Python实现回归树详解:CART算法与实战应用
143 浏览量
更新于2024-09-01
收藏 219KB PDF 举报
本文将详细介绍如何在Python中实现回归树模型,特别是基于CART(Classification and Regression Trees)算法的实例。回归树是一种基于树结构的预测模型,常用于解决回归问题,它通过构建决策树对输入特征进行分割,最终每个叶子节点表示一个预测值。与分类树不同,回归树的叶子节点不是类别,而是连续的数值,这个值通常是该节点样本的平均值,误差则是样本的均方差。
CART算法的核心在于每次选择特征时,无论特征是离散还是连续,都进行二分划分。对于回归问题,CART算法不使用Gini指数作为选择特征的标准,因为它与均方差损失函数不兼容。在回归树中,叶子节点的预测值基于样本均值,而非类别众数,这使得回归树的实现相对简单,尤其是在没有类别边界优化需求时。
接下来,我们将使用Python的scikit-learn库中的波士顿房价预测数据集进行实战演示。这个数据集包含13个特征,用于预测房屋的价格。在实际操作中,需要预处理数据,如加载数据、编码特征、处理缺失值等。通过加载`load_boston()`函数获取数据后,我们将展示如何构建回归树模型,包括特征选择、模型拟合以及预测房价的过程。
在实践中,首先导入必要的库,如`numpy`、`pandas`和`sklearn`,然后加载波士顿房价数据集。接着,我们将数据分为特征矩阵`X`和目标变量`y`,并可能对数据进行预处理和特征工程。具体步骤可能包括数据标准化、特征缩放,以及根据数据特性选择合适的回归树模型参数(如最大深度、最小样本叶节点大小等)。
通过sklearn的`DecisionTreeRegressor`类,我们可以创建回归树模型并进行训练:
```python
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树回归器
regr = DecisionTreeRegressor()
# 拟合模型
regr.fit(X_train, y_train)
# 进行预测
y_pred = regr.predict(X_test)
```
总结,本文通过详细的步骤指导读者如何使用Python和scikit-learn实现回归树模型,包括理论背景、CART算法原理,以及实际应用中的数据加载、模型构建和预测过程。理解并掌握这些内容,将有助于在实际项目中有效地应用回归树进行预测分析。
带你学习带你学习Python如何实现回归树模型如何实现回归树模型
主要介绍了Python如何实现回归树模型,文中讲解非常细致,帮助大家更好的理解和学习,感兴趣的朋友可以
了解下
所谓的回归树模型其实就是用树形模型来解决回归问题用树形模型来解决回归问题,树模型当中最经典的自然还是决策树模型,它也是几乎所有树模型的
基础。虽然基本结构都是使用决策树,但是根据预测方法的不同也可以分为两种。第一种,树上的叶子节点就对应一个预测树上的叶子节点就对应一个预测
值值和分类树对应,这一种方法称为回归树。第二种,树上的叶子节点对应一个线性模型树上的叶子节点对应一个线性模型,最后的结果由线性模型给出。这一种
方法称为模型树。
今天我们先来看看其中的回归树。
回归树模型回归树模型
CART算法的核心精髓就是我们每次选择特征对数据进行拆分的时候,永远对数据集进行二分永远对数据集进行二分。无论是离散特征还是连续性特
征,一视同仁。CART还有一个特点是使用GINI指数而不是信息增益或者是信息增益比来选择拆分的特征,但是在回归问题当
中用不到这个。因为回归问题的损失函数是均方差,而不是交叉熵,很难用熵来衡量连续值的准确度。
在分类树当中,我们一个叶子节点代表一个类别的预测值,这个类别的值是落到这个叶子节点当中训练样本的类别的众数,也
就是出现频率最高的类别。在回归树当中,叶子节点对应的自然就是一个连续值。这个连续值是落到这个节点的训练样本的均是落到这个节点的训练样本的均
值值,它的误差就是这些样本的均方差。
另外,之前我们在选择特征的划分阈值的时候,对阈值的选择进行了优化,只选择了那些会引起预测类别变化的阈值。但是在
回归问题当中,由于预测值是一个浮点数,所以这个优化也不存在了。整体上来说,其实回归树的实现难度比分类树是更低
的。
实战实战
我们首先来加载数据,我们这次使用的是scikit-learn库当中经典的波士顿房价预测波士顿房价预测的数据。关于房价预测,kaggle当中也有一
个类似的比赛,叫做:house-prices-advanced-regression-techniques。不过给出的特征更多,并且存在缺失等情况,需要我
们进行大量的特征工程。感兴趣的同学可以自行研究一下。
首先,我们来获取数据,由于sklearn库当中已经有数据了,我们可以直接调用api获取,非常简单:
import numpy as np
import pandas as pd
from sklearn.datasets import load_boston
boston = load_boston()
X, y = boston.data, boston.target
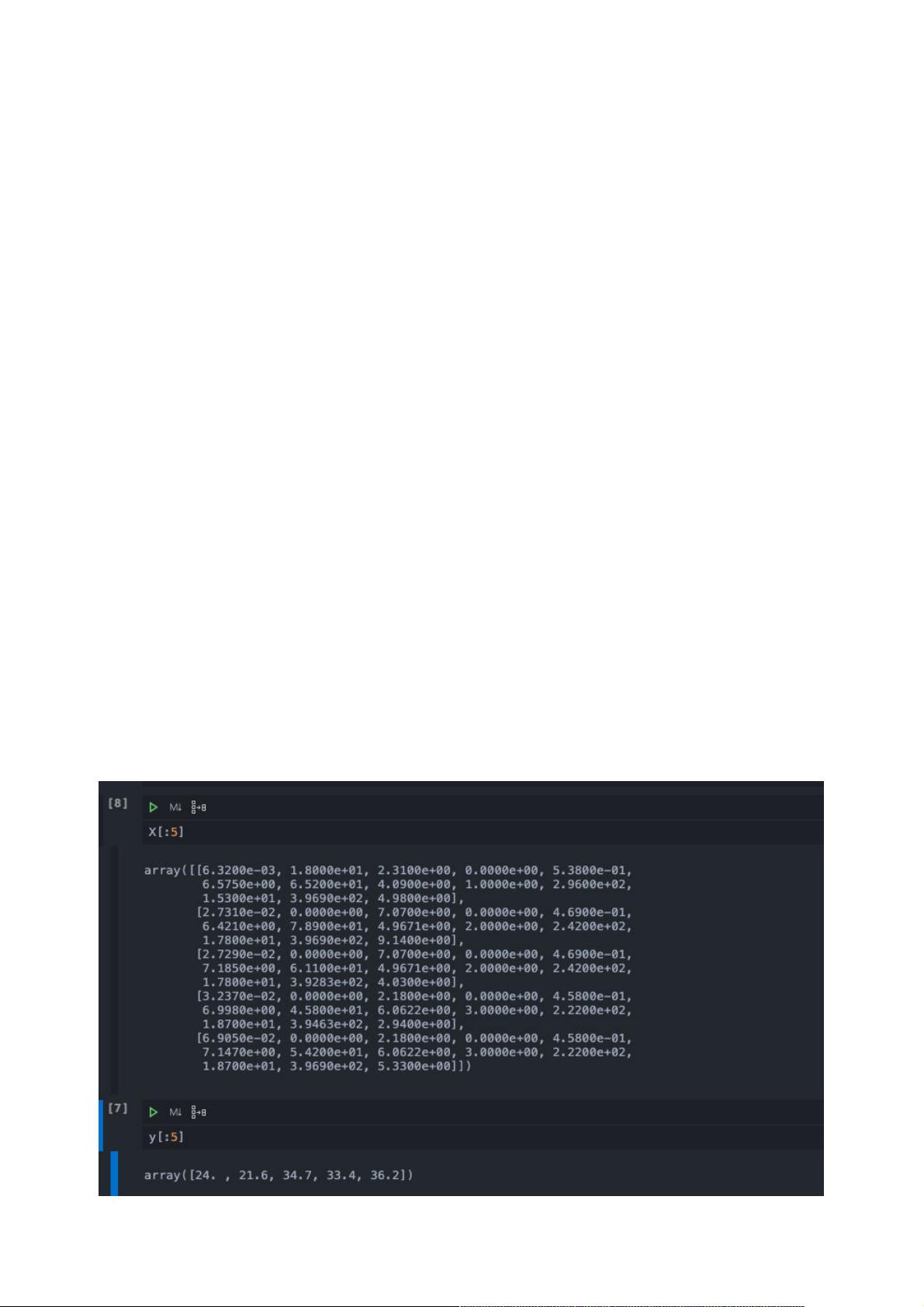
我们输出前几条数据查看一下:
这个数据质量很高,sklearn库已经替我们做完了数据筛选与特征工程替我们做完了数据筛选与特征工程,直接拿来用就可以了。为了方便我们传递数据,我们
将X和y合并在一起。由于y是一维的数组形式是不能和二维的X合并的,所以我们需要先对y进行reshape之后再进行合并。
下载后可阅读完整内容,剩余4页未读,立即下载
2020-11-30 上传
2021-07-06 上传
2023-12-27 上传
2023-07-26 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38609128
- 粉丝: 7
- 资源: 906
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
