思科无线AP1240AG快速配置步骤详解
需积分: 45 181 浏览量
更新于2024-07-23
收藏 667KB PDF 举报
"WLN00066-思科无线AP1240AG的快速配置手册提供了针对这款胖AP的初始设置指南,包括登陆信息、默认设置、射频和IP地址配置以及安全注意事项。"
这篇快速配置手册是为思科Aironet 1240AG系列无线接入点设计的,它主要关注的是如何快速有效地配置这个胖AP(FAT AP)。"胖AP"是指不依赖于无线控制器独立工作的接入点,它可以自行管理无线网络的连接和配置。
手册中指出,802.11a频率并不适用于1242G型号的AP,用户应关注802.11b和802.11g的相关内容。默认的登陆信息为用户名"Cisco"(区分大小写),密码同样为"Cisco"。AP的IP地址通常是通过DHCP动态获取,但如果无法获取,用户需要通过控制台接口手动配置IP地址、子网掩码和网关。
射频和IP地址的配置是初始化过程中的关键步骤。新购买的AP射频模块默认关闭,需要在配置时开启。在开始配置之前,确保有一台连接到同一网络的PC,并准备以下信息:AP的设备名称、802.11g和802.11a的SSID、SNMP管理信息(如果需要)、AP的MAC地址(如果使用Cisco IP地址设置软件),以及如果不能使用DHCP,需要手工地设定AP的IP信息。
关于安全,设备已经过FCC认证,RF射频对人体无害。不过,安装和运行时仍需注意:避免在设备运行时让天线靠近人体,特别是头部;设备应根据IEEE 802.3af标准和IEC 60950标准进行安装,同时设备内置电源保护措施,但电源输入不应超过其额定值。
安全警告部分强调了在连接电源前阅读安装手册的重要性,以及设备仅适用于符合特定电气标准的环境。此外,手册还包含了多语言的安全警告,以确保用户在安装和使用过程中遵循正确的操作流程,保障人身安全。
这份快速配置手册为用户提供了全面的指导,帮助他们成功地设置和启动思科1240AG无线AP,确保其在网络中的有效运作。
(7)产品文档
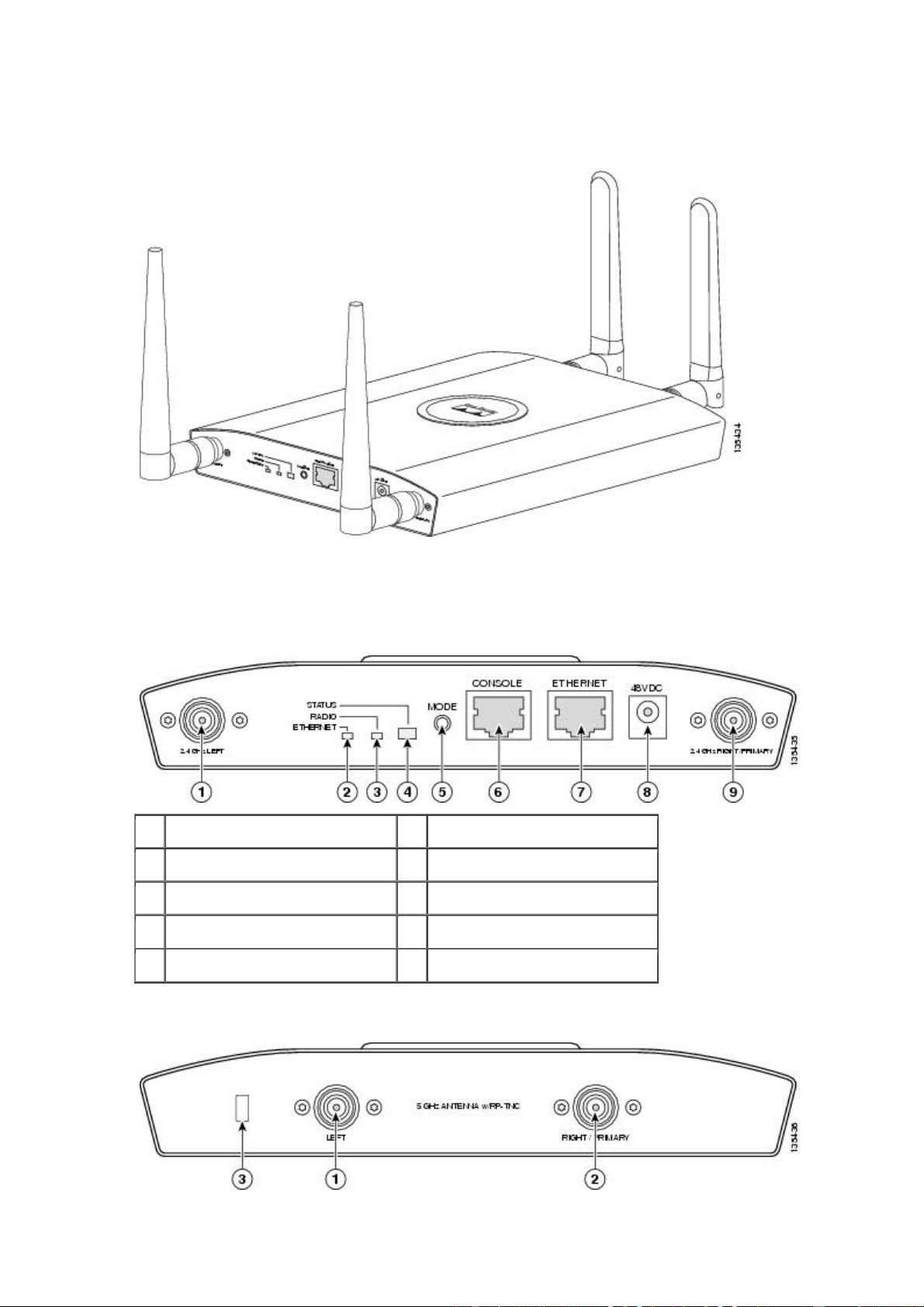
连接外部天线的 1240AG 无线 AP
【译者注】图中的 2.4G 和 5G 天线都是独立购买,设备不随机提供
2.4G 各接口位置
1 2.4-Ghz 左边天线 6 Console 口
2 以太网口灯 7 以太口
3 射频灯 8 48 V 直流电源口
4 状态灯 9 2.4-GHz 右边天线
5 模式按钮
5G 各接口位置
剩余16页未读,继续阅读
2022-03-10 上传
2022-03-10 上传
点击了解资源详情
点击了解资源详情
2023-06-10 上传
2023-05-29 上传
2023-05-25 上传

printlns
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
