Python网络爬虫入门实例详解
74 浏览量
更新于2024-08-31
收藏 387KB PDF 举报
本文将深入探讨Python网络爬虫实例,帮助初学者理解爬虫的基本概念和工作流程。首先,我们明确了爬虫的定义:爬虫是一种自动抓取互联网数据的程序,它在数字化信息时代扮演着重要的角色,常用于数据采集、信息挖掘等领域。
接着,文章概述了爬虫的主要框架。爬虫通常包括三个核心组件:爬虫调度器、网页下载器和网页解析器。爬虫调度器负责管理待爬取的URL列表,通过URL管理器(内存或数据库)确保避免重复和循环抓取。网页下载器,如Python的urllib库,用于获取网页内容,处理HTTP请求头和可能的登录验证。在Python3中,urllib库整合了urllib2的功能,urlopen函数是关键操作。对于复杂网页,可能需要调整请求参数以应对反爬虫策略。
网页解析器是解析网页数据的核心部分,它从抓取的HTML或XML文档中提取有用的信息。文章提到,除了正则表达式这种基于字符串的匹配方式,还推荐使用BeautifulSoup这样的高级库。BeautifulSoup利用HTML或XML的结构化特性,构建DOM树,使得数据提取更为高效和灵活,尤其适合处理具有复杂结构的网页内容。
以抓取百度百科中英雄联盟词条为例,BeautifulSoup的使用展示了如何从HTML中提取特定信息,如与其他英雄联盟相关的数据。然而,由于篇幅限制,详细的BeautifulSoup使用教程将在后续文章中深入介绍。
这篇教程为学习者提供了一个从入门到实践的Python网络爬虫基础框架,通过实际案例和工具演示,帮助读者掌握爬虫开发的基础技能。无论是对数据抓取感兴趣的专业人士还是希望学习新技能的学生,都能从中获益匪浅。
Python网络爬虫实例讲解网络爬虫实例讲解
主要为大家详细介绍了Python网络爬虫实例,爬虫的定义、主要框架等基础概念,感兴趣的小伙伴们可以参考
一下
聊一聊Python与网络爬虫。
1、爬虫的定义、爬虫的定义
爬虫:自动抓取互联网数据的程序。
2、爬虫的主要框架、爬虫的主要框架
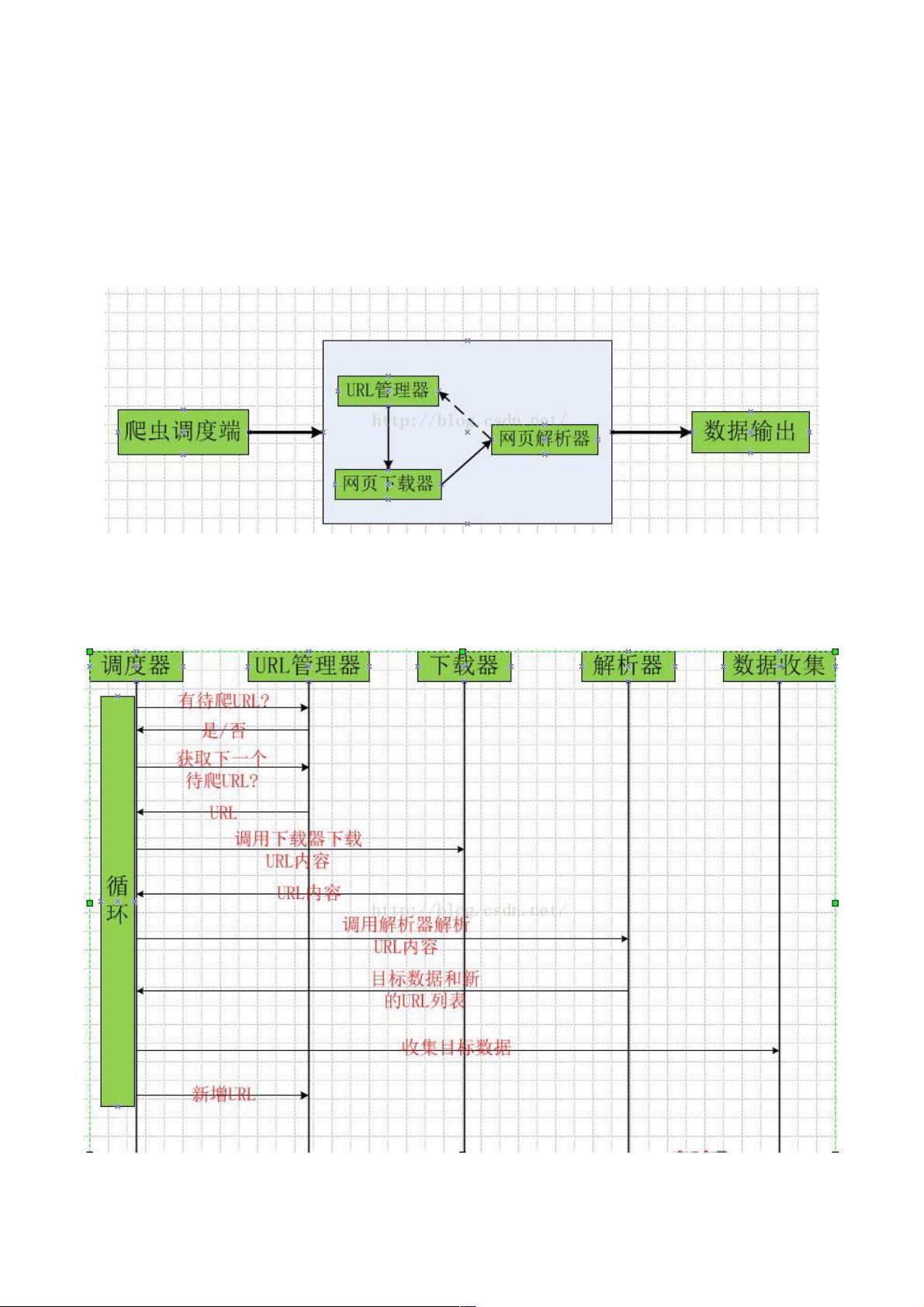
爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链
接,爬虫调度器调用网页下载器下载相应网页,然后调用网页解析器解析该网页,并将该网页中新的URL添加到URL管理器
中,将有价值的数据输出。
3、爬虫的时序图、爬虫的时序图
4、、URL管理器管理器
URL管理器管理待抓取的URL集合和已抓取的URL集合,防止重复抓取与循环抓取。URL管理器的主要职能如下图所示:
下载后可阅读完整内容,剩余3页未读,立即下载
1953 浏览量
点击了解资源详情
101 浏览量
276 浏览量
345 浏览量
2020-09-20 上传
809 浏览量
178 浏览量
224 浏览量

weixin_38592455
- 粉丝: 7
- 资源: 896
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于SSM农村信息化建设管理系统毕业设计程序
- BoardGameClock-开源
- Simple Shooter Game using JavaScript with Source Code.zip
- 永宏 FBs主机os版本下载.rar
- jfactory:轻松将应用程序模块化为可取消的组件。 他们初始化的所有内容都可以自动监控,停止和删除,包括视图,承诺链,请求,侦听器,DOM和CSS
- r2pipe_erl:Radar2的Erlang管道绑定
- p9-cli:图形的命令行语法
- UPDATEDangrybirds-
- Newton-raphson.rar_newton_newton-raphson
- 论文阅读清单
- 体育小偷 v1.8
- stm32F429使用cubemx生产usbhid进行通信
- 您的代码颜色:使用Web组件制作的Visual Studio代码主题的可视化编辑器
- Simple Math Quiz using HTMLJavaScript with Source Code.zip
- ExpenseReimbrusmentSystem2021:说明在这里
- QuickDAO:具有LinQ的简单数据访问对象库和对(Windows,Linux,OSXIOSAndroid)和freepascal(WindowsLinux)的多引擎支持
