HBase架构解析:分布式列式存储的基石
32 浏览量
更新于2024-08-28
收藏 376KB PDF 举报
"详解HBase架构原理"
HBase是一种基于分布式文件系统的列式数据库,它源自Google BigTable的设计理念,是Apache Hadoop生态系统的一部分。HBase旨在处理大规模数据,提供高可靠性、高性能的存储解决方案,特别适合实时查询和大数据分析场景。
在HBase的架构中,数据存储在Hadoop的HDFS上,这为HBase提供了高容错性和可扩展性。同时,HBase利用Hadoop的MapReduce框架来处理批量数据操作,如数据导入和复杂计算,确保了处理海量数据的能力。
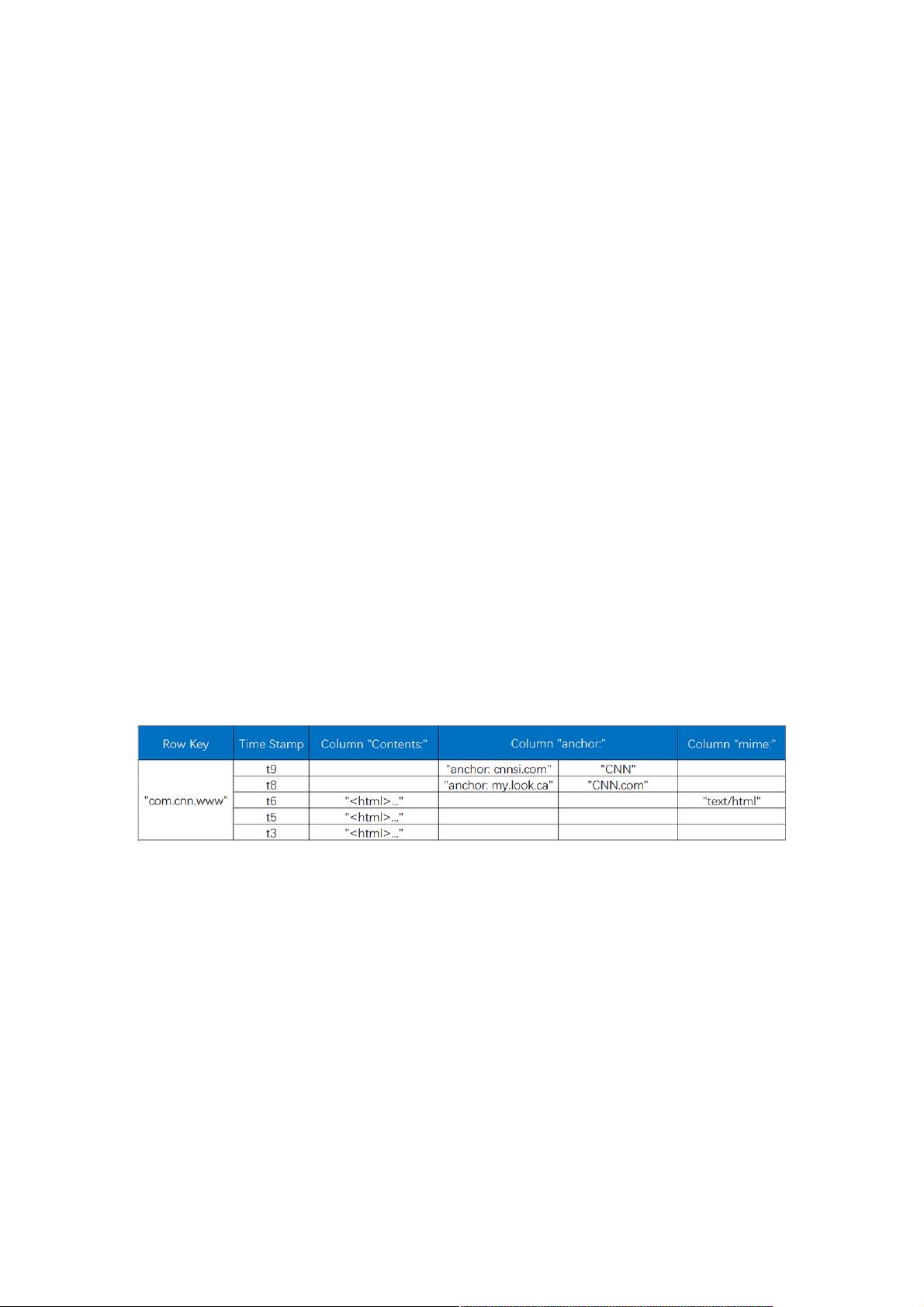
HBase的核心设计模型包括RowKey(行键)、Timestamp(时间戳)和Column(列)。RowKey是表中每一行的唯一标识,通常设计为能够快速定位数据的键值。Timestamp用于记录每次数据修改的时间,支持多版本数据存储。Column由Column Family(列簇)和Qualifier(列标签)组成,列簇是一组相关的列集合,Qualifier是列簇内的具体列,两者组合形成唯一的列标识。
逻辑存储模型方面,HBase表格由行和列簇构成。行键(RowKey)是按照字典序排序的,设计时应考虑查询模式,以便优化数据访问。列簇是预定义的,数据按列簇进行组织,同一列簇内的数据物理上存储在一起,有利于提高读写性能。列标签则可以在运行时动态添加,增强了系统的灵活性。
HBase的操作主要有三种:通过单个rowkey访问、rowkey范围访问和全表扫描。由于RowKey的字典序排序,对于范围查询尤其高效。此外,行级操作的原子性确保了并发环境下的数据一致性。
HBase还依赖Zookeeper作为协同服务,提供分布式协调,如节点状态管理、配置同步等,确保集群的稳定运行。
HBase是构建在Hadoop之上的分布式数据库,其核心优势在于高并发、低延迟的读写能力以及对大规模数据的处理。HBase的架构设计使其在实时大数据应用场景中表现出色,如互联网日志分析、物联网数据存储等。理解并掌握HBase的架构原理和设计模型,对于构建高效的分布式存储解决方案至关重要。
详解详解HBase架构原理架构原理
一、什么是HBase
HBase是一个高可靠、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价的PC Server上搭建大规模结构
化存储集群。
HBase是Google BigTable的开源实现,与Google BigTable利用GFS作为其文件存储系统类似,HBase利用Hadoop HDFS作
为其文件存储系统;
Google运行MapReduce来处理BigTable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;
Google BigTable利用Chubby作为协同服务,HBase利用Zookeeper作为协同服务。
二、HBase设计模型
HBase中的每一张表就是所谓的BigTable。BigTable会存储一系列的行记录,行记录有三个基本类型的定义:
1.RowKey
是行在BigTable中的唯一标识。
2.TimeStamp:
是每一次数据操作对应关联的时间戳,可以看作SVN的版本。
3.Column:
定义为<family>:<label>,通过这两部分可以指定唯一的数据的存储列,family的定义和修改需要对HBase进行类似于DB的
DDL操作,
而label,不需要定义直接可以使用,这也为动态定制列提供了一种手段。family另一个作用体现在物理存储优化读写操作上,
同family
的数据物理上保存的会比较接近,因此在业务设计的过程中可以利用这个特性。
1. 逻辑存储模型
HBase以表的形式存储数据,表由行和列组成。列划分为若干个列簇,如下图所示:
下面是对表中元素的详细解析:
RowKey
与NoSQL数据库一样,rowkey是用来检索记录的主键。访问HBase Table中的行,只有三种方式:
1.通过单个rowkey访问
2.通过rowkey的range
3.全表扫描
rowkey行键可以任意字符串(最大长度64KB,实际应用中长度一般为10-100bytes),在HBase内部RowKey保存为字节数
组。
存储时,数据按照RowKey的字典序(byte order)排序存储,设计key时,要充分了解这个特性,将经常一起读取的行存放在
一起。
需要注意的是:行的一次读写是原子操作(不论一次读写多少列)
列簇
HBase表中的每个列,都归属于某个列簇,列簇是表的schema的一部分(而列不是),必须在使用表之前定义。列名都以列
簇作为前缀。例如:
下载后可阅读完整内容,剩余4页未读,立即下载
2018-12-03 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38502693
- 粉丝: 8
- 资源: 908
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
