Spark核心技术:弹性分布式数据集(RDD)详解
"深入浅出 Spark"
Spark 是一种先进的大数据处理框架,它的核心特性在于引入了弹性分布式数据集(RDD,Resilient Distributed Datasets),这是一种创新的内存计算抽象,旨在提升集群计算的效率和容错能力。RDD设计的目标是解决MapReduce等传统数据流模型在处理特定类型应用时的效率问题,特别是对于迭代式算法和交互式数据挖掘场景。
RDD 的主要特点包括:
1. **只读性和容错性**:RDD 是不可变的,意味着一旦创建,就不能被修改。这种设计简化了错误恢复机制,因为RDD可以通过其依赖关系历史来重建。如果某个计算节点失败,Spark可以重新执行失败任务所依赖的RDD转换,从而恢复数据。
2. **批处理操作**:RDD 只能通过批处理操作(如 map、filter 和 reduce)从其他RDD衍生出来,这保证了计算的可预测性和可优化性。这样的设计允许Spark在内存中高效地处理数据,减少磁盘I/O,显著提高性能。
3. **迭代计算优化**:对于需要多次迭代的算法,如机器学习和图处理,Spark的RDD可以在内存中保留中间结果,避免了重复计算,极大地提高了速度。与Hadoop MapReduce相比,Spark在迭代计算中表现出显著的性能优势。
4. **交互式查询**:由于数据可以驻留在内存中,Spark 还支持快速的交互式查询。用户可以迅速地对TB级别的数据进行分析,响应时间通常在几秒钟内,提供了类似SQL的工作体验。
5. **编程模型**:Spark 提供了一个简单易用的API,使得开发者能够方便地构建复杂的数据处理任务,支持多种编程语言,如Scala、Java、Python和R。
6. **位置感知调度**:Spark 自动考虑数据的位置,将计算任务调度到数据所在的节点,减少了数据传输的开销,进一步提升了性能。
7. **容错机制**:通过血统(Lineage)机制,Spark 能够跟踪每个RDD的创建过程,当数据丢失时,可以从源数据或前一个RDD恢复,实现容错。
8. **扩展性**:Spark 可以在各种集群管理器上运行,如YARN、Mesos或者独立模式,具有良好的可扩展性,能够适应不同规模的集群环境。
Spark 的这些特性使其成为大数据处理领域的热门选择,特别是在需要高效迭代计算和快速交互式查询的场景下。通过RDD这一强大的抽象,Spark成功地平衡了计算效率、容错性和易用性,为大数据分析带来了革命性的提升。
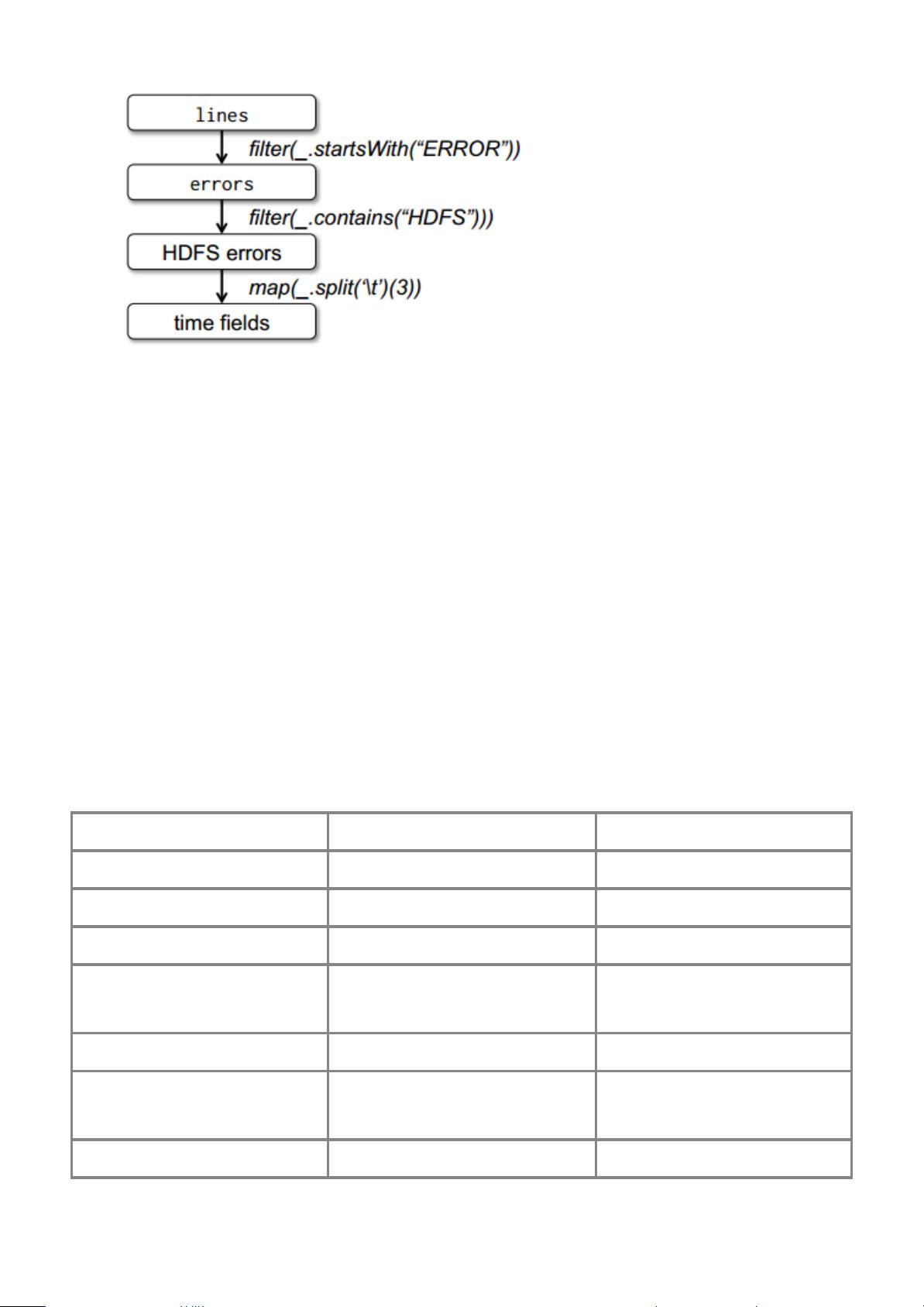
图1示例中第三个查询的Lineage图。(方框表示RDD,箭头表示转换)
2.5RDD与分布式共享内存
为了进一步理解RDD是一种分布式的内存抽象,表1列出了RDD与分布式共享内存(DSM,
DistributedSharedMemory)[24]的对比。在DSM系统中,应用可以向全局地址空间的任意
位置进行读写操作。(注意这里的DSM,不仅指传统的共享内存系统,还包括那些通过分布式哈
希表或分布式文件系统进行数据共享的系统,比如Piccolo[28])DSM是一种通用的抽象,但这
种通用性同时也使得在商用集群上实现有效的容错性更加困难。
RDD与DSM主要区别在于,不仅可以通过批量转换创建(即“写”)RDD,还可以对任意内存位
置读写。也就是说,RDD限制应用执行批量写操作,这样有利于实现有效的容错。特别地,RDD
没有检查点开销,因为可以使用Lineage来恢复RDD。而且,失效时只需要重新计算丢失的那些
RDD分区,可以在不同节点上并行执行,而不需要回滚整个程序。
表1RDD与DSM对比
对比项目 RDD 分布式共享内存(DSM)
读 批量或细粒度操作 细粒度操作
写 批量转换操作 细粒度操作
一致性 不重要(RDD是不可更改的) 取决于应用程序或运行时
容错性 细粒度,低开销(使用
Lineage)
需要检查点操作和程序回滚
落后任务的处理 任务备份 很难处理
任务安排 基于数据存放的位置自动实现 取决于应用程序(通过运行时
实现透明性)
如果内存不够 与已有的数据流系统类似 性能较差(交换?)
注意,通过备份任务的拷贝,RDD还可以处理落后任务(即运行很慢的节点),这点与
MapReduce[12]类似。而DSM则难以实现备份任务,因为任务及其副本都需要读写同一个内存
剩余25页未读,继续阅读
2021-03-31 上传
2018-01-05 上传
294 浏览量
2014-05-29 上传
2021-09-18 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

xjl219
- 粉丝: 0
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 教你怎么写批处理.txt
- C语言 描述 数据采集 程序
- Oracle9i 数据库管理基础 I Ed 1.1 Vol.1
- intel平台的ELF 文件格式
- High.Performance.MySQL_Second.Edition.pdf
- 基于_NET企业信息资源管理系统的设计与实现
- Linux操作系统编程入门
- Ethereal用户手册.pdf
- 基于UDP通信协议的设计与实现
- 红外遥控系统原理及单片机软件解码实例
- 三言两语话Erlang
- java编程入门知识
- NET SQL Server数据访问抽象基础类
- linux 菜鸟过关
- Android 入门教程
- Oracle+9i&10g编程艺术:深入数据库体系结构
