有赞大数据实践:Presto的高性能与应用场景解析
6 浏览量
更新于2024-08-28
收藏 167KB PDF 举报
"Presto在有赞的实践之路"
在有赞的实践中,Presto被广泛应用并经历了逐步演进的过程。Presto最初是为了解决Facebook在使用Hive进行交互式查询时遇到的高延迟问题而诞生的。与Hive相比,Presto专注于提供快速响应的查询性能,适用于需要快速获取结果的分析场景,其延迟可达到分钟级甚至亚秒级。
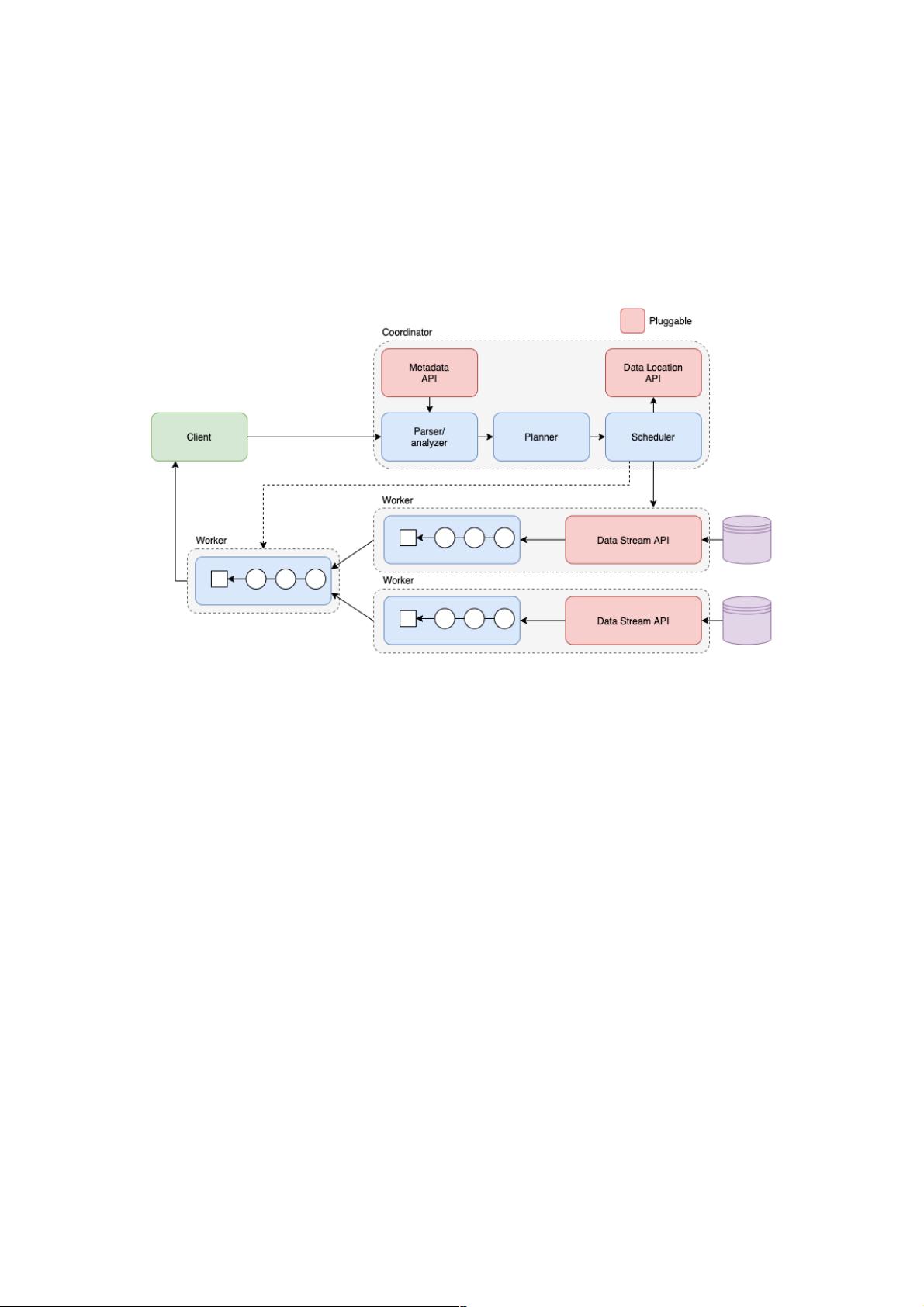
Presto的架构设计是其高性能的关键。它采用了分布式的模式,客户端(Client)向协调器(Coordinator)发送查询请求。SQL语句通过ANTLR解析器转化为抽象语法树(AST),然后通过元数据进行语义解析。解析后的数据生成逻辑执行计划,经过优化后被切割成不同的Stage,由工作节点(Worker)生成Task执行。每个Task会生成相应的物理执行计划,工作节点执行这些计划,而客户端持续从协调器获取查询结果。Presto的高性能得益于其全内存计算、查询计划优化、动态代码生成以及数据调度本地化等策略。
在有赞的使用场景中,Presto扮演了多个重要角色。首先,它作为数据平台(DP)的临时查询工具,支持探索性数据分析,并提供了数据安全措施如脱敏和审计。其次,Presto被用于商业智能(BI)报表引擎,帮助商家生成各种分析报告。此外,元数据系统利用Presto进行数据质量校验,而数据产品如CRM分析和人群画像等也依赖于Presto的计算能力。
在演进历程中,有赞最初将Presto与Hadoop集群混合部署,但遇到了性能波动的问题。当Hadoop离线任务占用大量磁盘IO带宽时,Presto的查询性能受到影响。这促使有赞对Presto的部署模式进行调整,以优化资源分配,确保更稳定、高效的查询性能。
Presto在有赞的应用展示了其在大数据环境中的灵活性和高性能优势,尤其是在交互式查询和实时分析方面。随着有赞对Presto的不断优化和改进,它已成为支撑公司数据服务的重要基础设施,满足了各种复杂业务场景的需求。
Presto在有赞的实践之路在有赞的实践之路
一、Presto 介绍
Presto 是由 Facebook 开发的开源大数据分布式高性能 SQL 查询引擎。起初,Facebook 使用 Hive 来进行交互式查询分析,
但 Hive 是基于 MapReduce 为批处理而设计的,延时很高,满足不了用户对于交互式查询想要快速出结果的场景。为了解决
Hive 并不擅长的交互式查询领域,Facebook 开发了 Presto,专门为交互式查询所设计,提供分钟级乃至亚秒级低延时的查
询性能。
1.1 Presto 架构
1.2 Presto 执行查询过程
Client 发送请求给 Coordinator。
SQL 通过 ANTLR 进行解析生成 AST。
AST 通过元数据进行语义解析。
语义解析后的数据生成逻辑执行计划,并且通过规则进行优化。
切分逻辑执行计划为不同 Stage,并调度 Worker 节点去生成 Task。
Task 生成相应物理执行计划。
调度完后根据调度结果 Coordinator 将 Stage 串联起来。
Worker 执行相应的物理执行计划。
Client 不断地向 Coordinator 拉取查询结果,Coordinator 从最终汇聚输出的 Worker 节点拉取查询结果。
1.3 Presto 为何高性能
Pipeline, 全内存计算。
SQL 查询计划规则优化。
动态代码生成技术。
数据调度本地化,注重内存开销效率,优化数据结构,Cache,非精确查询等其它技术。
二、Presto 在有赞的使用场景
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-03-18 上传
2021-01-22 上传
2021-03-21 上传
2021-02-13 上传
2022-03-18 上传
2021-06-24 上传

weixin_38550812
- 粉丝: 3
- 资源: 893
 我的内容管理
展开
我的内容管理
展开







最新资源
- BibLatex-Check:用于检查BibLatex .bib文件是否存在常见引用错误的python脚本!
- pso-csi:PSO CSI掌舵图
- 如何看懂电路图.zip
- RL-course
- javascript挑战
- spring-hibernate-criteria-builder-p6spy
- Analisis_de_Datos_Python_Santander:对应于python和santander的数据分析过程的存储库
- Pos
- 算法
- SST单片机中文教程.zip
- image
- taipan:老苹果的Unix实现][简单但令人上瘾的交易游戏,背景设定在19世纪的南海
- MM32F013x 库函数和例程.rar
- inoft_vocal_framework:使用相同的代码库创建Alexa技能,Google Actions,Samsung Bixby Capsules和Siri“技能”。 然后将您的应用程序自动部署到AWS。 所有这些都在Python中!
- imersao_dev-calculadora:在沉浸式开发的第二堂课中执行的计算器
- freecodecamp_Basic_Data_Structures
