深度学习NLP:注意力机制与Transformer解析
5 浏览量
更新于2024-08-28
收藏 730KB PDF 举报
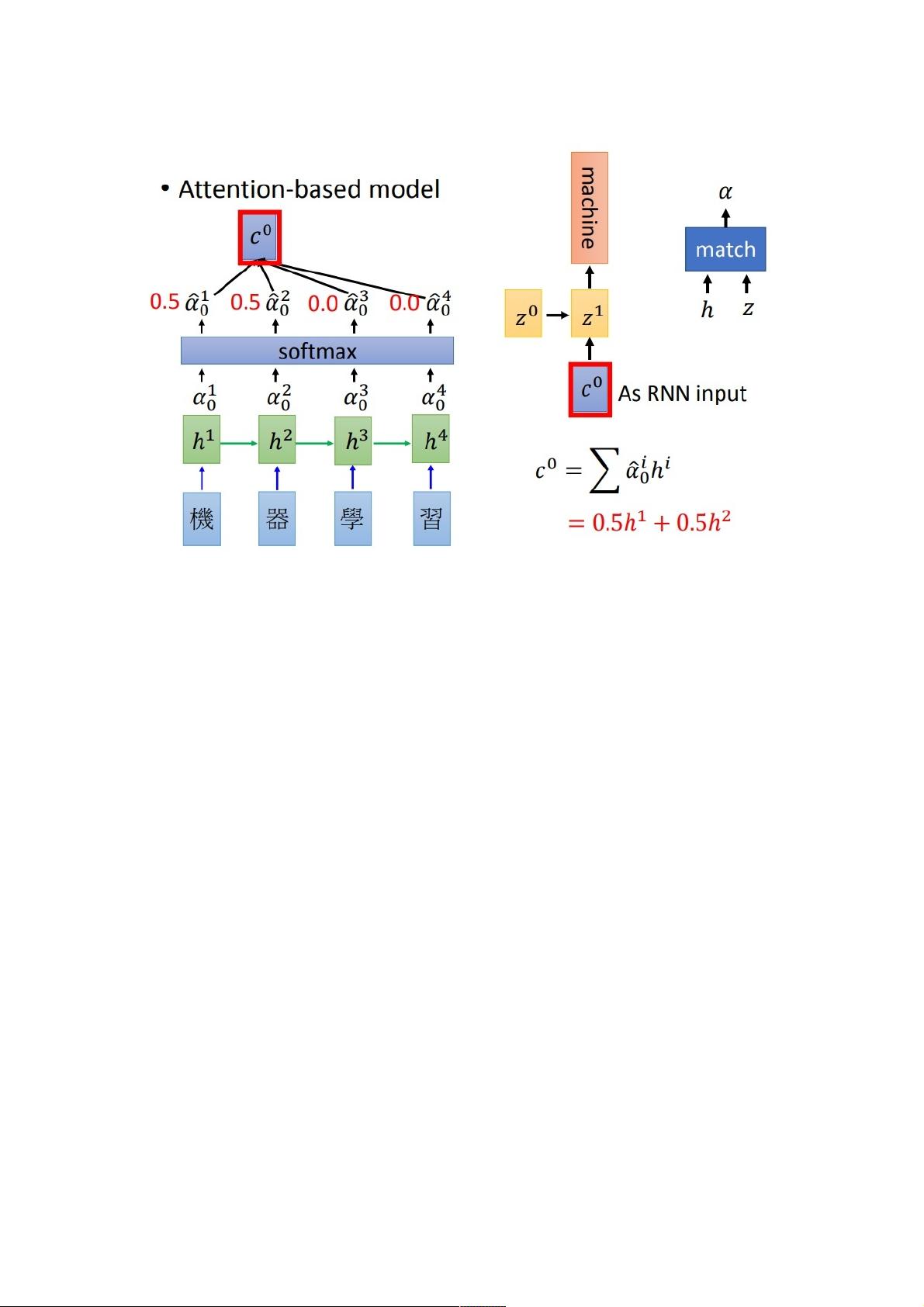
力分布计算:每个输入信息xi有一个对应的键Key ki 和值Value vi。查询向量Query q 与所有Key ki 进行相似度计算,通常使用点积或者加权点积,得到注意力权重分数αi,即 αi = f(q, ki),其中f可以是任何合适的函数,如softmax函数来归一化权重。
step3-加权求和:根据计算出的注意力权重αi,对Value向量vi进行加权求和,得到加权的Attention Value V = ∑(αivi)。这个加权的Attention Value是输入信息的压缩表示,更专注于与查询向量q相关的重要信息。
二、Transformer详解
Transformer模型是Google在2017年提出的一种基于自注意力(self-attention)机制的序列建模方法,主要解决了RNN和CNN在处理长序列时存在的问题,如计算效率低和长距离依赖难捕获。
1、Transformer架构
Transformer由Encoder和Decoder两部分组成,每部分都是由多个相同的层堆叠而成。每个层又包含两个子层:自注意力层(Self-Attention Layer)和前馈神经网络层(Feed-Forward Neural Network Layer)。
2、自注意力(Self-Attention)
自注意力允许模型在处理序列元素时考虑全局上下文,而不是仅关注当前位置或有限的历史窗口。它通过计算序列中所有元素对其他元素的注意力分数,然后加权求和来生成新的表示。
3、前馈神经网络(Feed-Forward Neural Network)
FFN层是一个简单的多层感知机,通常包含两个线性变换和ReLU激活函数,用于对每个位置的自注意力输出进行非线性转换。
4、位置编码(Positional Encoding)
由于Transformer没有循环结构,不能自然地捕捉序列顺序,所以引入了位置编码,这是向每个输入添加的固定向量,以确保模型能够区分序列中的位置。
5、Encoder和Decoder
Encoder负责理解输入序列,通过多层自注意力和FFN处理,学习输入的上下文表示。Decoder则负责生成输出序列,除了自注意力层外,Decoder还包括一个额外的注意力层,称为遮蔽自注意力(Masked Self-Attention),防止当前位置直接看到未来的序列信息,保证了序列生成的顺序性。
6、Transformer的应用
Transformer因其高效的并行计算和优秀的性能,迅速成为机器翻译、文本生成、问答系统等多个NLP任务的首选模型。后续的预训练模型如BERT、GPT系列等,都基于Transformer架构,并在此基础上进行了扩展和优化。
总结,Attention机制和Transformer模型是现代NLP领域的核心组成部分,它们显著提高了神经网络处理序列数据的效率和效果,尤其是对于长距离依赖的处理能力。Attention机制通过选择性地关注输入信息,解决了传统神经网络的计算瓶颈,而Transformer则通过自注意力和全并行计算,革新了序列建模的方式。
nlp中的中的Attention注意力机制注意力机制+Transformer详解详解
一、Attention机制剖析
1、为什么要引入Attention机制?
根据通用近似定理,前馈网络和循环网络都有很强的能力。但为什么还要引入注意力机制呢?
计算能力的限制:当要记住很多“信息“,模型就要变得更复杂,然而目前计算能力依然是限制神经网络发展的瓶颈。
优化算法的限制:虽然局部连接、权重共享以及pooling等优化操作可以让神经网络变得简单一些,有效缓解模型复杂度和表
达能力之间的矛盾;但是,如循环神经网络中的长距离以来问题,信息“记忆”能力并不高。
可以借助人脑处理信息过载的方式,例如Attention机制可以提高神经网络处理信息的能力。
2、Attention机制有哪些?(怎么分类?)
当用神经网络来处理大量的输入信息时,也可以借鉴人脑的注意力机制,只 选择一些关键的信息输入进行处理,来提高神经
网络的效率。按照认知神经学中的注意力,可以总体上分为两类:
聚焦式(focus)注意力:自上而下的有意识的注意力,主动注意——是指有预定目的、依赖任务的、主动有意识地聚焦于某
一对象的注意力;
显著性(saliency-based)注意力:自下而上的有意识的注意力,被动注意——基于显著性的注意力是由外界刺激驱动的注
意,不需要主动干预,也和任务无关;可以将max-pooling和门控(gating)机制来近似地看作是自下而上的基于显著性的注
意力机制。
在人工神经网络中,注意力机制一般就特指聚焦式注意力。
3、Attention机制的计算流程是怎样的?
下载后可阅读完整内容,剩余8页未读,立即下载
29801 浏览量
112 浏览量
583 浏览量
点击了解资源详情
2025-01-07 上传
2025-02-01 上传
点击了解资源详情
420 浏览量
315 浏览量

weixin_38652147
- 粉丝: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 隐私数据清洗工具Java代码实践教程
- UML与.NET设计模式详细教程
- 多技术领域综合企业官网开发源代码包及使用指南
- C++实现简易HTTP服务端及文件处理
- 深入解析iOS TextKit图文混排技术
- Android设备间Wifi文件传输功能的实现
- ExcellenceSoft热键工具:自定义Windows快捷操作
- Ubuntu上通过脚本安装Deezer Desktop非官方指南
- CAD2007安装教程与工具包下载指南
- 如何利用Box平台和API实现代码段示例
- 揭秘SSH项目源码:实用性强,助力开发高效
- ECSHOP仿68ecshop模板开发中心:适用于2.7.3版本
- VS2012自定义图标教程与技巧
- Android新库Quiet:利用扬声器实现数据传递
- Delphi实现HTTP断点续传下载技术源码解析
- 实时情绪分析助力品牌提升与趋势追踪:交互式Web应用程序
