数据挖掘:深入解析异常值处理策略
版权申诉
本文主要探讨了数据挖掘过程中异常值处理的重要性以及常见的异常值检测方法。
在数据挖掘领域,数据清洗是至关重要的步骤,其中异常值处理是数据预处理的关键环节。异常值,又称为离群点,是数据集中显著不同于其他数据点的个体,可能由于测量错误、数据输入失误或特定事件导致。与噪声数据不同,噪声通常被视为随机误差,需要在预处理阶段去除以提高后续分析的准确性。离群点检测的目的在于识别出那些可能源自不同分布或由特殊原因产生的数据点。
异常值的成因多种多样,包括数据来源差异、自然变异、测量或收集过程中的误差等。识别这些离群点有助于理解数据的内在结构和潜在问题。例如,如果一个房屋数据集中出现面积过大或卧室数量异常的情况,这些可能就是需要处理的异常值。
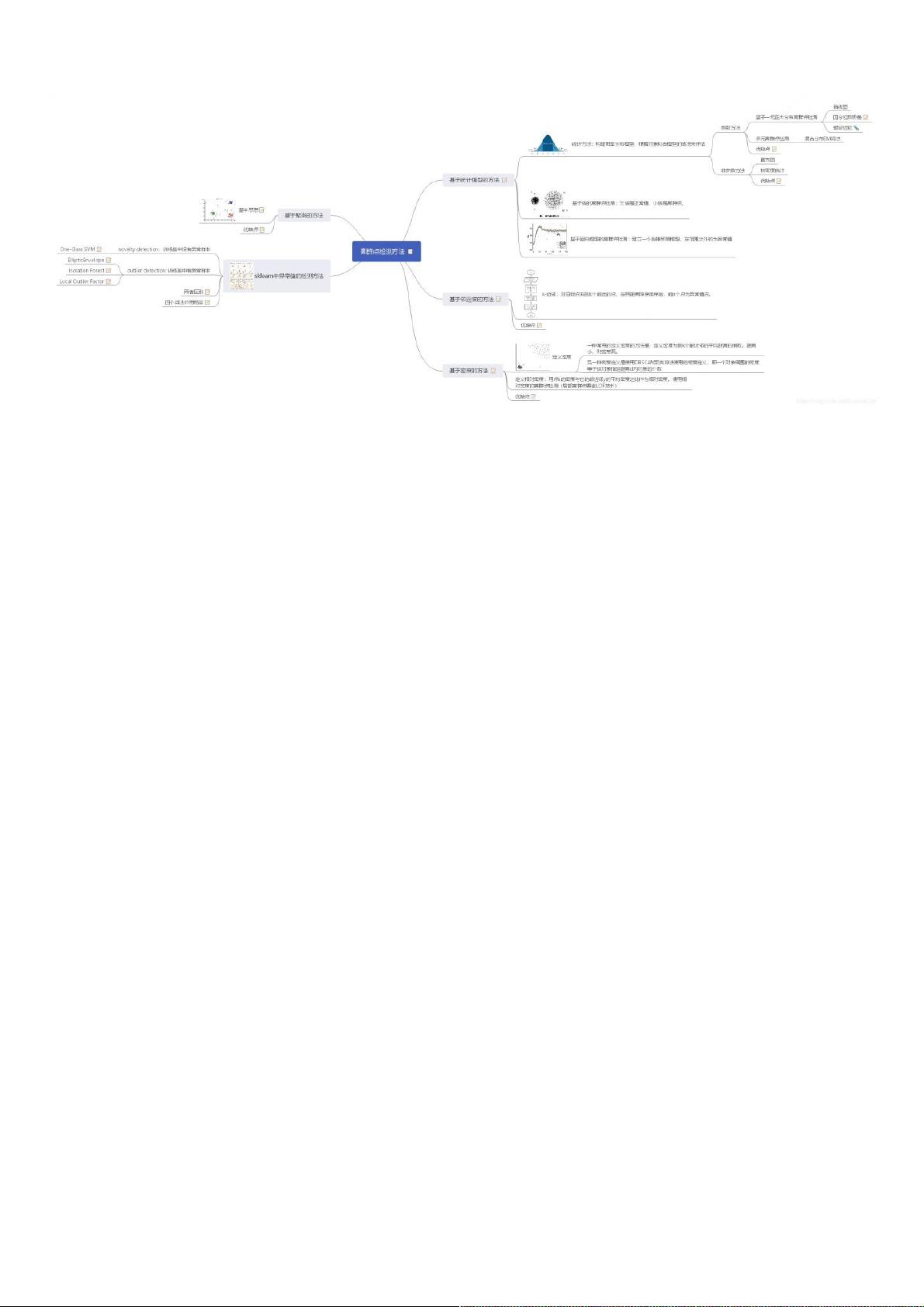
检测离群点的方法有多种。一种是基于统计模型的方法,通过构建数据模型来识别不匹配的对象;如果使用聚类模型,异常值可能是不属于任何主要群体的点;在回归分析中,异常值可能远离预测值。第二种方法是基于邻近度,通过度量对象间的距离来确定哪些点与其他点相距较远。第三种是基于密度的方法,将局部密度显著低于周围点的点标记为离群点。第四种是基于聚类的方法,通过聚类分析找到紧密相关的对象群,而异常值则与这些群体疏远。
统计学上的假设检验也是常用手段,例如利用正态分布进行一元离群点检测。在这种方法中,先假设数据服从特定的概率分布(如正态分布),然后计算每个数据点的分布概率,低概率的点被认为是离群点。但这种方法依赖于准确的分布假设,如果数据实际分布并非如此,结果可能会受到影响。
异常值处理是数据挖掘中不可或缺的部分,它涉及到数据质量的提升和分析结果的可靠性。通过运用各种检测方法,我们可以更有效地识别并处理这些异常值,从而提高模型的预测能力和洞察力。无论是基于统计模型、邻近度、密度还是聚类,每种方法都有其适用场景,选择合适的方法取决于具体的数据特性和分析目标。在实际应用中,结合多种方法往往能获得更全面的结果。
数据挖掘:数据清洗数据挖掘:数据清洗——异常值处理异常值处理
数据挖掘:数据清洗数据挖掘:数据清洗——异常值处理异常值处理
一、离群点是什么?一、离群点是什么?
离群点,是一个数据对象,它显著不同于其他数据对象,与其他数据分布有较为显著的不同。有时也称非离群点为“正常数据”,离群点为“异常数据”。
离群点跟噪声数据不一样,噪声是被观测变量的随机误差或方差。一般而言,噪声在数据分析(包括离群点分析)中不是令人感兴趣的,需要在数据预处理中剔除的,减少对后续模
型预估的影响,增加精度。
离群点检测是有意义的,因为怀疑产生它们的分布不同于产生其他数据的分布。因此,在离群点检测时,重要的是搞清楚是哪种外力产生的离群点。
常见的异常成因:
数据来源于不同的类(异常对象来自于一个与大多数数据对象源(类)不同的源(类)的思想)
自然变异
数据测量或收集误差。
通常,在其余数据上做各种假设,并且证明检测到的离群点显著违反了这些假设。如统计学中的假设检验,基于小概率原理,对原假设进行判断。一般检测离群点,是人工进行筛
选,剔除不可信的数据,例如对于房屋数据,面积上万,卧室数量过百等情况。而在面对大量的数据时,人工方法耗时耗力,因此,才有如下的方法进行离群点检测。
二、常用的离群点的检测方法二、常用的离群点的检测方法
【1】基于统计模型的方法:
首先建立一个数据模型,异常是那些同模型不能完美拟合的对象;
如果模型是簇的集合,则异常是不显著属于任何簇的对象;
在使用回归模型时,异常是相对远离预测值的对象。
【2】基于邻近度的方法:通常可以在对象之间定义邻近性度量,异常对象是那些远离其他对象的对象。
【3】基于密度的方法:仅当一个点的局部密度显著低于它的大部分近邻时才将其分类为离群点。
【4】基于聚类的方法:聚类分析用于发现局部强相关的对象组,而异常检测用来发现不与其他对象强相关的对象。因此,聚类分析非常自然的可以用于离群点检测。
三、三、 基于分布(概率模型)的假设检验的方法:基于分布(概率模型)的假设检验的方法:
基于统计模型的方法:基于统计模型的方法:
统计方法统计方法
统计方法。统计学方法是基于模型的方法,即为数据创建一个模型,并且根据对象拟合模型的情况来评估它们。大部分用于离群点检测的统计学方法都是构建一个概率分布模型,并
考虑对象有多大可能符合该模型。
离群点的概率定义:离群点是一个对象,关于数据的概率分布模型,它具有低概率离群点的概率定义:离群点是一个对象,关于数据的概率分布模型,它具有低概率。这种情况的前提是必须知道数据集服从什么分布,如果估计错误就造成了重尾分布。
参数方法:参数方法:
1.基于正态分布的一元离群点检测
当数据服从正太分布的假设时在正态分布的假定下,u±3σ区域包含99.7%的数据,u±2σ包含95.4%的数据,u±1σ包含68.3%的数据。其区域外的数据视为离群点。
计算得到计算得到:通过绘制箱线图可以直观地找到离群点,或者通过计算四分位数极差(IQR)定义为Q3-Q1。比Q1小1.5倍的IQR或者比Q3大1.5倍的IQR的任何对象都视为离群点,因为
Q1-1.5IQR
和
Q3+1.5IQR之间的区域包含了99.3%的对象。
假设检验假设检验:根据问题的需要对所研究的总体作某种假设,记作H0;选取合适的统计量,这个统计量的选取要使得在假设H0成立时,其分布为已知;由实测的样本,计算出统计量的
值,并根据预先给定的显著性水平进行检验,作出拒绝或接受假设H0的判断。常用的假设检验方法有u—检验法、t检验法、χ2检验法(卡方检验)、F—检验法,秩和检验(非参数)等。
假设检验检测离群点原理
2.多元离群点检测
使用混合参数分布在许多情况下,数据是由正态分布产生的假定很有效。然而,当实际数据很复杂时,这种假定过于简单。在这种情况下,假定数据是被混合参数分布产生的。混合
参数分布中用期望最大化(EM)算法来估计参数。
异常检测的混合模型方法:对于异常检测,数据用两个分布的混合模型建模,一个分布为普通数据,而另一个为离群点。
聚类和异常检测目标都是估计分布的参数,以最大化数据的总似然(概率)。聚类时,使用EM算法估计每个概率分布的参数。然而,这里提供的异常检测技术使用一种更简单的方
法。初始时将所有对象放入普通对象集,而异常对象集为空。然后,用一个迭代过程将对象从普通集转移到异常集,只要该转移能提高数据的总似然(其实等价于把在正常对象的分初始时将所有对象放入普通对象集,而异常对象集为空。然后,用一个迭代过程将对象从普通集转移到异常集,只要该转移能提高数据的总似然(其实等价于把在正常对象的分
布下具有低概率的对象分类为离群点)。布下具有低概率的对象分类为离群点)。(假设异常对象属于均匀分布)。异常对象由这样一些对象组成,这些对象在均匀分布下比在正常分布下具有显著较高的概率。
优缺点:优缺点:
(1)优点优点:有坚实的统计学理论基础,当存在充分的数据和所用的检验类型的知识时,这些检验可能非常有效;
(2)缺点缺点:大多数方法是针对一元数据的,而对于多元数据,可用的选择少一些,并且对于高维数据,这些检测可能性很差。
下载后可阅读完整内容,剩余6页未读,立即下载
138 浏览量
点击了解资源详情
490 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
811 浏览量
2007-09-07 上传
732 浏览量

weixin_38557980
- 粉丝: 7
- 资源: 925
 我的内容管理
展开
我的内容管理
展开







最新资源
- 串 行 通 信 论 谈
- oracle集群完全配置手册
- AJAX In Action(中文版) .pdf
- IDL入门与提高(教程) 编程
- 计算机三级上机试题--南开一百题
- Joomla开发.PDF
- ATSC Standard:Program and System Information Protocol for Terrestrial Broadcast and Cable
- visual basic发展历程
- 新一代存储器MRAM
- JAVA电子书Thinking.In.Java.3rd.Edition.Chinese.eBook
- 经典算法(c语言),51个经典算法
- 高质量c/c++编程指南
- DSP基本知识学习入门
- C程序设计 第二版 PDF
- 操作系统课设 进程调度模拟程序
- 2008年4月计算机等级考试软件测试工程师试题
