链表基础知识:单链表、双链表与循环链表解析
需积分: 9 37 浏览量
更新于2024-07-24
收藏 452KB PDF 举报
"这份资料详细介绍了链表这一重要的数据结构,包括单链表、双链表和循环链表。"
链表是一种常见的数据结构,它与数组不同,不连续存储数据元素,而是通过指针连接各个节点来表示元素之间的逻辑关系。在链表中,每个节点包含两部分:数据域和指针域。数据域用于存储数据元素,而指针域则存储相邻元素的存储位置。
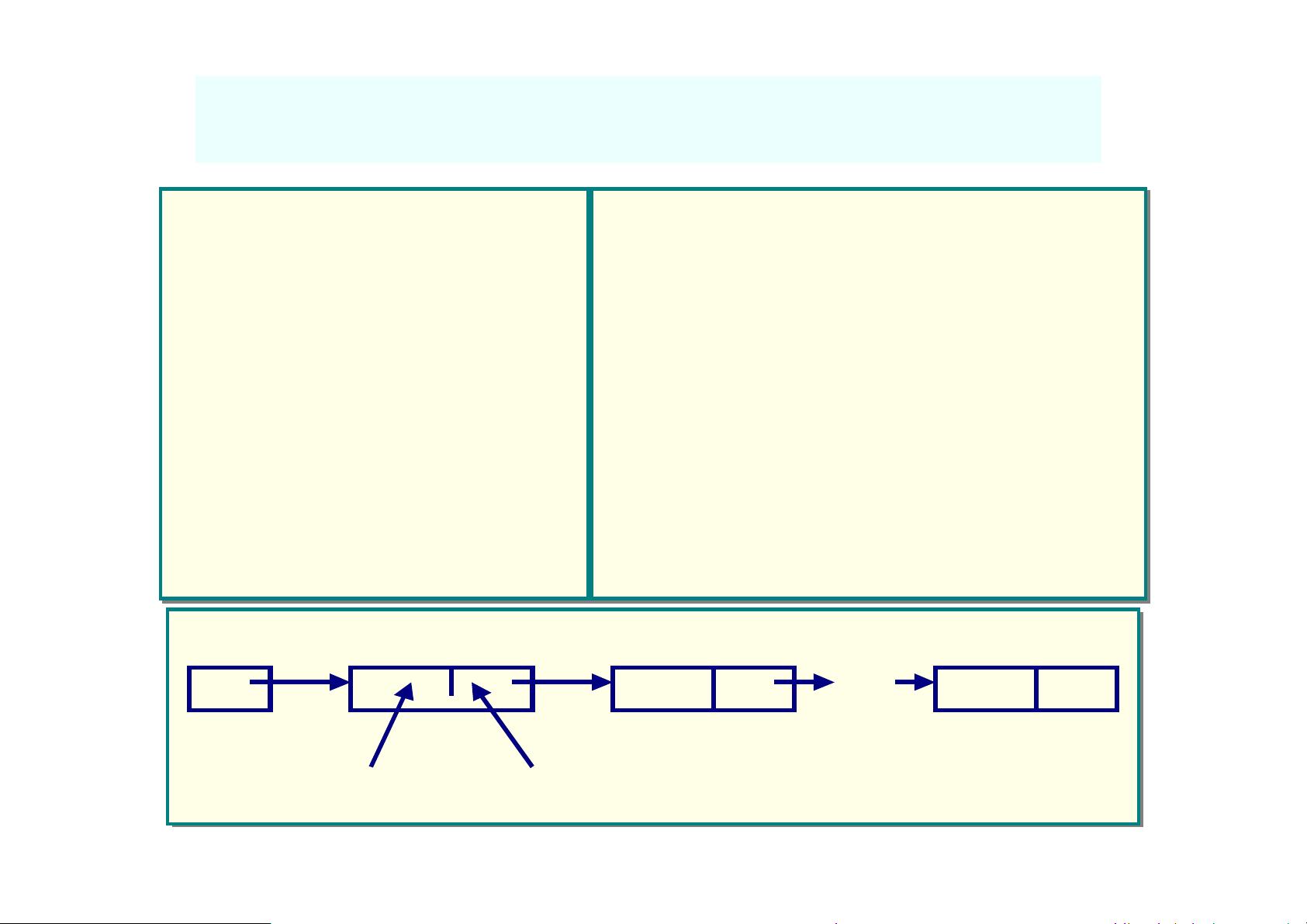
1. **单链表**:
- 单链表中的每个节点只有一个指针域,通常称为`next`,它指向当前节点的下一个节点。这种链表的插入和删除操作相对简单,因为只需要改变相邻节点的指针即可。但查找操作效率较低,因为需要从头节点开始遍历到目标节点。
```c
typedef struct LNode {
ElemType data; // 数据域
struct LNode *next; // 指针域,指向下一个节点
} LNode, *linklist; // 定义链表节点和链表指针类型
```
2. **循环链表**:
- 循环链表是单链表的一种变体,最后一个节点的`next`指针不再指向`NULL`,而是指向链表的第一个节点(头节点),形成了一个环状结构。这种链表的优点是可以方便地实现循环遍历。
3. **双链表**:
- 双链表的每个节点包含两个指针域,分别指向前后两个节点,通常称为`prev`和`next`。这种结构使得在链表中进行插入和删除操作时,不仅可以向前也可以向后移动,提高了操作效率,但增加了存储空间的需求。
```c
// 双链表的数据结构定义
typedef struct DNode {
ElemType data;
struct DNode *prev; // 指向前一个节点
struct DNode *next; // 指向后一个节点
} DNode, *dlinklist;
```
链表在实际编程中有着广泛的应用,如在文件系统、内存管理、图形算法等场景。它们提供了一种灵活的方式来组织数据,特别是在数据量不确定或者需要频繁插入和删除元素的情况下,链表相比数组有更高的效率。
总结来说,链表是一种非顺序存储结构,通过节点间的指针连接来实现元素的逻辑顺序。单链表、双链表和循环链表是其三种基本形式,各自有其特点和适用场景。掌握链表的基本操作和原理对于理解和设计高效的数据结构至关重要。
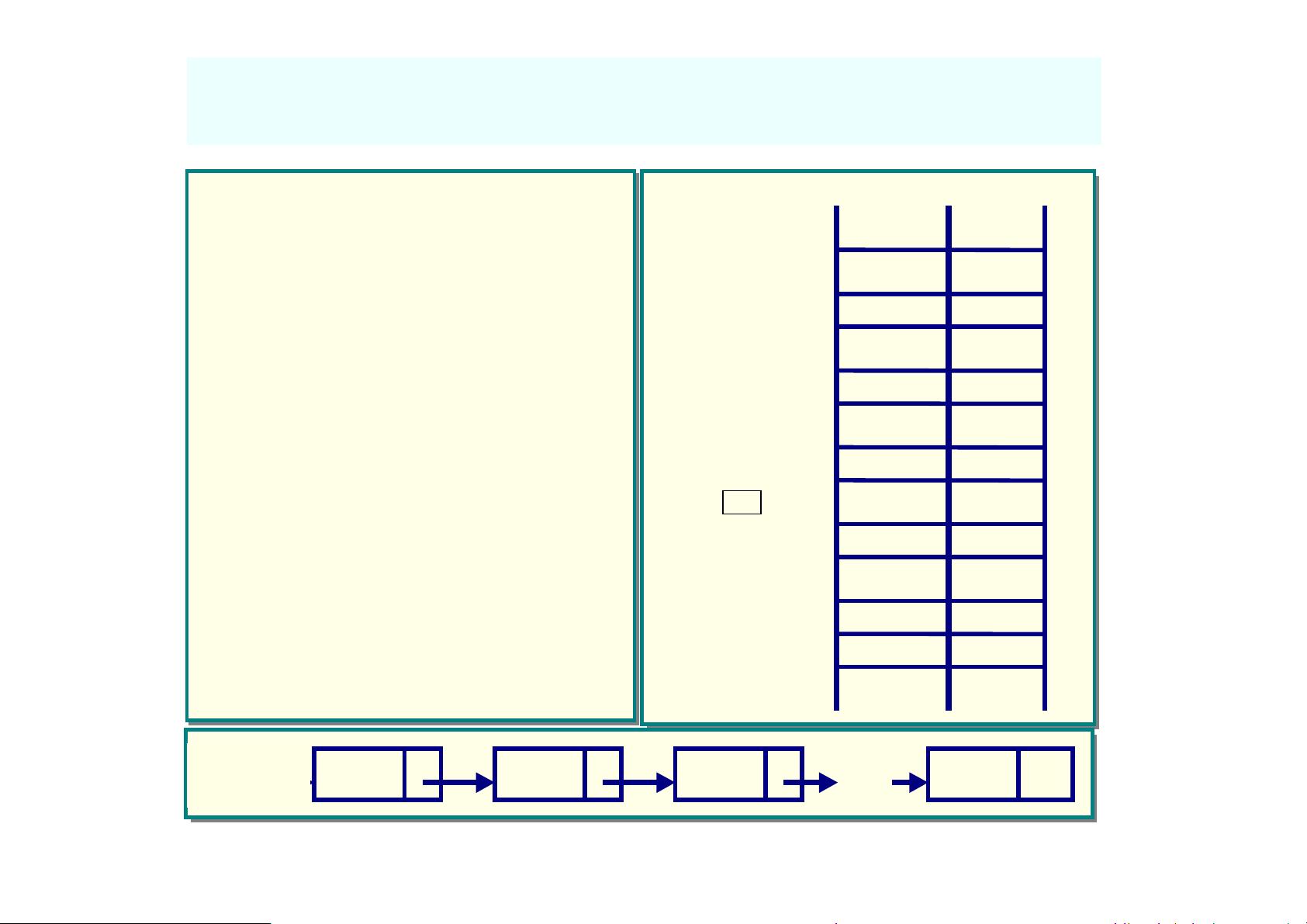
单链表
右图是线性表(
zhao, qian, sun, li,
zhou, wu, zheng,
wang)的单链表
示意图。
下图是另一种链
表的表示形式—
—称为静态链表
右图是线性表(
zhao, qian, sun, li,
zhou, wu, zheng,
wang)的单链表
示意图。
下图是另一种链
表的表示形式—
—称为静态链表
数据域
指针域
M M
110 zhou 200
M M
130 qian 135
135 sun 170
M
M
头指针
160 wang NULL
head 165 165 zhao 130
170 li 110
M M
200 wu 205
205 zheng 160
M
M
head zhao qian sun
L
wang
∧
剩余32页未读,继续阅读
2022-04-18 上传
2022-04-14 上传
2021-10-06 上传
2023-11-14 上传
2022-02-05 上传
2024-04-24 上传

zhouyundi520
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- lex and yacc
- 某公司考试题 doc 文件
- struts架构指导
- 基于Linux的信用卡授权程序的设计与实现
- javascript高级教程.pdf
- 高质量cc++编程.pdf
- ajax “煤炭子鬼”版主帮助处理后的文档
- 银行帐户管理系统需求分析
- 利用OpenSSL生成证书详解
- oracledi_getting_started入门指南
- Shell脚本调试技术
- java编程实例100
- 操作系统 考研 汤子赢
- HP-UX环境下Shell程序调试
- 单 片 机的40个实验
- 编写一个用户注册信息填写验证程序,注册信息包括用户名、密码、EMAIL地址、联系电话。要求验证联系电话中只能输入数字,EMAIL地址中需要包括“@”符号,密码域不少于6位。要求联系电话在输入过程中保证不能有非数字,而其他两个域在点击注册按钮时再进行数据检查。
