全面理解与实践:朴素贝叶斯分类算法详解
需积分: 9 68 浏览量
更新于2024-07-16
收藏 449KB PDF 举报
朴素贝叶斯分类算法是一种基于概率统计的简单但强大的分类方法,尤其适用于文本分类等场景。这份来自巴豆大数据团队讲师的课件详细介绍了分类任务的基础概念,包括分类的定义和常见应用,如人群分类、新闻分类、网页分类以及垃圾邮件过滤等。
课程首先明确了分类任务,即根据输入对象X预测其所属类别Y,Y可以是二值分类或多值分类,且类别间可以是独立的(水平关系)或形成层级结构(层级关系)。以新闻分类为例,课程讨论了如何通过列举常用词来确定类别,但也提出了如何处理列举不全、冲突和不同词汇权重的问题,这正是朴素贝叶斯算法发挥作用的地方,它假设各个特征之间相互独立,简化了特征之间的条件依赖关系。
在实际操作中,解决新闻分类问题的流程包括特征表示(将文本转化为数值特征)、特征选择(选取对分类最有帮助的特征)、模型选择(如朴素贝叶斯),以及数据预处理(如训练数据的准备)、模型训练、预测和性能评估。朴素贝叶斯分类器利用贝叶斯定理,计算每个类别的先验概率以及给定特征条件下属于该类别的后验概率,然后选择后验概率最高的类别作为预测结果。
与朴素贝叶斯一起提到的其他分类技术还有支持向量机(SVM)和k近邻(KNN),它们分别基于空间分割和实例相似性进行分类,与朴素贝叶斯的统计概率方法有所不同。
这份资料提供了丰富的分类算法基础理论和实践应用,对于理解朴素贝叶斯在实际项目中的运用及其与其他分类技术的比较非常有帮助,是大数据分析入门者和专业人士学习分类算法的宝贵资源。
八斗大数据培训 分类算法-NB
——
八斗大数据内部资料,盗版必究
——
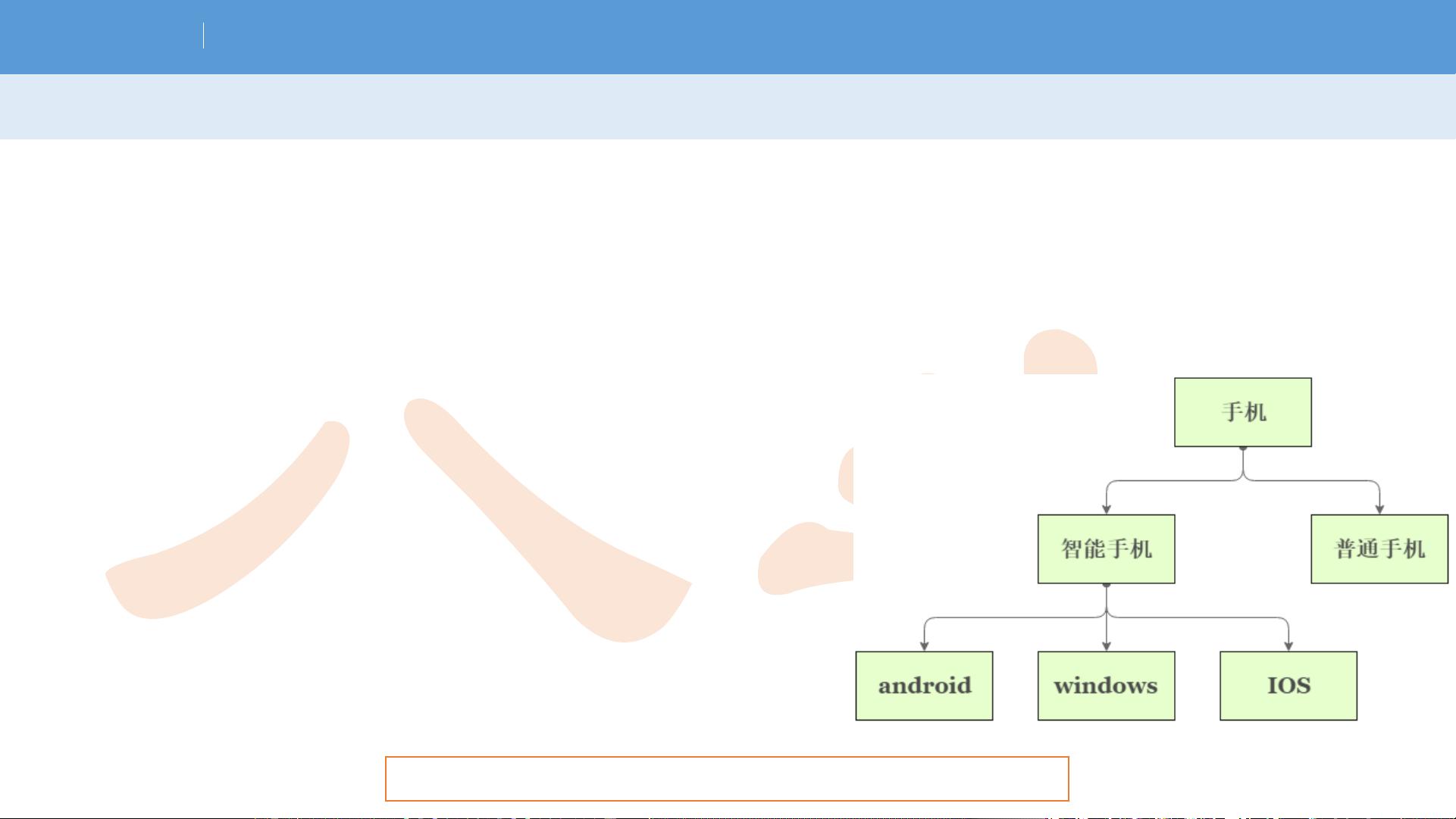
不同类型的分类
• 类别数量
– 二值分类
• Y的取值只有两种,如:email是否垃圾邮件
– 多值分类
• Y的取值大于两个,如:网页分类{政治,经济,体育,……}
• 类别关系
– 水平关系
• 类别之间无包含关系
– 层级关系
• 类别形成等级体系
剩余19页未读,继续阅读
2020-01-16 上传
2023-07-19 上传
2021-09-21 上传
2023-10-28 上传
2024-09-25 上传
2023-04-25 上传
2023-05-12 上传
2023-04-25 上传
2024-01-18 上传

一尘在心
- 粉丝: 254
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
