Hadoop2.0中NameNode高可用实现解析
33 浏览量
更新于2024-08-28
收藏 382KB PDF 举报
"HadoopNameNode高可用(HighAvailability)实现解析"
在Hadoop的发展历程中,NameNode的单点故障问题一直是系统稳定性和可用性的重大挑战。NameNode作为HDFS的核心组件,负责管理整个分布式文件系统的元数据,一旦它出现问题,整个HDFS集群将无法正常工作,进而影响依赖于HDFS的MapReduce、Hive、Pig和HBase等服务。为了解决这一难题,Hadoop2.0引入了NameNode的高可用特性(High Availability, HA),以确保即使NameNode出现故障,系统也能迅速恢复服务。
NameNode的高可用架构主要基于Active/Standby模式,包括一个Active NameNode和一个Standby NameNode。Active NameNode是当前对外提供服务的NameNode,处理所有的客户端请求,包括文件的创建、删除、重命名以及读写操作。而Standby NameNode则处于备用状态,不断从Active NameNode同步元数据信息,以便在Active节点故障时能够快速接管服务。
实现NameNode HA的关键在于保证数据的一致性和快速切换。ZKFailoverController(Zookeeper-based Failover Controller)扮演了重要的角色,它是一个独立的进程,监控NameNode的状态并协调主备切换。ZKFailoverController利用Zookeeper来确定哪个NameNode是当前的Active,并在需要时安全地进行主备切换。Zookeeper作为一个分布式协调服务,确保了切换过程的原子性和一致性。
在NameNode之间进行主备切换时,ZKFailoverController会首先通过Zookeeper将Active NameNode设置为Standby状态,防止新的修改操作。接着,Standby NameNode会获取Active NameNode的最新元数据快照,并与JournalNodes(日志节点)同步事务日志。JournalNodes是另一关键组件,它们存储由Active NameNode产生的所有变更操作,确保在切换过程中不会丢失任何数据。一旦Standby NameNode完成同步,它会被提升为新的Active,并开始接收客户端请求。
此外,HDFS的HA还涉及一个重要的概念——安全模式(Safe Mode)。在NameNode启动或主备切换期间,系统会进入安全模式,不允许修改元数据,直到NameNode确认大多数DataNode已经报告并且文件系统是健康的。这保证了在NameNode恢复服务时,元数据的完整性。
Hadoop NameNode的高可用性实现是通过Active/Standby模式、ZKFailoverController的监控与切换控制、JournalNodes的日志同步以及安全模式的保护来保障的。这一机制大大提升了HDFS的容错能力和服务连续性,使得Hadoop能够适应更广泛的业务场景,包括对可用性和数据一致性要求较高的在线应用。
HadoopNameNode高可用高可用(HighAvailability)实现解析实现解析
NameNode 高可用整体架构概述
在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDFS NameNode 和 JobTracker 都存在着单点问题,这其中以 NameNode
的单点问题尤为严重。因为 NameNode 保存了整个 HDFS 的元数据信息,一旦 NameNode 挂掉,整个 HDFS 就无法访问,
同时 Hadoop 生态系统中依赖于 HDFS 的各个组件,包括 MapReduce、Hive、Pig 以及 HBase 等也都无法正常工作,并且
重新启动 NameNode 和进行数据恢复的过程也会比较耗时。这些问题在给 Hadoop 的使用者带来困扰的同时,也极大地限制
了 Hadoop 的使用场景,使得 Hadoop 在很长的时间内仅能用作离线存储和离线计算,无法应用到对可用性和数据一致性要求
很高的在线应用场景中。
所幸的是,在 Hadoop2.0 中,HDFS NameNode 和 YARN ResourceManger(JobTracker 在 2.0 中已经被整合到 YARN
ResourceManger 之中) 的单点问题都得到了解决,经过多个版本的迭代和发展,目前已经能用于生产环境。HDFS
NameNode 和 YARN ResourceManger 的高可用 (High Availability,HA) 方案基本类似,两者也复用了部分代码,但是由于
HDFS NameNode 对于数据存储和数据一致性的要求比 YARN ResourceManger 高得多,所以 HDFS NameNode 的高可用
实现更为复杂一些,本文从内部实现的角度对 HDFS NameNode 的高可用机制进行详细的分析。
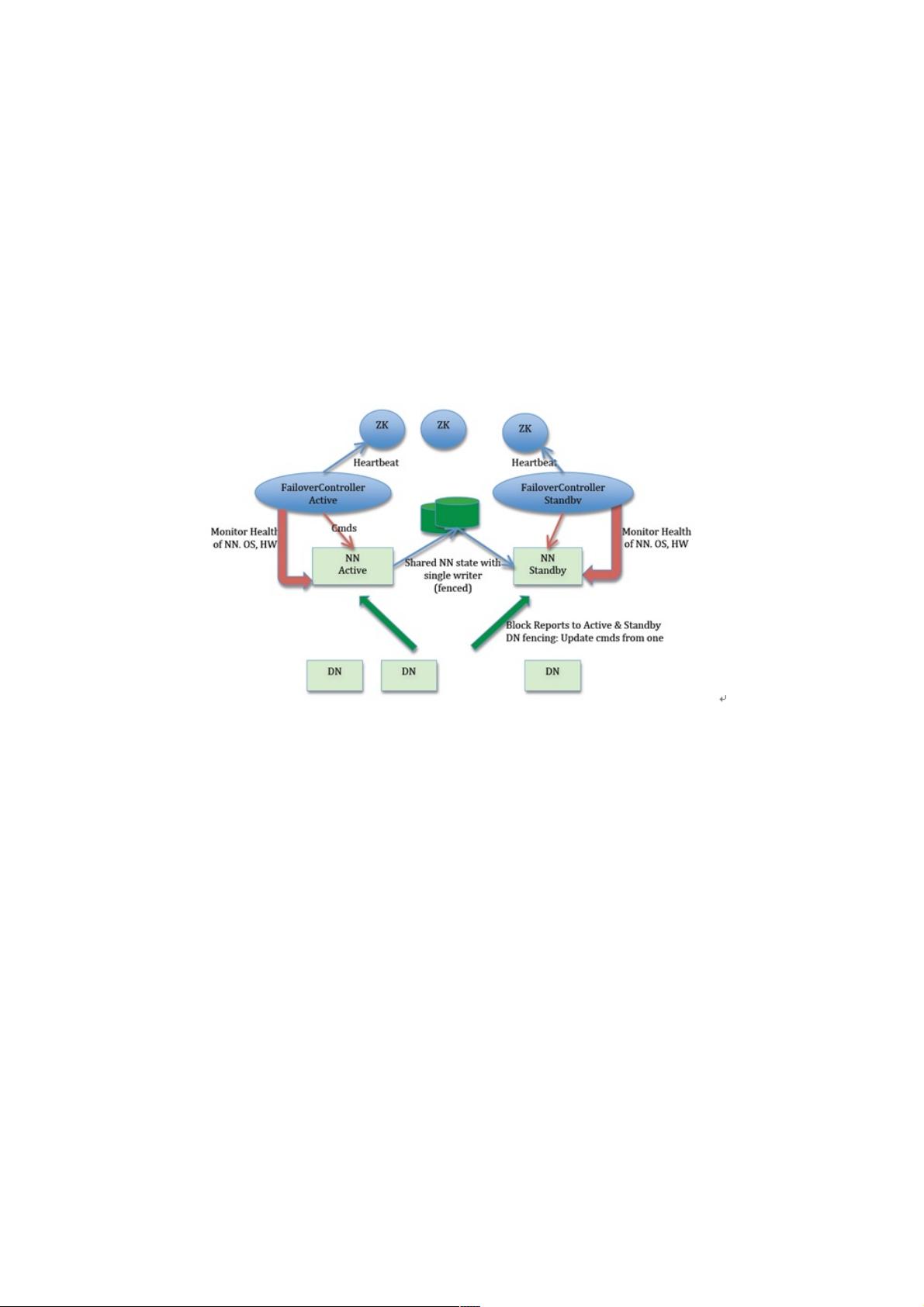
HDFS NameNode 的高可用整体架构如图 1 所示 :
从上图中,我们可以看出 NameNode 的高可用架构主要分为下面几个部分:
Active NameNode 和 Standby NameNode:两台 NameNode 形成互备,一台处于 Active 状态,为主 NameNode,另外一台
处于 Standby 状态,为备 NameNode,只有主 NameNode 才能对外提供读写服务。
主备切换控制器 ZKFailoverController:ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控
制。ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选
举和切换,当然 NameNode 目前也支持不依赖于 Zookeeper 的手动主备切换。
Zookeeper 集群:为主备切换控制器提供主备选举支持。
共享存储系统:共享存储系统是实现 NameNode 的高可用最为关键的部分,共享存储系统保存了 NameNode 在运行过程中
所产生的 HDFS 的元数据。主 NameNode 和
NameNode 通过共享存储系统实现元数据同步。在进行主备切换的时候,新的主 NameNode 在确认元数据完全同步之后才能
继续对外提供服务。
DataNode 节点:除了通过共享存储系统共享 HDFS 的元数据信息之外,主 NameNode 和备 NameNode 还需要共享 HDFS
的数据块和 DataNode 之间的映射关系。DataNode 会同时向主 NameNode 和备 NameNode 上报数据块的位置信息。
下面开始分别介绍 NameNode 的主备切换实现和共享存储系统的实现,在文章的最后会结合笔者的实践介绍一下在
NameNode 的高可用运维中的一些注意事项。
NameNode 的主备切换实现
NameNode 主备切换主要由 ZKFailoverController、HealthMonitor 和 ActiveStandbyElector 这 3 个组件来协同实现:
ZKFailoverController 作为 NameNode 机器上一个独立的进程启动 (在 hdfs 启动脚本之中的进程名为 zkfc),启动的时候会创
建 HealthMonitor 和 ActiveStandbyElector 这两个主要的内部组件,ZKFailoverController 在创建 HealthMonitor 和
ActiveStandbyElector 的同时,也会向 HealthMonitor 和 ActiveStandbyElector 注册相应的回调方法。
HealthMonitor 主要负责检测 NameNode 的健康状态,如果检测到 NameNode 的状态发生变化,会回调 ZKFailoverController
下载后可阅读完整内容,剩余9页未读,立即下载
2018-03-17 上传
2021-10-11 上传
2008-12-24 上传
2023-05-31 上传
2024-01-12 上传
2023-04-30 上传
2024-11-04 上传
2023-03-28 上传
2023-06-07 上传

weixin_38537315
- 粉丝: 6
- 资源: 876
 我的内容管理
展开
我的内容管理
展开







