有赞大数据实践:Presto的高性能查询与应用
176 浏览量
更新于2024-08-28
收藏 167KB PDF 举报
"Presto在有赞的实践之路"
Presto是一种由Facebook开发的开源大数据分布式SQL查询引擎,设计目标是提供低延迟的交互式查询能力,与Hive相比,Presto更适合用于需要快速响应结果的场景。Presto的高性能主要归功于其全内存计算、查询计划优化、动态代码生成以及数据调度本地化等技术。其架构分为Client、Coordinator和Worker节点,Client发起查询请求,Coordinator负责解析SQL、生成和优化执行计划,并调度Worker执行任务。
在Presto的执行流程中,首先,Client发送SQL请求给Coordinator,SQL通过ANTLR解析器转化为抽象语法树(AST)。接着,AST结合元数据进行语义解析,生成逻辑执行计划。计划经过优化后被切分成多个Stage,分配给Worker节点执行。每个Worker生成物理执行计划,执行完毕后,Coordinator负责串联Stage并返回结果给Client。
在有赞的业务场景中,Presto扮演了重要角色。它被用于数据平台的临时查询,提供快速的数据分析入口,同时具备数据脱敏和审计功能。此外,Presto也作为BI报表引擎,服务于商家的分析需求。元数据系统利用Presto进行数据质量检查,而数据产品如CRM分析和人群画像等则依赖Presto进行复杂计算。
在有赞的实践中,Presto经历了从与Hadoop混合部署到独立优化的演进过程。初期,由于与Hadoop共享资源,Presto的性能受到Hadoop离线任务的影响,表现出不稳定性。为了改善这一状况,有赞可能采取了如隔离资源、调整集群配置、优化任务调度等策略,以提升Presto的查询性能和整体稳定性。
Presto在有赞的实践中体现了其在大数据交互式查询中的优势,通过不断优化和调整,满足了公司内部对高效数据分析的需求,成为了数据服务的关键组件。
Presto在有赞的实践之路在有赞的实践之路
一、Presto 介绍
Presto 是由 Facebook 开发的开源大数据分布式高性能 SQL 查询引擎。起初,Facebook 使用 Hive 来进行交互式查询分析,
但 Hive 是基于 MapReduce 为批处理而设计的,延时很高,满足不了用户对于交互式查询想要快速出结果的场景。为了解决
Hive 并不擅长的交互式查询领域,Facebook 开发了 Presto,专门为交互式查询所设计,提供分钟级乃至亚秒级低延时的查
询性能。
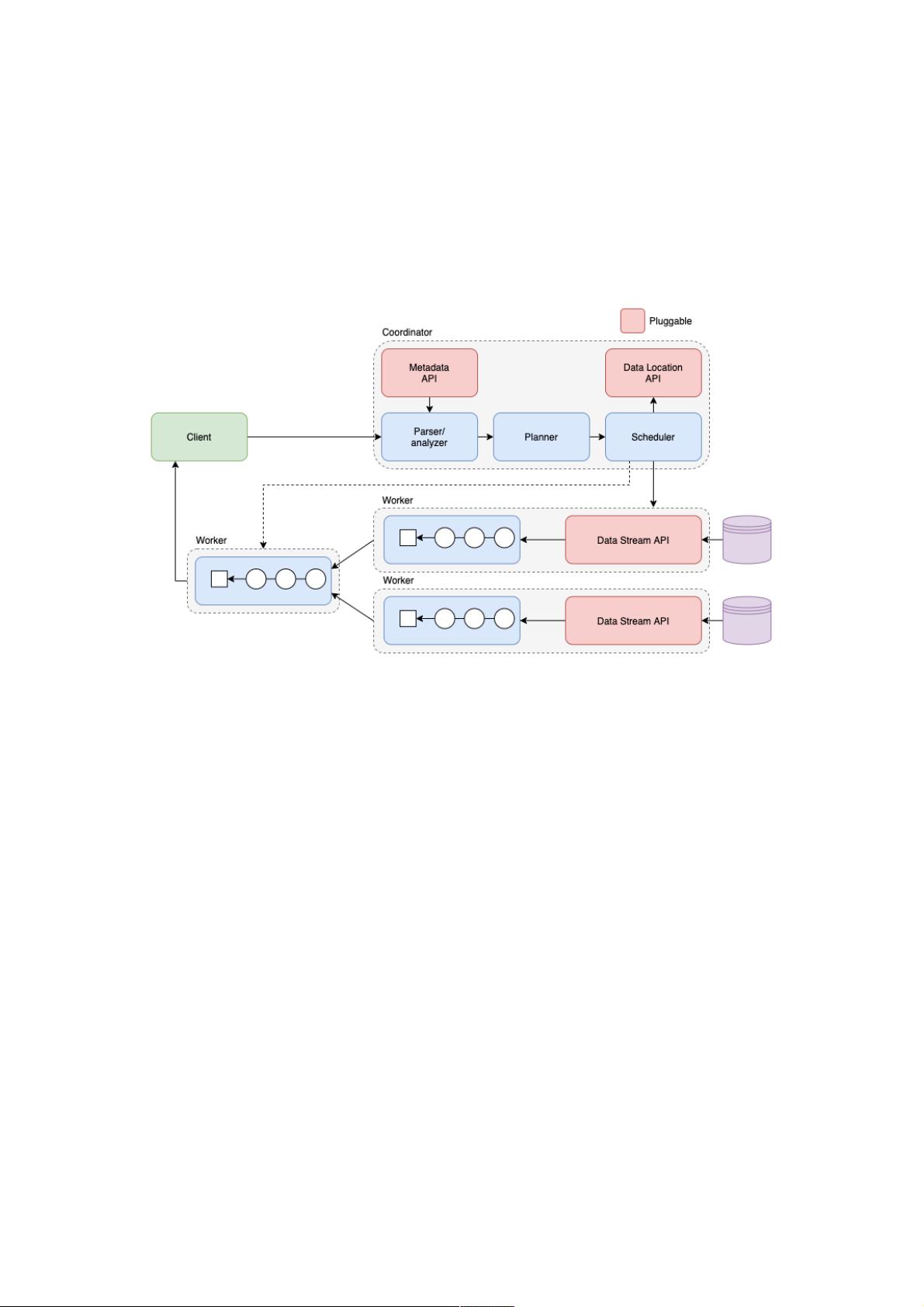
1.1 Presto 架构
1.2 Presto 执行查询过程
Client 发送请求给 Coordinator。
SQL 通过 ANTLR 进行解析生成 AST。
AST 通过元数据进行语义解析。
语义解析后的数据生成逻辑执行计划,并且通过规则进行优化。
切分逻辑执行计划为不同 Stage,并调度 Worker 节点去生成 Task。
Task 生成相应物理执行计划。
调度完后根据调度结果 Coordinator 将 Stage 串联起来。
Worker 执行相应的物理执行计划。
Client 不断地向 Coordinator 拉取查询结果,Coordinator 从最终汇聚输出的 Worker 节点拉取查询结果。
1.3 Presto 为何高性能
Pipeline, 全内存计算。
SQL 查询计划规则优化。
动态代码生成技术。
数据调度本地化,注重内存开销效率,优化数据结构,Cache,非精确查询等其它技术。
二、Presto 在有赞的使用场景
下载后可阅读完整内容,剩余3页未读,立即下载
2022-03-18 上传
2022-03-18 上传
2021-01-22 上传
2021-03-21 上传
2021-02-13 上传
2021-06-24 上传
点击了解资源详情
点击了解资源详情

weixin_38562329
- 粉丝: 1
- 资源: 949
 我的内容管理
展开
我的内容管理
展开







最新资源
- Proxy-Table-SwiftUI:SwiftUI中的HTTPS代理列表
- ThinkMachine-Advisor:使用ThinkMachine规则的GUI
- java8stream源码-MS-Translator-Speech-HoL:MS-Translator-Speech-HoL
- LiteImgResizer-开源
- 易语言图片修改大小源码.zip易语言项目例子源码下载
- java8集合源码-bookmark:书签
- ARM开发工程师入门宝典.zip
- dgsim:SyncroSim基本软件包,用于模拟野生动物种群的人口统计数据
- TicTacToe
- Gordian Knot-开源
- react-hooks-booklist-tutorial
- 读取excel文件到高级表格.zip易语言项目例子源码下载
- TSC指令大全.rar
- java版商城源码-dev-cheat-sheet:只是一个快速工具和代码片段的汇编,以启动您的开发,主要是针对Web和API。贡献是开放的!
- BounceBall:使用SFML库用C ++编写的简单游戏
- RxSwift-main.zip
