Spark性能优化:理解核心概念与调优策略
130 浏览量
更新于2024-08-27
收藏 241KB PDF 举报
"Spark性能调优的关键在于理解其核心概念,包括worker、executor、task、stage、CPU core的分配以及partition和parallelism的优化。在Spark集群中,每一台主机(host)可运行多个worker,每个worker又可并行运行多个executor,任务(task)在executor上执行。理解stage的概念是关键,因为shuffle操作会分割stage,影响并行性。CPU core的合理分配对提升性能至关重要,避免executor过度占用core但未充分利用的情况。
在优化过程中,应当关注executor的内存使用,过多的executor可能导致内存紧张,引发数据溢出或内存错误。调整executor数量与core分配平衡,确保CPU利用率最大化,但同时要注意内存分配的合理性。
partition是数据分片,每个task处理一个partition,过多或过少都会影响性能。如果partition数量过少,每个task处理的数据量过大,可能导致内存压力;反之,如果过多,则task创建过多,增加调度开销。parallelism是并行度,与partition紧密相关,影响reduce操作的并行性。默认的并行度可以通过`spark.default.parallelism`设置,而map操作通常不会改变partition数量。
优化策略包括:根据数据规模和计算需求适当调整executor的数量和core分配,确保executor内存充足且避免数据溢出;合理设定partition数量以平衡数据处理量和并行效率;以及通过设置`spark.default.parallelism`控制默认的并行度,提高计算效率。此外,优化数据加载和持久化策略,减少shuffle操作,也能显著提升性能。例如,使用broadcast变量减少数据传输,或利用in-memory caching加速重复计算。
最后,注意监控系统资源,如CPU、内存和网络带宽的使用情况,及时识别瓶颈并进行针对性优化。使用Spark的性能监控工具,如Spark UI和metrics系统,可以帮助分析任务执行的性能指标,进一步指导调优工作。"
以上内容详细解释了Spark性能调优的主要方面,涵盖了从基础概念到具体实践的多个层次,旨在帮助用户更好地理解和优化其Spark应用的性能。
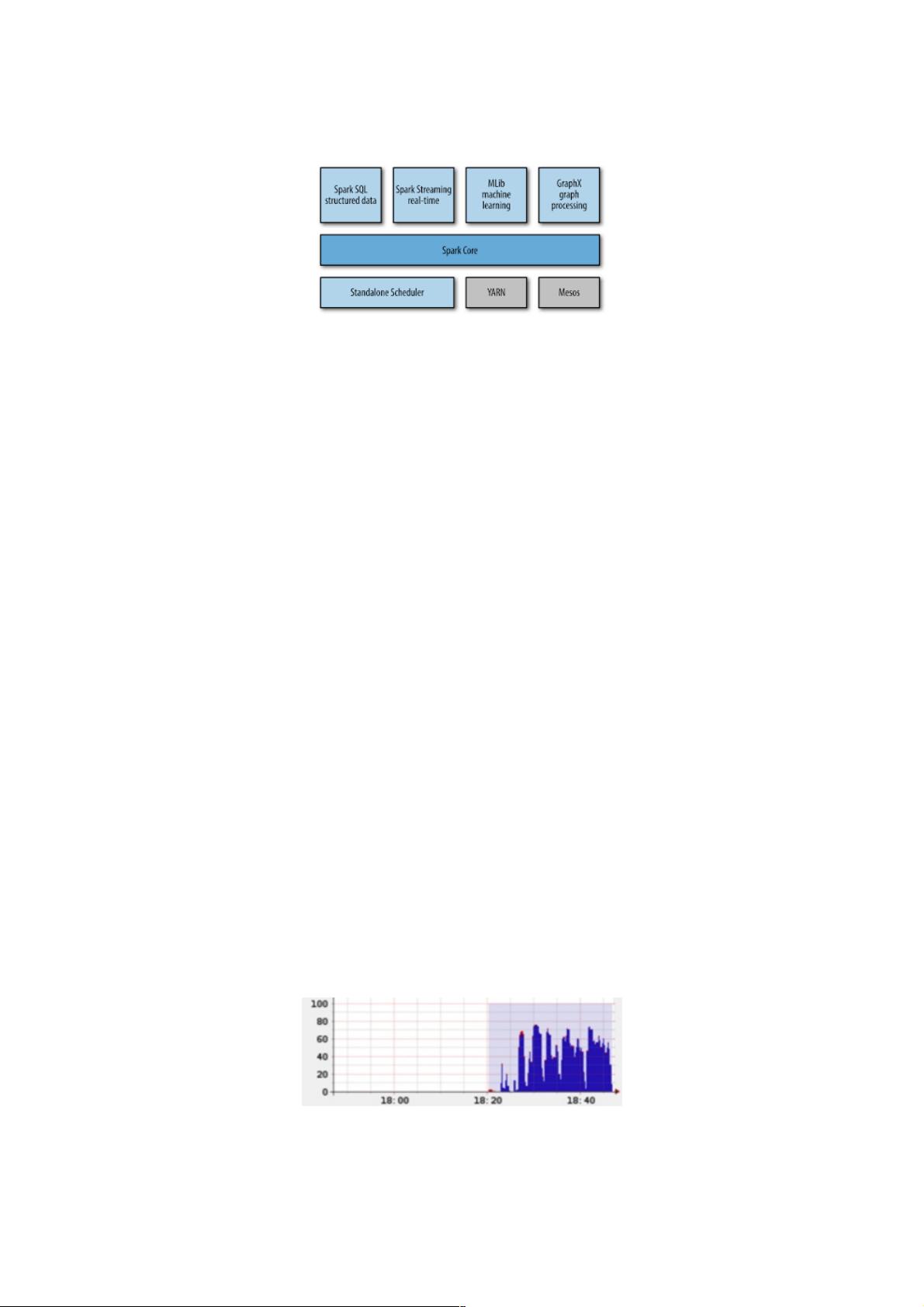
Spark的性能调优的性能调优
基本概念和原则
首先,要搞清楚Spark的几个基本概念和原则,否则系统的性能调优无从谈起:
每一台host上面可以并行N个worker,每一个worker下面可以并行M个executor,task们会被分配到executor上面去执行。
Stage指的是一组并行运行的task,stage内部是不能出现shuffle的,因为shuffle的就像篱笆一样阻止了并行task的运行,遇到
shuffle就意味着到了stage的边界。
CPU的core数量,每个executor可以占用一个或多个core,可以通过观察CPU的使用率变化来了解计算资源的使用情况,例
如,很常见的一种浪费是一个executor占用了多个core,但是总的CPU使用率却不高(因为一个executor并不总能充分利用多
核的能力),这个时候可以考虑让么个executor占用更少的core,同时worker下面增加更多的executor,或者一台host上面增
加更多的worker来增加并行执行的executor的数量,从而增加CPU利用率。但是增加executor的时候需要考虑好内存消耗,因
为一台机器的内存分配给越多的executor,每个executor的内存就越小,以致出现过多的数据spill over甚至out of memory的情
况。
partition和parallelism,partition指的就是数据分片的数量,每一次task只能处理一个partition的数据,这个值太小了会导致每
片数据量太大,导致内存压力,或者诸多executor的计算能力无法利用充分;但是如果太大了则会导致分片太多,执行效率降
低。在执行action类型操作的时候(比如各种reduce操作),partition的数量会选择parent RDD中最大的那一个。而
parallelism则指的是在RDD进行reduce类操作的时候,默认返回数据的paritition数量(而在进行map类操作的时候,partition
数量通常取自parent RDD中较大的一个,而且也不会涉及shuffle,因此这个parallelism的参数没有影响)。所以说,这两个概
念密切相关,都是涉及到数据分片的,作用方式其实是统一的。通过spark.default.parallelism可以设置默认的分片数量,而很
多RDD的操作都可以指定一个partition参数来显式控制具体的分片数量。
上面这两条原理上看起来很简单,但是却非常重要,根据硬件和任务的情况选择不同的取值。想要取一个放之四海而皆准的配
置是不现实的。看这样几个例子:
(1)实践中跑的EMR Spark job,有的特别慢,查看CPU利用率很低,我们就尝试减少每个executor占用CPU core的数量,
增加并行的executor数量,同时配合增加分片,整体上增加了CPU的利用率,加快数据处理速度。
(2)发现某job很容易发生内存溢出,我们就增大分片数量,从而减少了每片数据的规模,同时还减少并行的executor数量,
这样相同的内存资源分配给数量更少的executor,相当于增加了每个task的内存分配,这样运行速度可能慢了些,但是总比
OOM强。
(3)数据量特别少,有大量的小文件生成,就减少文件分片,没必要创建那么多task,这种情况,如果只是最原始的input比
较小,一般都能被注意到;但是,如果是在运算过程中,比如应用某个reduceBy或者某个filter以后,数据大量减少,这种低
效情况就很少被留意到。
最后再补充一点,随着参数和配置的变化,性能的瓶颈是变化的,在分析问题的时候不要忘记。例如在每台机器上部署的
executor数量增加的时候,性能一开始是增加的,同时也观察到CPU的平均使用率在增加;但是随着单台机器上的executor越
来越多,性能下降了,因为随着executor的数量增加,被分配到每个executor的内存数量减小,在内存里直接操作的越来越
少,spill over到磁盘上的数据越来越多,自然性能就变差了。
下面给这样一个直观的例子,当前总的cpu利用率并不高:
但是经过根据上述原则的的调整之后,可以显著发现cpu总利用率增加了:
下载后可阅读完整内容,剩余3页未读,立即下载
2018-09-30 上传
2017-12-29 上传
2019-03-21 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38706055
- 粉丝: 5
- 资源: 908
 我的内容管理
展开
我的内容管理
展开







最新资源
- Flex垃圾回收与内存管理:防止内存泄露
- Python编程规范与最佳实践
- EJB3入门:实战教程与核心概念详解
- Python指南v2.6简体中文版——入门教程
- ANSYS单元类型详解:从Link1到Link11
- 深度解析C语言特性与实践应用
- Gentoo Linux安装与使用全面指南
- 牛津词典txt版:信息技术领域的便捷电子书
- VC++基础教程:从入门到精通
- CTO与程序员职业规划:能力提升与路径指南
- Google开放手机联盟与Android开发教程
- 探索Android触屏界面开发:从入门到设计原则
- Ajax实战:从理论到实践
- 探索Android应用开发:从入门到精通
- LM317T稳压管详解:1.5A可调输出,过载保护
- C语言实现SOCKET文件传输简单教程
