个领域,展现出强大的序列建模能力。Transformer的核心在于自注意力(Self-Attention)机制,它允许模型同时考虑序列中的所有元素,而不仅仅是前后相邻的元素。
在时间序列预测中,Transformer的四大优势如下:
1. **并行计算**:与RNN(循环神经网络)不同,Transformer的计算过程可以并行化,大大提高了训练效率,尤其在大规模数据集上表现显著。
2. **长序列建模**:Transformer有效解决了RNN在长序列上的梯度消失和梯度爆炸问题,能更好地捕捉长期依赖关系。
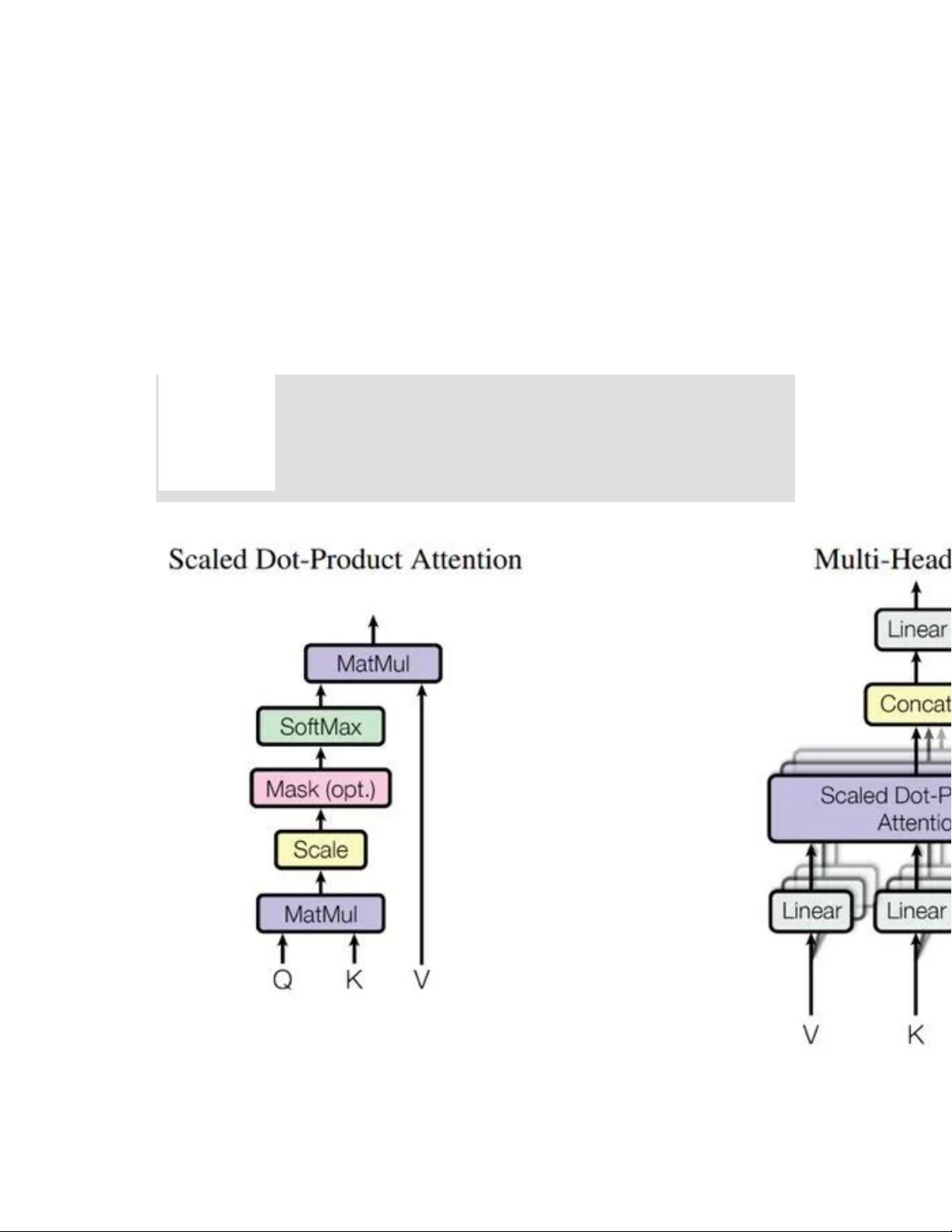
3. **多头注意力**:Multi-Head Attention机制允许模型同时关注不同时间步的多种模式,增强对短期和长期依赖的建模能力。
4. **可解释性**:Transformer的注意力得分(Attention Score)提供了预测结果对历史值的依赖程度的可视化,有助于理解模型行为。
然而,Transformer在时间序列预测中也存在挑战,比如:
1. **计算复杂度高**:seq2seq架构使得编码和解码过程的计算需求较大,尤其是在处理长序列时。
2. **对局部信息的敏感性不足**:原始的自注意力机制可能忽略局部上下文信息,影响预测精度。
为解决这些问题,研究者提出了两项改进:
1. **Convolutional Self-Attention**:通过引入卷积操作,增强模型对局部上下文信息的捕获,提高预测准确性,特别是在捕捉时间序列中的局部模式时。
2. **LogSparse**:这是一种优化策略,用于减少Attention计算的复杂度,使模型能够处理更长的时间序列,而不会过度消耗计算资源。
Convolutional Self-Attention结合了卷积层的局部感知特性与Transformer的全局注意力机制,既能保留局部信息,又能利用全局上下文。LogSparse则是一种稀疏注意力机制,通过有选择地计算部分注意力得分,降低了计算复杂度,同时保持模型性能。
总结来说,Transformer在时间序列预测中通过其独特的结构和机制,提升了预测的效率和准确性,同时也推动了相关领域的研究发展,不断优化模型以适应各种实际应用场景。
Convolutional Self-Attention
原始Transformer中的Self-Attention结构如下:
剩余11页未读,继续阅读
2023-04-10 上传
164 浏览量
2023-11-15 上传
2023-09-07 上传
2023-10-24 上传
2023-08-31 上传
2023-09-08 上传
2023-07-27 上传
2023-08-12 上传


白话机器学习
- 粉丝: 1w+
- 资源: 7670
 我的内容管理
展开
我的内容管理
展开







最新资源
- PythonLLVM:基于py2llvm的python的LLVM编译器
- 迷宫搜索游戏应用程序:简单的搜索视频游戏应用程序
- TaskTrackerApp
- DYL EXPRESS 中马集运仓-crx插件
- Security题库.zip
- Clip2VO:CA-Visual Object的Clipper兼容性库-开源
- 365步数运动宝v4.1.84
- ruscello:打字稿中的redux + react-redux
- Roman-Shchorba-KB20:ЛабораторніроботизДД“Базовіметодологіїтатехнологіїпрограмування”студентаакаееггрупиКІ
- PCAPFileAnalyzer:分析 PCAP 网络捕获文件
- 西安市完整矢量shp数据
- 泽邦集运代购和代运助手-crx插件
- python的tkinter库实现sqlite3数据库连接和操作样例源代码
- VC++2010学生版(离线安装包)
- basic-webpage
- flx:Emacs的模糊匹配...崇高的文字
