《数据挖掘概念与技术(英文第2版)》课后习题答案解析
需积分: 12 46 浏览量
更新于2024-07-29
收藏 800KB PDF 举报
《数据挖掘:概念与技术(英文第2版)》是一本由Jiawei Han和Micheline Kamber编著的专业教材,针对数据挖掘领域的理论和技术进行了详尽讲解。该书是为伊利诺伊大学厄巴纳-香槟分校的学生和教师设计的,版权方Morgan Kaufmann于2006年出版。书中内容涵盖广泛,包括数据预处理、数据仓库与OLAP技术概述、数据立方体计算与数据概括、频繁模式挖掘、关联性和相关性分析、分类与预测、聚类分析、流数据、时间序列和序列数据挖掘、图矿、社交网络分析以及多关系数据挖掘等多个核心主题。
在课程中,作者通过课后习题的形式帮助读者巩固理论知识和实践技能。例如,在第一章“引论”中,习题1.1探讨了数据挖掘的定义,要求学生思考其定义并关注以下方面:(a)数据挖掘是否涵盖了哪些具体任务,如模式识别、异常检测和预测等;(b)数据挖掘与传统统计分析有何区别;(c)它如何应用于商业智能、机器学习和人工智能等领域。
第二章至第十章分别深入剖析了数据预处理的重要性,数据仓库和在线分析处理工具的应用,数据立方体的构建及其在数据概括中的作用,频繁模式和关联规则的挖掘,分类与预测模型的建立,聚类方法的原理和应用,以及如何处理实时流数据、时间序列数据以及复杂的数据结构如图形和文本。每一章末尾都配有详细的习题,旨在促使读者通过实践来理解和掌握各种数据挖掘技术和算法。
此外,书中还介绍了数据挖掘在实际应用中的趋势和发展,如在物联网、社交媒体和大数据时代的最新挑战和机遇。最后的练习题11.7可能涉及到综合应用所学知识,分析现实世界中的数据挖掘问题,或者讨论未来数据挖掘技术的发展方向。
通过阅读这本教材并完成课后习题,读者将建立起扎实的数据挖掘基础,了解并掌握关键技术和工具,为在IT行业中成为一名有效的问题发现者和解决方案提供者打下坚实的基础。对于希望进一步提升数据处理能力、探索潜在信息模式和预测趋势的人员,这本书是不可或缺的学习资源。

14 CHAPTER 2. DATA PREPROCESSING
2.3. Give three additional commonly used statistical measures (i.e., not illustrated in this chapter) for the
characterization of data dispersion, and discuss how they can be computed efficiently in large databases.
Answer:
Data dispersion, also known as variance analysis, is the degree to which numeric data tend to spread and can
be characterized by such statistical measures as mean deviation, measures of skewness, and the coefficient
of variation.
The mean deviation is defined as the arithmetic mean of the absolute deviations from the means and is
calculated as:
mean deviation =
P
N
i=1
|x − ¯x|
N
, (2.1)
where ¯x is the arithmetic mean of the values and N is the total number of values. This value will be greater
for distributions with a larger spread.
A common measure of skewness is:
¯x − mode
s
, (2.2)
which indicates how far (in standard deviations, s) the mean (¯x) is from the mode and whether it is greater
or less than the mode.
The coefficient of variation is the standard deviation expressed as a percentage of the arithmetic mean
and is calculated as:
coefficient of variation =
s
¯x
× 100 (2.3)
The variability in groups of observations with widely differing means can be compared using this measure.
Note that all of the input values used to calculate these three statistical measures are algebraic measures.
Thus, the value for the entire database can be efficiently calculated by partitioning the database, computing
the values for each of the separate partitions, and then merging theses values into an algebraic equation
that can be used to calculate the value for the entire database.
The measures of dispersion described here were obtained from: Statistical Methods in Research and Pro duc-
tion, fourth ed., edited by Owen L. Davies and Peter L. Goldsmith, Hafner Publishing Company, NY:NY,
1972.
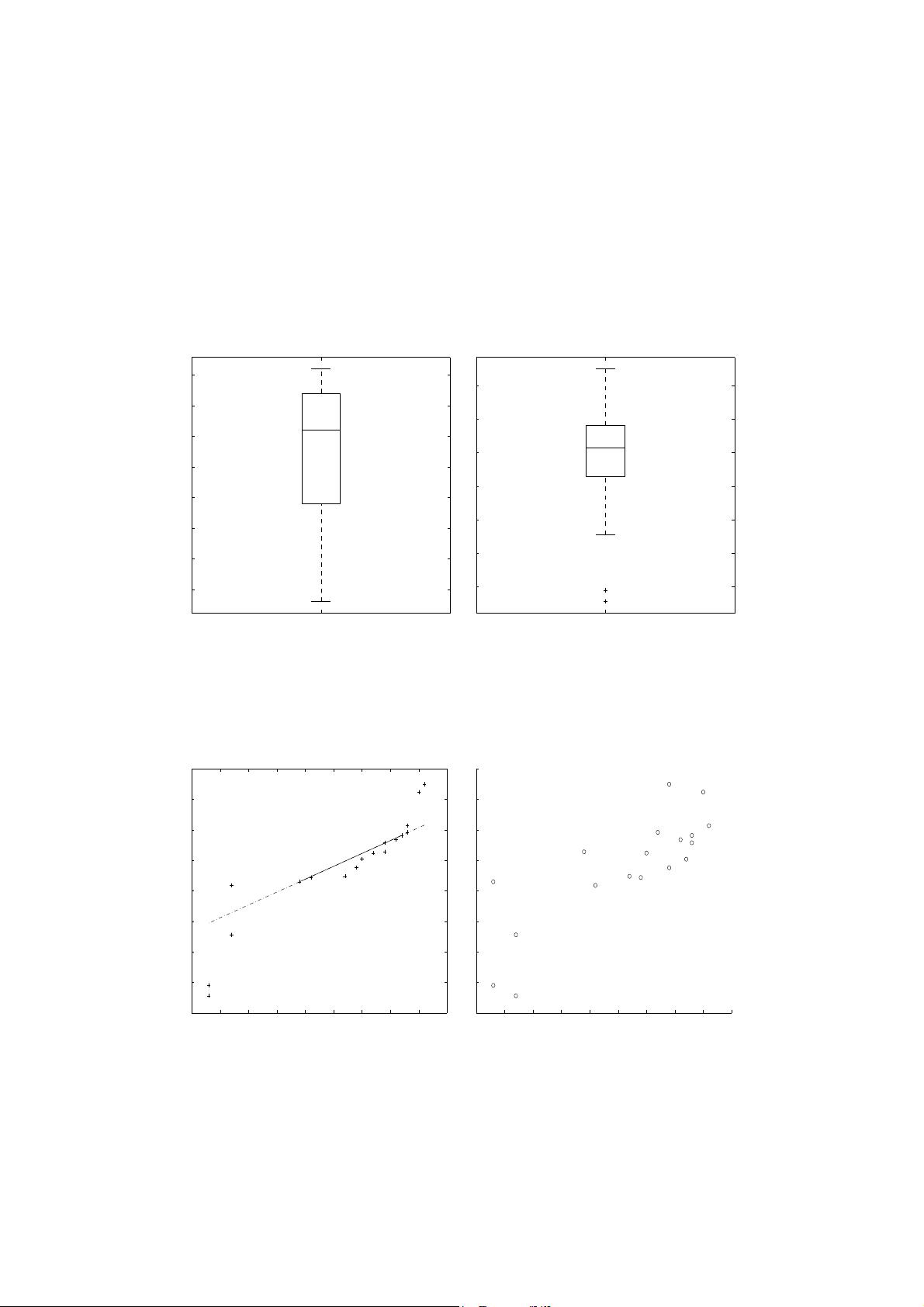
2.4. Suppose that the data for analysis includes the attribute age. The age values for the data tuples are (in
increasing order) 13, 15, 16, 16, 19, 20, 20, 21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45,
46, 52, 70.
(a) What is the mean of the data? What is the median?
(b) What is the mode of the data? Comment on the data’s modality (i.e., bimodal, trimodal, etc.).
(c) What is the midrange of the data?
(d) Can you find (roughly) the first quartile (Q1) and the third quartile (Q3) of the data?
(e) Give the five-number summary of the data.
(f) Show a boxplot of the data.
(g) How is a quantile-quantile plot different from a quantile plot?



剩余134页未读,继续阅读
2018-07-01 上传
2021-04-13 上传
点击了解资源详情
2022-11-12 上传
726 浏览量
2022-11-10 上传

jane_lj
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Accuinsight-1.0.4-py2.py3-none-any.whl.zip
- yama:Yama的编译器,一种面向对象的微控制器语言,例如ARM Cortex-M和AVR
- ap-event-lib:事件框架库
- 队列分析
- docker-compose2.172下载后拷贝到/usr/local/bin下
- webstore
- Employee-Summary
- media-source-demo:媒体源演示
- 家:普拉特姆学院
- LilSteve:第175章
- tilde-world
- Accuinsight-1.0.25-py2.py3-none-any.whl.zip
- 标题栏随着RecyclerView滚动背景渐变
- 浏览器自定义查看pdf文件.rar
- 直接序列扩频(DS SS):这是直接序列扩频的代码。-matlab开发
- flutter_dylinkios_sample:使用Dart的示例项目
