深入理解HDFS:NameNode与DataNode解析
需积分: 50 134 浏览量
更新于2024-07-17
收藏 1.53MB DOCX 举报
"本文主要介绍了HDFS(Hadoop Distributed File System)的体系结构,重点解析了NameNode和DataNode的核心概念,以及HDFS的基本使用方法。"
HDFS是Apache Hadoop项目的一部分,它是一个分布式文件系统,设计用于处理和存储大量数据。随着数据规模的不断增长,传统的单机文件系统无法满足需求,HDFS应运而生,它允许多个用户跨多台计算机共享文件和存储空间。HDFS的关键特性包括透明性和容错性,使得用户能像访问本地磁盘一样访问分布式存储的文件,同时即使部分节点故障,系统也能保持运行且不会丢失数据。
**NameNode**是HDFS的核心组件,负责管理文件系统的元数据,如文件命名空间(文件和目录的层次结构)和文件的块映射信息。NameNode执行以下关键任务:
1. **元数据管理**:它维护一个名为`fsimage`的文件,包含所有文件和目录的最新状态,以及`editlog`日志,记录所有对文件系统的更改操作。
2. **命名空间操作**:如创建、删除和重命名文件或目录。
3. **块管理**:跟踪哪些数据块属于哪个文件,以及这些块存储在哪些DataNode上。
**DataNode**是HDFS的存储节点,它们实际存储数据块。每个DataNode负责以下职责:
1. **数据存储**:接收来自NameNode的指令,存储和检索文件的各个数据块。
2. **心跳机制**:定期向NameNode发送心跳信息,报告其状态和存储容量,表明其在线状态。
3. **副本创建与复制**:根据HDFS的复制策略,DataNode会复制数据块以提供冗余和容错能力。
**HDFS的简单使用**:
在Hadoop环境中,用户可以通过`hdfs dfs`命令来交互式地操作HDFS。例如,可以使用`hdfs dfs -ls`列出目录中的文件和目录,`hdfs dfs -put`上传本地文件到HDFS,`hdfs dfs -get`下载HDFS中的文件到本地,以及`hdfs dfs -rm`删除HDFS中的文件等。
除了NameNode和DataNode,HDFS还包含其他组件,如Secondary NameNode(在Hadoop 2.x中被JournalNode取代),用于协助NameNode进行元数据备份和恢复,以及DataNode之间的通信协调,如ZooKeeper Failover Controller (ZKFC)。
HDFS通过NameNode和DataNode的协作,提供了大规模、高可用、容错的分布式存储解决方案,使得处理海量数据成为可能。理解并熟练掌握NameNode和DataNode的工作原理对于有效地使用和维护HDFS至关重要。
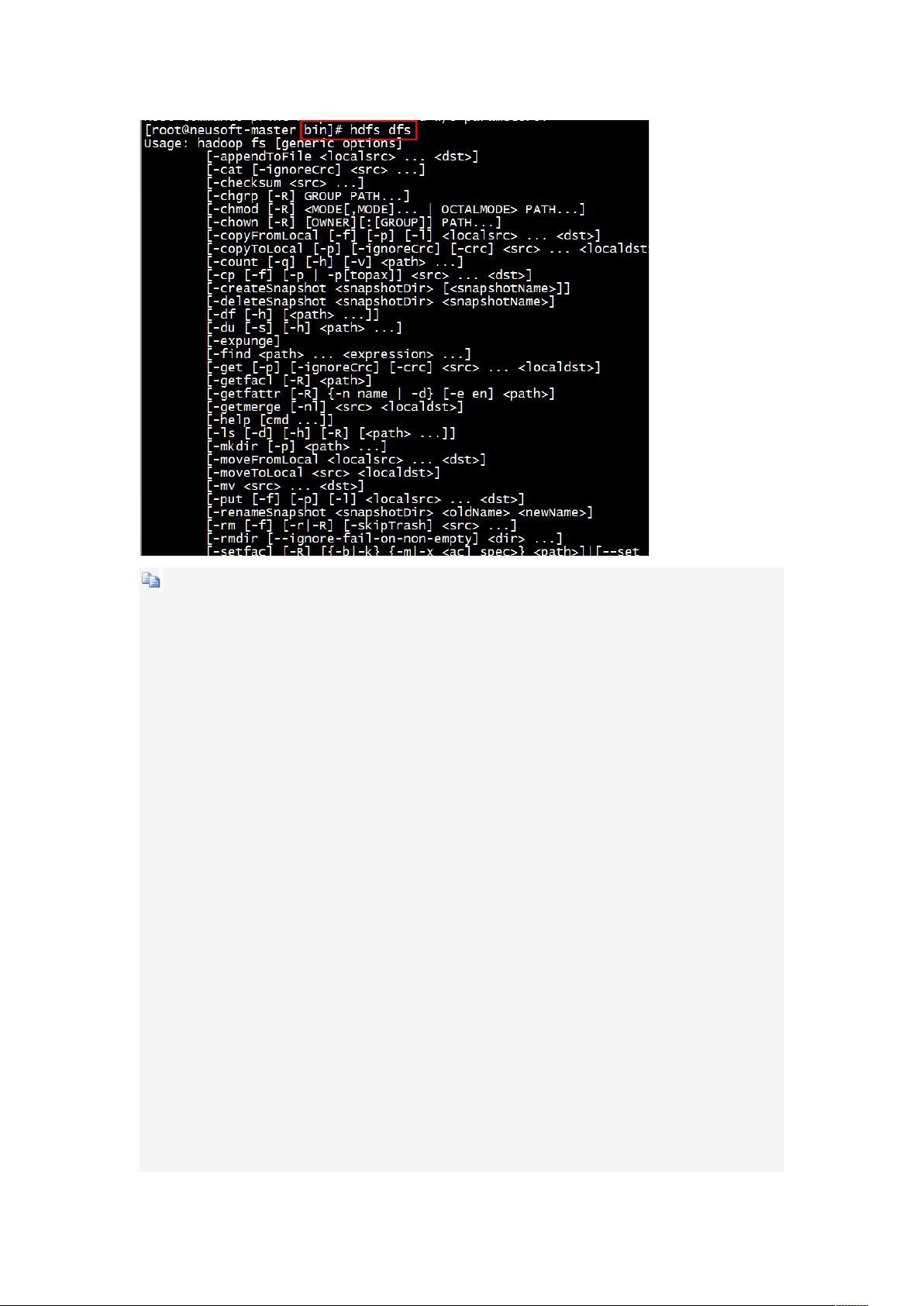
[root@neusoft-master bin]# hdfs dfs #一定在 bin 目录下执行 hdfs
命令
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] <path> ...]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-$nd <path> ... <expression> ...]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
剩余17页未读,继续阅读
2020-09-30 上传
2021-06-23 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-11-01 上传
点击了解资源详情

水不多
- 粉丝: 1
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
