美团技术团队分享:Spark性能调优实战与资源管理
需积分: 9 130 浏览量
更新于2024-07-19
收藏 2.71MB PDF 举报
本文档是关于Spark性能调优的详细指南,由美团技术团队整理,旨在帮助开发者理解和改进Spark应用的性能。内容分为两个主要部分:开发调优原则和资源调优。
在开发调优部分,作者列举了九个关键原则:
1. 避免创建重复的RDD,通过提供一个简单的例子来说明如何减少不必要的数据计算。
2. 尽可能复用同一个RDD,减少数据读取和计算成本。
3. 对多次使用的RDD进行持久化,介绍持久化级别的选择及其影响,并给出了代码示例。
4. 提倡使用Broadcast和map join来替代shuffle操作,降低网络通信开销。
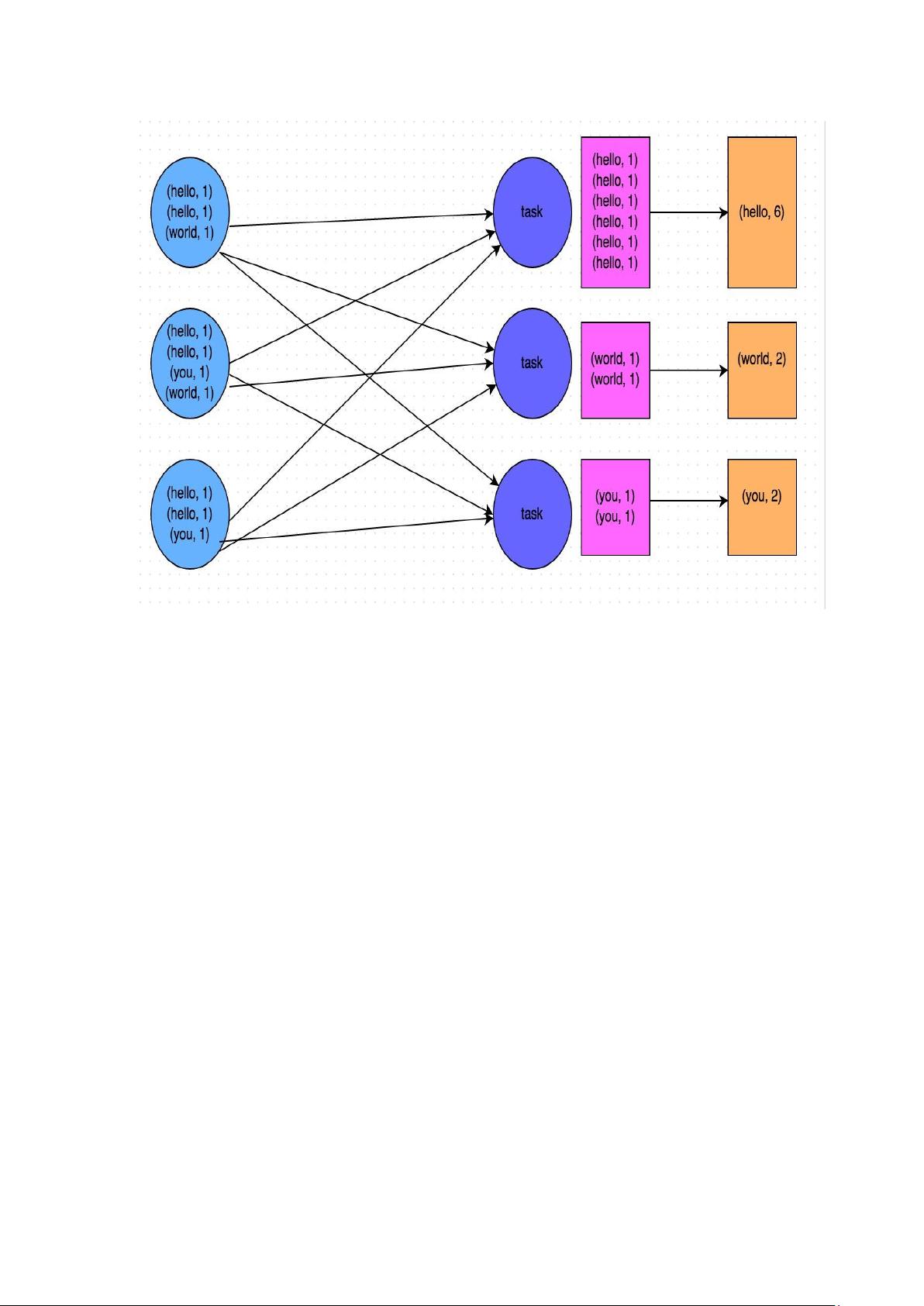
5. 强调map-side预聚合shuffle操作,提高处理效率。
6. 推荐使用高效算子,如reduceByKey和aggregateByKey代替groupByKey,以及mapPartitions和foreachPartitions等。
7. 在广播大变量时,给出代码示例并强调其在性能优化中的作用。
8. 使用Kryo进行序列化性能优化,减少内存消耗。
9. 优化数据结构,以提升数据访问速度。
资源调优部分涵盖了Spark作业的基本运行原理,包括资源参数的配置,如num-executors、executor-memory、executor-cores、driver-memory等。作者提供了这些参数的调整策略,并给出了参考示例,以确保任务的有效分布和资源的最大利用。
数据倾斜调优是另一个重要议题,它解释了数据倾斜的常见现象,即大部分任务快速执行,而少数任务耗时过长。作者分析了数据倾斜的原理,并提供方法来定位和解决代码中的问题,例如检查可能导致倾斜的代码段和优化策略。
这份文档不仅介绍了Spark性能调优的基本原则,还深入剖析了资源管理和数据倾斜的处理技巧,对于优化Spark应用程序的性能具有很高的实用价值。通过遵循这些指导,开发者可以显著提升Spark应用的执行效率和资源利用率。

因此在我们的开发过程中,能避免则尽可能避免使用 reduceByKey、
join、distinct、repartition 等会迚行 shuffle 的算子,尽量使用 map
类的非 shuffle 算子。这样的话,没有 shuffle 操作戒者仁有较少
shuffle 操作的 Spark 作业,可以大大减少性能开销。
Broadcast 与 map 进行 join 代码示例
// 传统的 join 操作会导致 shuffle 操作。
// 因为两个 RDD 中,相同的 key 都需要通过网络拉取到一个节点上,由一个 task 进行 join 操作。
val rdd3 = rdd1.join(rdd2)
// Broadcast+map 的 join 操作,不会导致 shuffle 操作。
// 使用 Broadcast 将一个数据量较小的 RDD 作为广播变量。
val rdd2Data = rdd2.collect()
val rdd2DataBroadcast = sc.broadcast(rdd2Data)
// 在 rdd1.map 算子中,可以从 rdd2DataBroadcast 中,获取 rdd2 的所有数据。
// 然后进行遍历,如果发现 rdd2 中某条数据的 key 与 rdd1 的当前数据的 key 是相同的,那么就判定
可以进行 join。
// 此时就可以根据自己需要的方式,将 rdd1 当前数据与 rdd2 中可以连接的数据,拼接在一起(String
或 Tuple)。
val rdd3 = rdd1.map(rdd2DataBroadcast...)
// 注意,以上操作,建议仅仅在 rdd2 的数据量比较少(比如几百 M,或者一两 G)的情况下使用。
// 因为每个 Executor 的内存中,都会驻留一份 rdd2 的全量数据。
1.5 原则五:使用 map-side 预聚合的 shuffle 操作
如果因为业务需要,一定要使用 shuffle 操作,无法用 map 类的算
子来替代,那举尽量使用可以 map-side 预聚合的算子。
所谓的 map-side 预聚合,说的是在每个节点本地对相同的 key 迚行
一次聚合操作,类似亍 MapReduce 中的本地 combiner。map-side
预聚合乀后,每个节点本地就叧会有一条相同的 key,因为多条相同
的 key 都被聚合起来了。其他节点在拉取所有节点上的相同 key 时,

剩余66页未读,继续阅读
2017-12-29 上传
2021-02-26 上传
2019-03-21 上传
2018-08-15 上传
2023-03-16 上传
2023-10-12 上传

cwbcom
- 粉丝: 4
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







