Transformer中的Self-attention机制深度解析
需积分: 0 193 浏览量
更新于2024-08-05
收藏 1.41MB PDF 举报
"本文将深入探讨Self-attention机制和Transformer架构,主要关注它们在机器学习,尤其是自然语言处理中的应用。Self-attention是一种创新的注意力机制,它允许模型在处理序列数据时,考虑每个元素与序列中所有其他元素的关系,而非仅仅局限于局部上下文。Transformer则是基于Self-attention构建的一种序列到序列的模型,广泛应用于翻译、文本生成等任务。"
Self-attention机制是现代深度学习模型中的关键组成部分,尤其在Transformer架构中发挥着核心作用。该机制的核心思想是通过计算输入序列中每个位置的vector与其他位置vector之间的相关性,生成一个注意力分布,从而权重化地融合序列中的信息。这种全局的注意力机制使得模型能够捕获更远距离的依赖关系,打破了传统循环神经网络(RNN)和卷积神经网络(CNN)受限的局部视野。
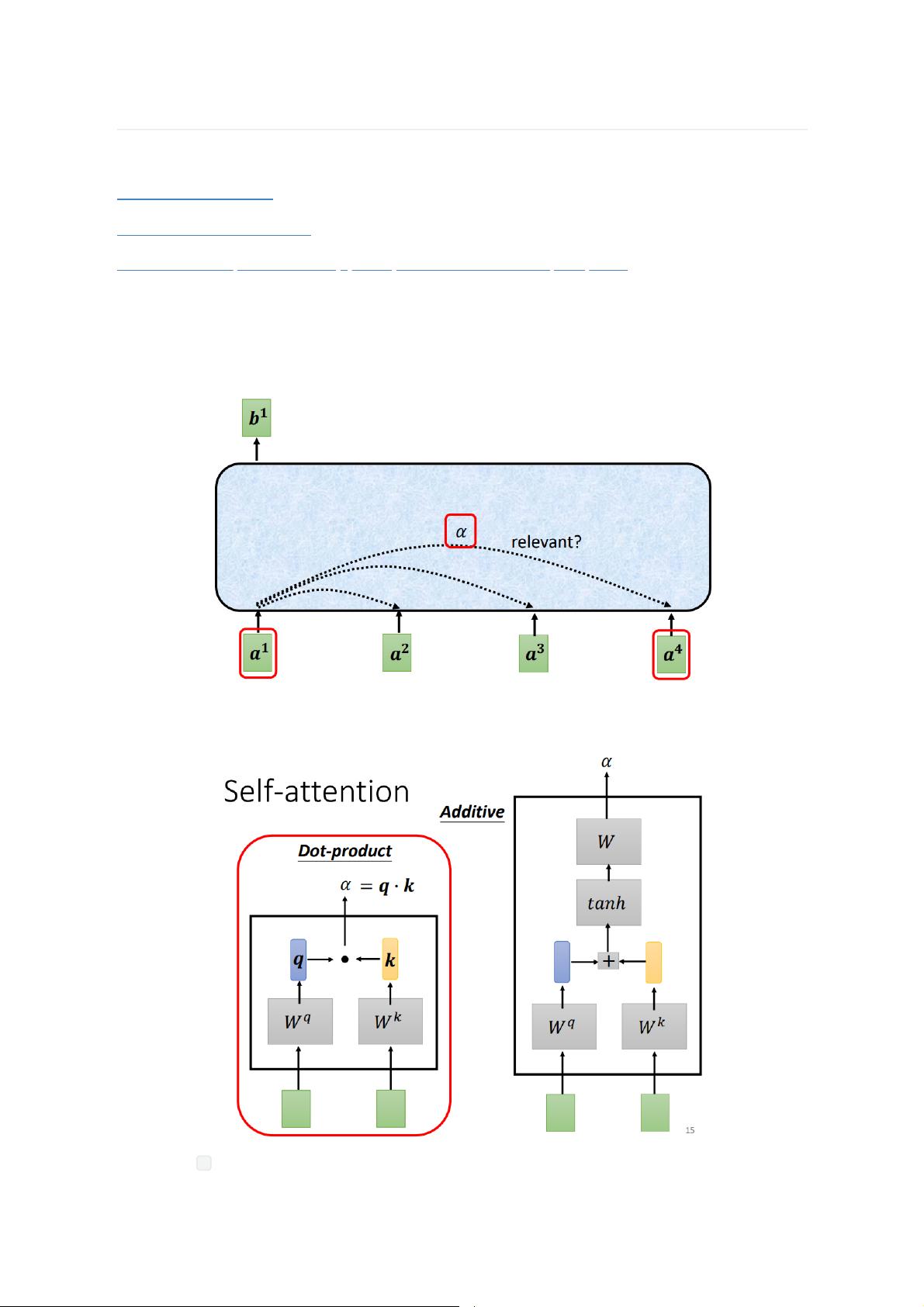
Self-attention有两种实现方式,即Dot-product式和Additive式。Transformer模型采用的是Dot-product方式,因为它计算效率更高,同时也能够捕捉到丰富的信息。在这一方法中,输入序列的每个位置首先经过不同的线性变换生成query、key和value向量。query向量用于衡量当前位置与其他位置的匹配程度,key向量用于被query向量匹配,而value向量则携带了每个位置的实际信息。
计算过程如下:
1. 对每个位置的输入vector,使用不同的参数矩阵WQ、WK和WV进行线性变换,分别得到query、key和value向量。
2. 计算query向量与所有位置的key向量的点积,得到注意力系数,这反映了不同位置的相关性。
3. 使用softmax函数对注意力系数进行归一化,确保它们的和为1,形成注意力分布。
4. 将value向量与归一化的注意力系数加权求和,得到每个位置的新输出。
整个Self-attention层对输入序列的所有位置执行上述操作,并且参数矩阵WQ、WK和WV在所有位置间共享,这样可以通过矩阵运算高效地实现。通过这种方式,Self-attention层能够生成考虑全局上下文的新表示,为后续的模型层提供更丰富的信息。
Transformer模型由多个这样的Self-attention层堆叠而成,通常还包含一个前馈神经网络层,以增加模型的非线性表达能力。此外,Transformer还引入了残差连接和层归一化,以促进梯度传播和模型稳定训练。
总结来说,Self-attention与Transformer的结合为序列建模提供了新的视角,使得模型能够高效地处理长距离依赖,并在多种自然语言处理任务中展现出优秀的性能。这一机制也启发了其他领域,如计算机视觉和音频处理,进一步推动了多模态学习的发展。
详解Self-attention与Transformer
【参考文献】
李宏毅机器学习2021春
The Illustrated Transformer
Transformers Explained Visually (Part 3): Multi-head Attention, deep dive
Self-attention
Self-attention会计算输入序列中指定位置的vector与其他位置的vector之间的相关关系,然后以此进行
聚合得到新的输出。
Self-attention有两种形式:Dot-product 式和 Additive 式,Transformer 结构中使用的是前者,而
后者使用在类似 GAT 的网络结构中。
(上图中的 + 代表 concatenate 操作)
下载后可阅读完整内容,剩余8页未读,立即下载
2024-07-18 上传
2021-04-11 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-04-20 上传
点击了解资源详情
点击了解资源详情

Asama浅间
- 粉丝: 583
- 资源: 299
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
