优化云计算性能:内存去重与分区策略
107 浏览量
更新于2024-08-26
收藏 2.04MB PDF 举报
云计算作为一种高效且弹性的计算服务,其性能优化一直受到广泛关注。本文探讨了如何通过协调内存重复数据删除(Memory Deduplication)和分区(Memory Partition)技术来提升云计算环境中的性能。首先,内存重复数据删除是针对虚拟化环境中内存资源效率问题提出的一种解决方案。它通过检测具有相同内容的页面,并将它们合并为单份副本,从而显著减少内存需求。这在大数据分析、存储和多租户环境中尤其重要,因为大量的重复数据会占用宝贵的系统资源,影响整体性能。
重复数据删除算法通常采用哈希或内容感知的方法来确定页面是否具有相同内容。通过在物理存储层面上实现这一过程,可以避免频繁的I/O操作,提高数据读取速度。然而,这种方法也带来了一些挑战,如如何在保持数据一致性的同时处理并发访问和更新,以及如何管理缓存策略。
另一方面,内存分区是一种针对虚拟机之间内存干扰的优化策略。它根据页面的颜色特性,为每个虚拟机分配独特的内存区域,这样可以减少由于不同虚拟机对同一内存地址空间的竞争而引起的性能瓶颈。这种隔离有助于提高资源利用率,特别是对于那些内存敏感型应用,例如数据库和实时分析工具,它们对内存访问速度和一致性有较高要求。
在实际应用中,协调内存重复数据删除和分区需要综合考虑多种因素,如内存分配策略、虚拟机的负载均衡、数据迁移的开销以及可能的性能监控和调整机制。理想情况下,一个有效的解决方案应该能在减少内存消耗和提高并发性能之间找到平衡,同时还要考虑到系统的可扩展性和稳定性。
本文的研究成果基于2015年的一篇 IEEE 论文,作者 Gangyong Jia、Guangjie Han、Joel J.P.C. Rodrigues 和 Jaime Lloret 通过深入理论分析和实验验证,展示了他们的方法在实际云计算环境中的可行性与有效性。论文引用了 Digital Object Identifier (DOI) 10.1109/TCC.2015.2511738,发表在 IEEE Transactions on Cloud Computing 上,这篇即将在后续期刊版面发布的文章提供了关于如何优化云计算性能的实用指导,为云计算架构师和开发者提供了有价值的设计参考。
2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TCC.2015.2511738, IEEE
Transactions on Cloud Computing
3
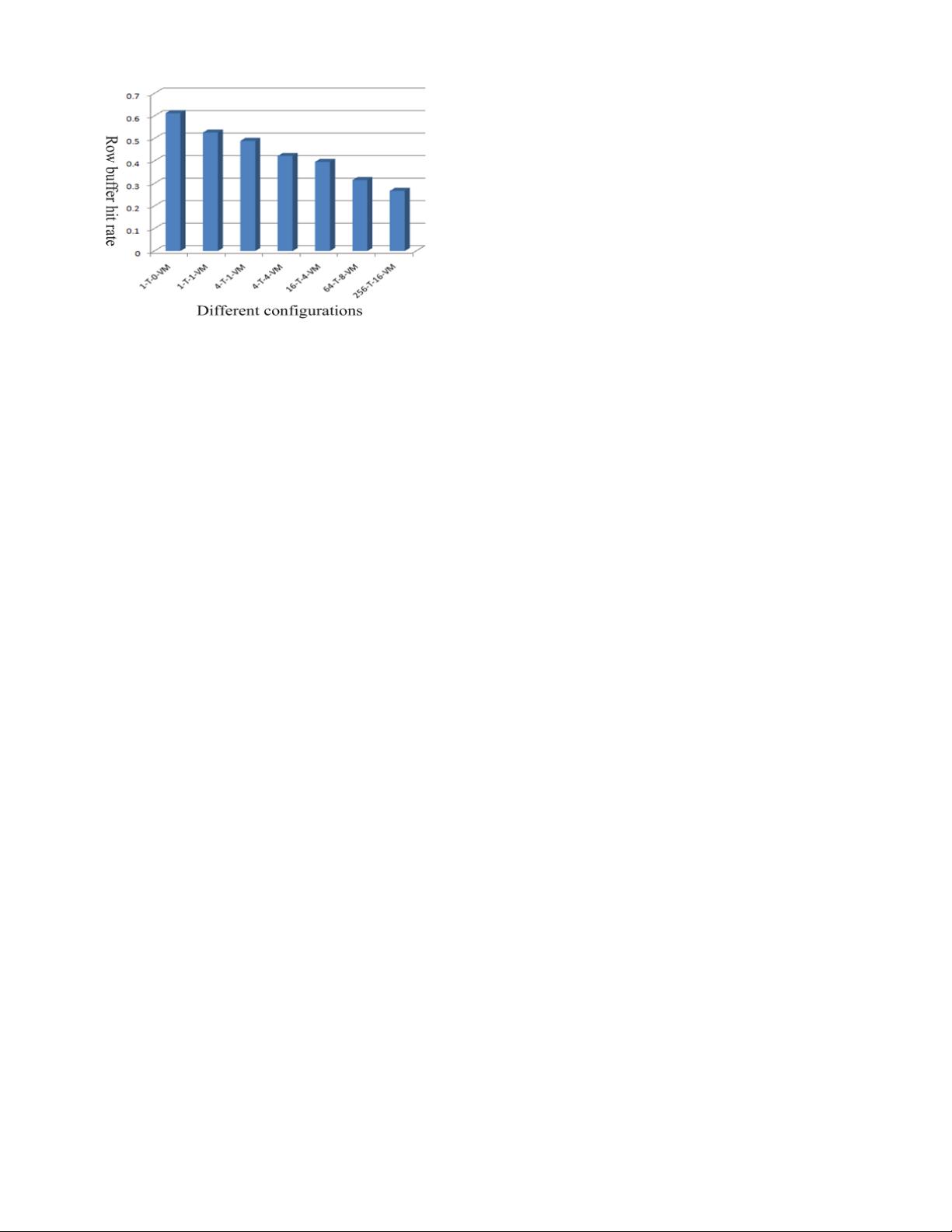
Fig. 2. row buffer hit rate under different running configurations
each time an array is accessed, an entire multi-KB row
is transferred to a row buffer. This operation is called an
“activation” or a “row opening”. Then, any column of the row
can be read/written over the channel in one burst. Because
the activation is destructive, the corresponding row eventually
needs to be “pre-charged”, that is, written back to the array.
B. Profiling of Interference
With the core number and VM number keep increasing
in the server, one of major challenges on memory system is
interference. Usually a single thread’s memory requests have
good locality and can exhibit good row buffer hit rate. But the
locality is significantly reduced in a multi-core server with
running many VMs parallel. Therefore, row buffer hit rate
decreases sharply, leading to poor overall system performance.
Figure 2 demonstrates that the row buffer hit rate decreases
significantly with the thread number and VM number in-
creased. The y-axis shows the row buffer hit rate, and the
x-axis presents the different running configurations. The n-T-
m-VM represents there is m VMs with n threads in the server,
and every VM has n/m threads.
The interference mainly derives from three aspects:
1) Hypervisor interfere VMs. The hypervisor presents the
guest operating systems with a virtual operating platform
and manages the execution of the guest operating sys-
tems. Multiple instances of a variety of operating systems
may share the virtualized hardware resources. The hy-
pervisor takes responsible for the resources management.
Therefore, VMs need to request the hypervisor to allocate
physical resources, like the memory resource, during their
lifetime. In the process of memory allocation, hypervisor
may disturb the origin memory access stream of VMs,
which is one aspect of the memory interference.
Above situation has been shown in the figure 2. 1-
T which represents one thread running on operating
system without hypervisor is better than 1-T-1-VM which
represents one thread running on one VM with hypervisor
in row buffer hit rate. The advantage is mainly from the
hypervisor interference-free.
Moreover, in order to detailed analyze the interference
effect from hypervisor, we count the proportion caused by
hypervisor to the VM row buffer misses. Figure 3 demon-
strates the VM row buffer misses proportion caused by
hypervisor in different configurations. The x-axis presents
the different benchmarks from PARSEC running on VM.
This figure has proven hypervisor contributes great row
buffer misses.
2) VM interfere applications running on it.In order to get
the service of the guest operating system (OS), applica-
tions need to invoke system calls frequently during their
lifetime. To access guest OS’s address space, applications
have to switch to the kernel state. After the service
finished, the state returns back to the user state, which is
the address space of applications originally. For a simple
system call, kernel only uses a small part of a page, while
it has to complete the above steps, which may lead to two
additional row-buffer misses. Although guest OS invoca-
tions are usually short-lived, they are invoked frequently
[18], which leads to the frequently switches between
kernel state and user, intensifying interference. Figure
4 demonstrates row buffer misses proportion caused by
guest OS to different benchmarks. In the figure, we
run different benchmarks on VM to count the misses
proportion caused by invoking system calls and other
guest OS interference. This figure has clearly shown guest
OS contributes most row buffer misses to applications.
3) Interference among VMs and threads on one VM.VMs
and threads on one VM running concurrently contend
shared memory in both CMP systems and virtual CMP
(VCMP) systems. Therefore, memory streams of different
VMs and threads are interleaved and interfere with each
other at DRAM memory and virtual memory address
space respectively. The results of figure 2 have proven
the interference among VMs and threads on one VM. 1-
T-1-VM which represents one thread running on one VM
is better than 4-T-4-VM which represents four threads
running on four VMs and each VM has one thread in row
buffer hit rate. Briefly, one VM is better than four VMs
simultaneously running in row buffer miss rate. Moreover,
as the threads number of one VM increased, such as 1-T-
1-VM, 4-T-1-VM, 64-T-8-VM and 256-T-16-VM, from
one thread to 16 threads on one VM, the row buffer
miss rate decreases seriously. Interference among VMs
and threads on one VM needs to alleviate for memory
performance improvement.
C. Profiling of Memory Sharing
Basically, memory deduplication of reducing memory re-
quirements is based on the assumption that a system has many
identical contents. However, in the virtualization, a physical
server mostly hosts multiple VMs to run simultaneously for
different services. The software as well as the data used in
VMs can be similar [19]. Therefore, through merging those
identical pages, the physical system can release additional free
pages.
Moreover, the guest OS running on each VM also have
many identical contents. Figure 5 demonstrates the identical
pages proportion between two VMs without applications run-
ning on them. In the figure, the x-axis presents the two guest
剩余11页未读,继续阅读
2021-07-18 上传
2023-09-13 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38653694
- 粉丝: 9
- 资源: 920
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
