HDFS入门:分布式文件系统的大数据存储与监控
需积分: 35 201 浏览量
更新于2024-07-18
1
收藏 1.22MB PDF 举报
分布式文件系统HDFS(Hadoop Distributed File System)是一种专为大数据处理设计的高容错、高可扩展性的存储系统,由Apache Hadoop项目提供。HDFS的设计目标是应对大规模数据集,并侧重于流式数据访问,不适合频繁的随机读写,而是更适合批量数据的处理。它采用了一种简单的数据一致性模型,文件一旦写入并关闭,即不可修改,以降低系统的复杂性。
HDFS的核心在于其独特的体系结构,包括以下几个关键组件:
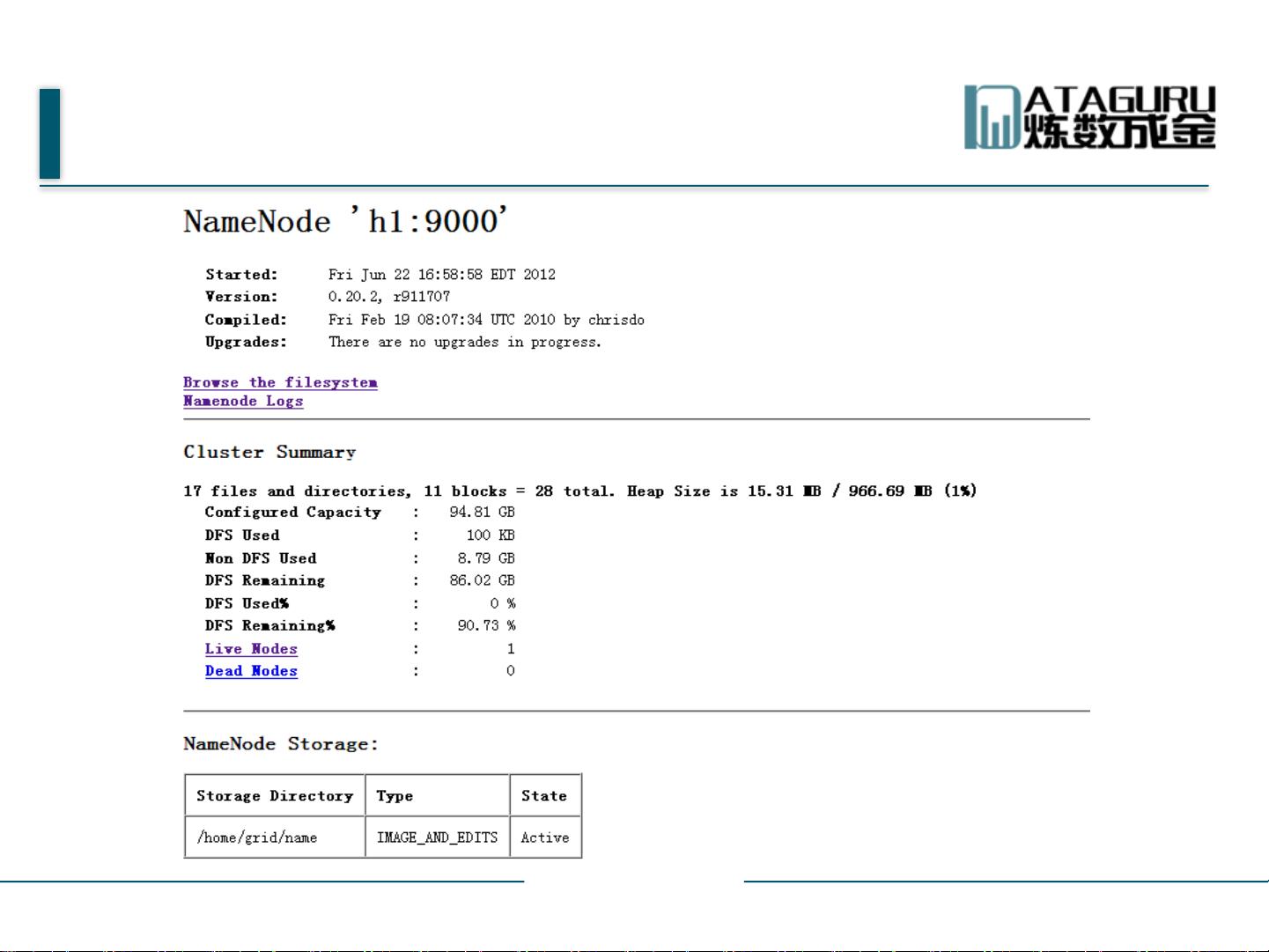
1. **NameNode**: 名称节点是整个HDFS系统的中心管理者,负责维护文件系统的命名空间,即目录树和文件的元数据,如文件大小、块分布等。它还记录了每个文件的数据块在哪些DataNode上。
2. **DataNode**: DataNode是实际存储数据的节点,它们接收NameNode的指令,存储用户的文件数据块。这些节点具有冗余备份,以应对硬件故障,确保数据的持久性和可靠性。
3. **事务日志**:用于记录NameNode的状态变更,保证在系统崩溃时能够恢复到一个一致的状态。
4. **映射文件**:也称为fsimage文件,它存储NameNode关于文件系统的完整视图,用于数据恢复和检查点操作。
5. **SecondaryNameNode**:这是一个辅助角色,定期与NameNode进行心跳,接收并合并其状态更改,用于定期清理和优化命名空间。
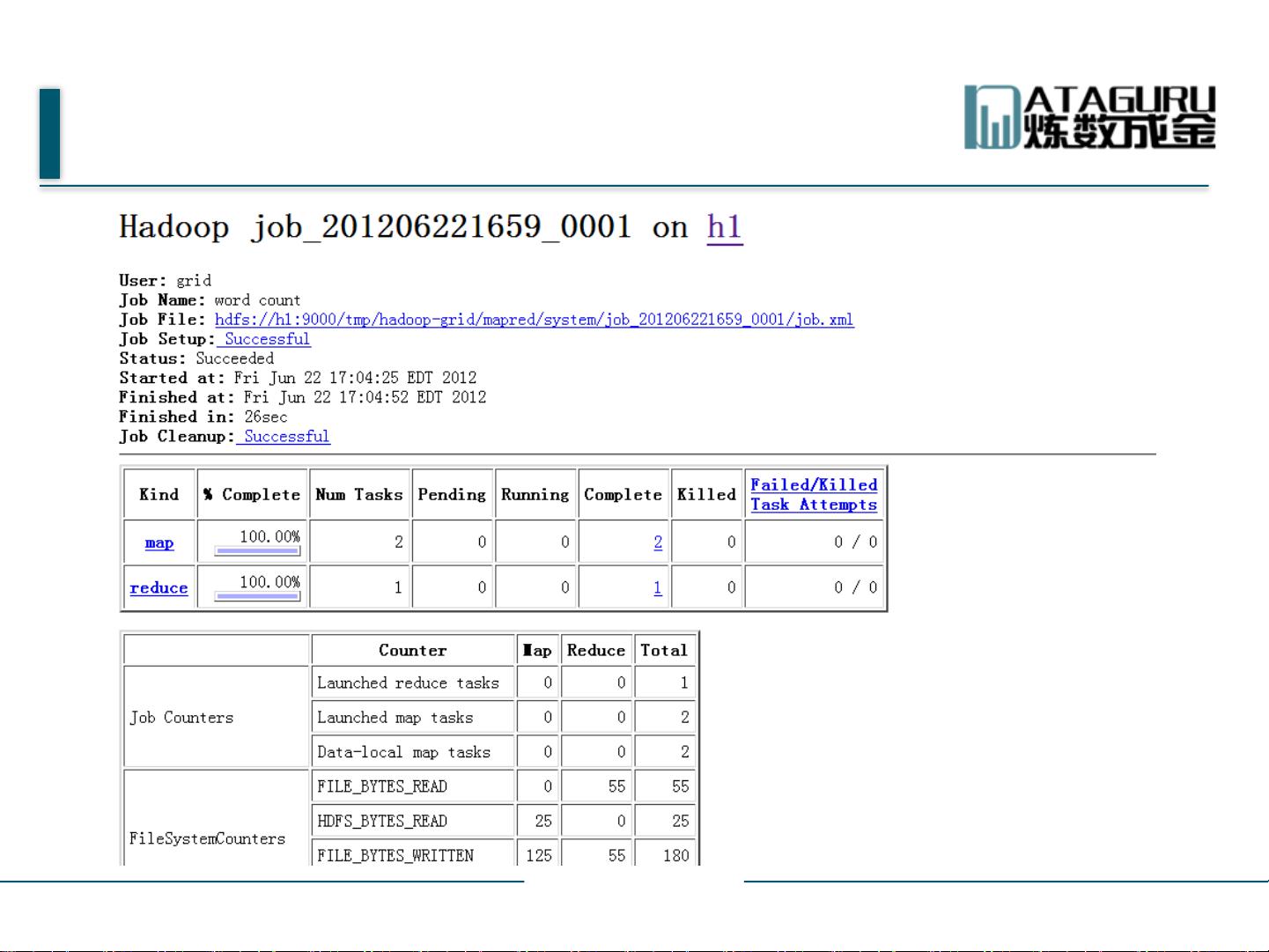
要验证HDFS是否正常运行,可以通过Web界面进行监控。例如,可以访问JobTracker节点的50030端口查看Jobtracker的监控页面,以及访问Namenode节点的50070端口监控集群健康状况,比如查看jobtracker.jsp或dfshealth.jsp页面。
此外,学习HDFS还包括了如何通过浏览器查看日志,理解数据的实际存储位置,以及熟悉数据写入后如何根据数据访问模式(如“数据就近”原则)在节点间进行分布。HDFS的学习重点在于其设计哲学、架构细节以及使用场景的适应性,这对于大数据分析平台的理解至关重要。
DATAGURU专业数据分析网站
2012.9.3
Jobtracker监控
8
剩余43页未读,继续阅读
2020-06-14 上传
2021-02-24 上传
2020-08-20 上传
2023-06-28 上传
2024-09-15 上传
2023-05-23 上传
2024-11-06 上传
2023-03-17 上传
2023-05-13 上传

南方五宿放眼观_犹如潇湘黛未施
- 粉丝: 8
- 资源: 23
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
