现代RDMA网络下的数据库高可用性重新思考
版权申诉
117 浏览量
更新于2024-08-13
收藏 690KB PDF 举报
"这篇PDF论文探讨了在使用RDMA(远程直接内存访问)网络的背景下重新思考数据库高可用性的问题。作者包括Erfan Zamanian、Xiangyao Yu、Michael Stonebraker和Tim Kraska,分别来自布朗大学和麻省理工学院。他们提出,传统的主动-被动和主动-主动复制算法在网络性能是主要瓶颈的时代设计,但随着新一代高吞吐量、低延迟网络(如RDMA网络)的出现,这种假设需要重新评估。"
正文:
随着技术的发展,数据库系统的高可用性已经成为关键问题,尤其是在处理机器故障时。传统的数据复制方法,如主动-被动和主动-主动复制策略,都是在假设网络是性能瓶颈的情况下设计的。这些方法主要关注减少副本间的网络通信,以换取更多的处理冗余,这在分布式数据库设计的传统智慧中是有道理的。
然而,《Rethinking Database High Availability with RDMA Networks》论文指出,随着RDMA网络的出现,这一情况发生了变化。RDMA允许数据直接在内存之间传输,减少了CPU的干预,因此现在CPU可能成为新的性能瓶颈。现有的网络优化复制技术在这样的环境下不再是最优选择。
论文提出了“Active-Memory Replication”(活动内存复制)作为一种新的高可用性方案,它旨在利用RDMA网络的优势,减少CPU的负载,并优化数据复制过程。这种方法可能更有效地适应现代网络环境,提供更高的数据可用性和系统性能。
在高可用性数据库系统中,快速的数据恢复和一致性保证是至关重要的。传统的复制技术可能在处理大量数据传输和快速故障切换时面临挑战,而RDMA网络的低延迟特性为这些问题提供了可能的解决方案。通过将内存访问的责任转移到网络,Active-Memory Replication可能会降低系统延迟,提高吞吐量,同时保持数据的一致性。
此外,论文还可能讨论了如何在RDMA网络中实现Active-Memory Replication的具体技术细节,如如何协调多个副本,如何处理网络故障,以及如何在不增加过多复杂性的情况下确保数据安全性。这些内容对于理解如何在现代数据中心环境中构建高效且可靠的数据库系统至关重要。
这篇论文挑战了传统观念,指出在RDMA网络环境下,数据库高可用性的实现需要对现有复制策略进行根本性的反思。通过引入Active-Memory Replication,作者提供了一种新的思路,以适应网络技术的进步,进一步推动数据库系统性能的提升。
P1
B1
P2
B2
Exec%T1
Commit
Exec%T2%(A)
Exec%T2%(B)
Commit
Commit
Exec%T1
Commit
Exec%T2%(B)
Exec%T2%(A)
Commit
Commit
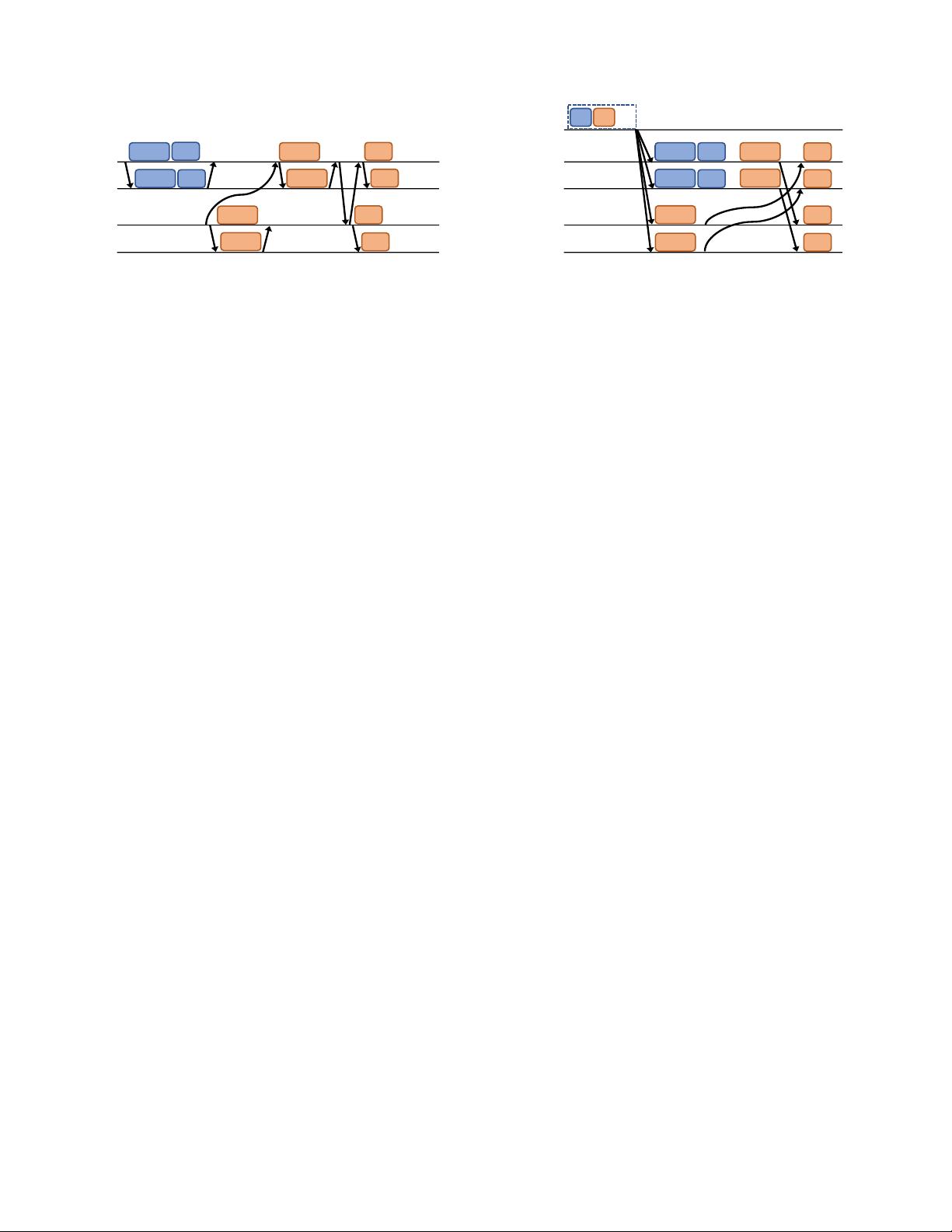
Figure 2: Active-active replication in H-store/VoltDB
all replicas of the database in the same deterministic order, such
that all the replicas end up with identical states once the batch is
executed. Replicas in an active-active database only coordinate to
determine the batches, but do not coordinate during the execution
of transactions, which significantly reduces the network traffic be-
tween replicas. Two prominent examples of databases which use
active-active replication are H-store [16] (and its commercial suc-
cessor VoltDB [35]) and Calvin [37].
H-Store’s replication protocol is illustrated in Figure 2. In H-
Store, all transactions have to be registered in advance as stored
procedures. The system is optimized to execute each transaction
from the beginning to completion with minimum overhead. In H-
Store, transactions do not get record locks, and instead only lock
the partition they need. Transactions are executed in each parti-
tion sequentially, without getting pre-empted by other concurrent
transactions. For a single-partition transaction such as T 1, the pri-
mary replicates the ID of the invoked stored procedure along with
its parameters to all its backup replicas. All replicas, including the
primary, start executing the transaction code in parallel. Unlike in
log shipping, here the replicas do not need to coordinate, as they ex-
ecute the same sequence of transactions and make deterministic de-
cisions (commit or abort) for each transaction. For multi-partition
transactions, one of the primaries acts as the transaction coordina-
tor and sends the stored procedure and its parameters to the other
participating partitions. At each partition, an exclusive lock is ac-
quired, so that no other transaction is allowed to be executed on that
partition. Each partition sends the stored procedure to all its backup
replicas so they run the same transaction and build their write-set.
Finally, the coordinator initiates a 2PC to ensure that all the other
primaries are able to commit. H-Store performs extremely well if
the workload consists of mostly single-partition transactions. How-
ever, its performance quickly degrades in the presence of multi-
partition transactions, since all participating partitions are blocked
for the entire duration of such transactions.
Calvin [37] is another active-active system that takes a differ-
ent approach than H-Store to enforce determinism in execution and
replication (Figure 3). All transactions first arrive at the sequencer
which orders all the incoming transactions in one single serial his-
tory. The inputs of the transactions are logged and replicated to all
the replicas. Then, a single lock manager thread in each partition
scans the serial history generated by the sequencer and acquires all
the locks for each transaction, if possible. If the lock is already
held, the transaction has to be queued for that lock. Therefore,
Calvin requires that the read-set and write-set of transactions are
known upfront, so that the lock manager would know what locks
to get before even executing the transaction (This assumption may
be too strict for a large category of workloads, where the set of
records that a transaction is read or modified is known throughout
executing the transaction). Those transactions which all their locks
are acquired by the lock manager are then executed by the worker
Sequencer
P1
B1
P2
Sequencing
B2
!"
!#
…
$%&'(!"()*+
$%&'(!"()*+
$%&'(!#(),+
$%&'(!#(),+
$%&'(!#()*+
$%&'(!#()*+
-.//01
-.//01
-.//01
-.//01
-.//01
-.//01
Figure 3: Active-active replication in Calvin
threads in each replica without any coordination between replicas.
For multi-partition transactions, the participating partitions com-
municate their results to each other in a push-based manner (instead
of pull-based, which is common in the other execution schemes).
Compared to Calvin with its sequencing overhead, H-store has
a much lower overhead for single-partitioned transactions. Calvin,
on the other hand, benefits from its global sequencing for multi-
partition transactions.
3. THE CASE FOR REPLICATION WITH
RDMA NETWORKS
With the fast advancement of network technologies, conventional
log-shipping and active-active schemes are no longer the best fits.
In this section, we revisit the design trade-offs that conventional
schemes made and demonstrate why the next-generation networks
call for a new design of high availability protocol in Section 3.1.
We then provide some background on RDMA in Section 3.2.
3.1 Bottleneck Analysis
The replication schemes described in the previous section were
designed in a time that network communication was the obvious
bottleneck in a distributed main-memory data store by a large mar-
gin. Reducing the need for accessing the network was therefore a
common principle in designing efficient algorithms. Both classes
of techniques approach this design principle by exchanging high
network demand with more processing redundancy, each to a dif-
ferent degree. This idea is illustrated in Figure 4a. In log ship-
ping, the logs have to be replayed at each replica, which may not
be much cheaper than redoing the transaction itself for some work-
loads. Active-active techniques reduce the need for network com-
munication even further and thus improve performance when the
network is the bottleneck but impose even more redundancy for
computation.
In these networks, communication during replication is consid-
ered expensive mainly due to three factors. (1) Limited bandwidth
of these networks would be easily saturated and become the bottle-
neck. (2) The message processing overhead by the operating sys-
tem proved to be substantial [3], especially in the context of many
OLTP workloads which contain simple transactions that read and
modify only a few records. (3) High latency of network communi-
cation increases the transaction latency, contributing to contention
and therefore impacts throughput.
With the emergence of the next-generation of RDMA-enabled
networks, such as InfiniBand, these assumptions need to be re-
evaluated. (1) Network bandwidth has increased significantly, and
its increase rate does not seem to be slowing down [13]. For exam-
ple, a Mellanox ConnectX-4 EDR card offers 100× bandwidth of a
typical 1Gb/sec Ethernet found in many public cluster offerings (in-
cluding our own private cluster). (2) The RDMA feature open new
1639
剩余13页未读,继续阅读
2020-02-21 上传
2023-08-26 上传
2021-05-09 上传
2019-05-10 上传
2020-05-21 上传
2021-08-22 上传
2021-08-23 上传
2021-08-15 上传

工控老马
- 粉丝: 699
- 资源: 2561
 我的内容管理
展开
我的内容管理
展开







最新资源
- ubuntu从入门到精通--请您把一块硬盘想象为一本书……即便您不喜欢读书,您也一定非
- 基于单片机的电子密码锁
- 多功能数字抢答器(数字电路)
- SOA Using Java Web Services.pdf
- IT面试 技巧 大全
- SQL考试资料/微软认证
- clementine教程 与实例应用方面的讲解
- excel VBA 编程指南
- C ++程序设计语言——详解源码
- Expert one on one Oracle
- MATLAB命令大全
- sun-jsp-2.0.pdf
- 最小生成树PRIM算法
- KRUSKAL算法(排序有问题饿)
- THE MYTHICAL MAN-MONTH 人月神话
- EDA综合设计的典型三个实例
